What Is Decoder-Only Architecture and How Autoregressive LLMs Generate Text Token by Token

Table of Contents
ELI5
A decoder-only architecture is a neural network that generates text by predicting one token at a time, reading only what came before—never peeking ahead—using just the output half of the original Transformer.
In 2017, the Transformer arrived as a symmetrical machine: an encoder to compress input, a decoder to generate output. Within two years, the encoder was gone. Every frontier LLM you interact with today—GPT, Claude, Llama, Gemini—runs on the half that survived. The question worth asking isn’t what the decoder does. It’s why deleting half the architecture produced the most capable language models ever built.
The Half That Won
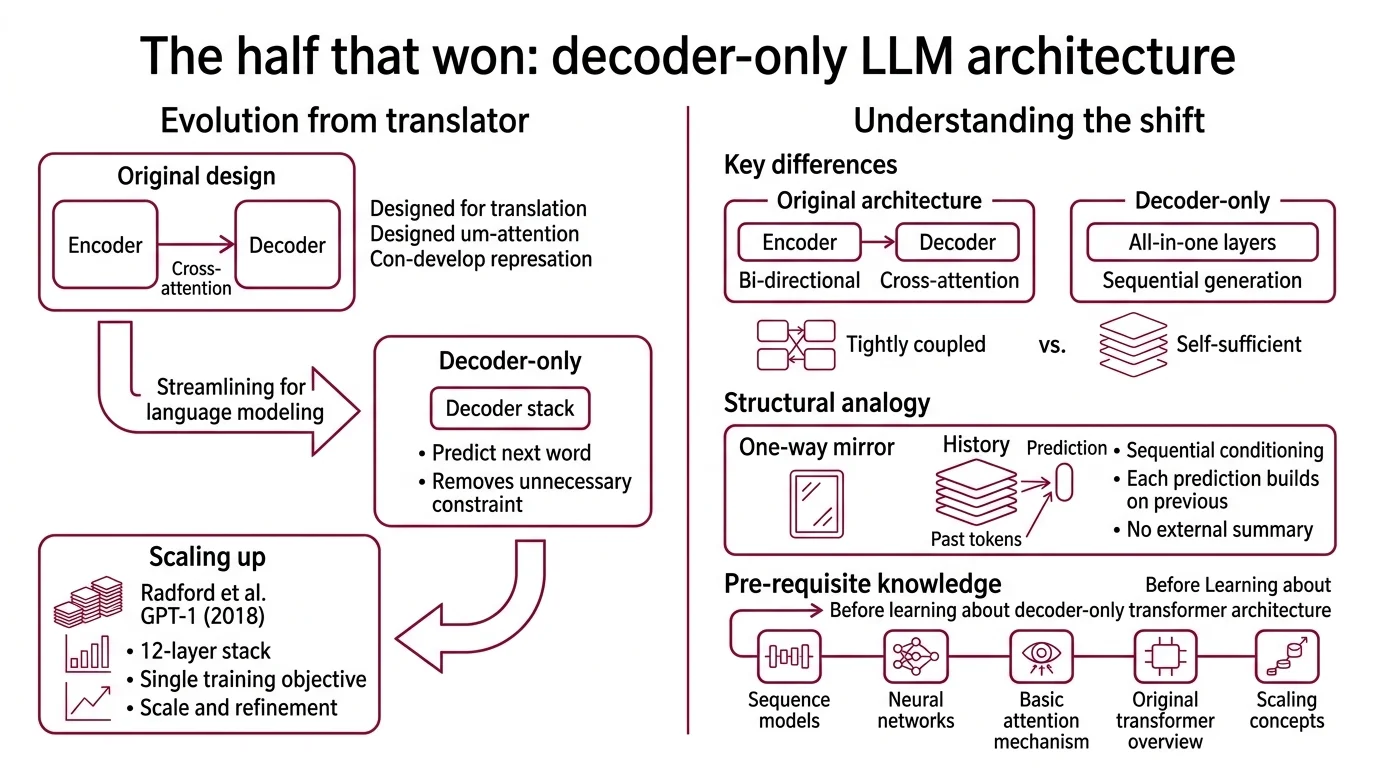
The original Transformer Architecture was designed for translation: read a sentence in French (encoder), produce a sentence in English (decoder). Two distinct modules, tightly coupled through cross-attention (Vaswani et al.). But language modeling—predicting the next word given all previous words—doesn’t need the encoder at all. The decoder, on its own, already handles sequential generation. Removing the encoder didn’t cripple the machine; it removed a constraint that was never necessary for the task.
What is decoder-only architecture in large language models?
A decoder-only architecture is a Transformer variant that retains only the decoder stack from the original Encoder Decoder Architecture design. It processes input and generates output through the same set of layers—there is no separate encoder module and no cross-attention mechanism connecting two halves.
GPT-1, introduced by Radford et al. in 2018, was the first large-scale decoder-only transformer: a 12-layer stack trained with a single objective—predict the next token (Radford et al.). That design choice turned out to be sufficient. The same architecture, scaled by orders of magnitude and refined with techniques like Mixture Of Experts routing, now powers nearly every frontier model (HuggingFace LLM Course).
The structural analogy is a one-way mirror. In an encoder-decoder system, the encoder builds a compressed representation of the input, and the decoder reads that representation while also attending to its own output history. In a decoder-only system, every token attends only to the tokens that preceded it. No external summary. No bidirectional context. Just sequential conditioning—each prediction built on the stack of everything that came before.
Not a limitation. A design choice that scales.
What do I need to understand before learning about decoder-only transformer architecture?
The decoder-only architecture sits at an intersection of several foundational ideas. Without them, the mechanism won’t make full sense:
- Attention Mechanism — the core operation where each token computes relevance scores against other tokens to decide what information to carry forward.
- Next Token Prediction — the training objective. Every decoder-only model learns by predicting the next token given all previous tokens. The loss function is cross-entropy over the vocabulary distribution.
- KV Cache — the inference optimization that stores previously computed key-value pairs so the model doesn’t recompute them at each generation step.
- Scaling Laws — the empirical relationships between model size, data volume, and performance that explain why decoder-only architectures dominate at scale.
These aren’t background reading. They are the mechanical parts. Understanding the decoder-only architecture without them is like studying an engine while ignoring combustion.
Probability, One Token at a Time
Autoregression is the process that makes a decoder-only model generative rather than merely analytical. It is also the reason these models can produce arbitrarily long outputs from a fixed-size architecture—and the reason they sometimes produce confident nonsense.
How does a decoder-only transformer generate text one token at a time?
The generation process is a loop with one rule: condition on every preceding token, then predict the next.
At each step, the model takes the full sequence of preceding tokens, passes them through every layer of the decoder stack—self-attention, feed-forward network (typically expanding the embedding dimension by 4x, then projecting back down), layer normalization—and produces a probability distribution over the entire vocabulary. The token with the highest probability (or a sample from the distribution, depending on the decoding strategy) gets appended to the sequence. Then the loop repeats.
This is next-token prediction at inference time. The same objective used during training becomes the generation mechanism.
Think of it as a river that only flows downstream. Each new token is a tributary joining the main channel; it changes the current for everything that follows, but it cannot alter the water that already passed. The model has no mechanism to revise a token it already emitted—no backtracking, no editing, no second thoughts. What’s written is written.
The implications of this constraint are non-obvious. Because each token depends on every preceding token, the quality of early tokens disproportionately affects everything downstream. A poorly chosen word in position five can steer the probability distribution for the next several hundred tokens into a region the model cannot easily escape.
Not randomness. Compounding conditional probability.
The Three Constraints Inside Every Forward Pass
The decoder-only architecture enforces its sequential logic through three interlocking mechanisms. Remove any one of them, and the autoregressive property breaks.
What are causal masking, KV cache, and next-token prediction in decoder-only models?
Causal masking is the enforcement mechanism. During self-attention, each token should only attend to tokens at earlier positions—never to tokens that haven’t been generated yet. The implementation is a lower-triangular matrix applied before the softmax operation: future positions are set to negative infinity, which zeroes their attention weights after softmax (HuggingFace LLM Course). Without this mask, the model could look at the answer it’s supposed to predict during training.
The mask is what makes the architecture autoregressive rather than bidirectional. It is also what distinguishes a decoder-only model from BERT-style encoders, which attend in both directions simultaneously.
The KV cache solves an efficiency problem that would otherwise make autoregressive generation impractical. At each generation step, the model needs key and value vectors from all previous tokens to compute attention. Without caching, the model would recompute these vectors from scratch at every step—quadratic cost in sequence length. The KV cache stores previously computed key-value pairs so each new token only requires computing its own representations and attending to the cached history. Benchmarks show approximately 5.2x faster inference on a T4 GPU with KV caching enabled (HuggingFace Blog), though real-world speedups vary with hardware and sequence length.
The trade-off is memory. For a model the size of PaLM (540B parameters), with batch size 512 and context length 2048, the KV cache alone consumes roughly 3 TB of memory (Vector Institute). The cache is the bottleneck, not the computation—and this is why context window extensions remain an active engineering challenge.
Next-token prediction is both the training objective and the inference procedure. During training, the model sees a sequence of tokens and learns to minimize cross-entropy loss between its predicted distribution and the actual next token at each position. During inference, the same forward pass produces a probability distribution, and the selected token extends the sequence for the next iteration.
These three mechanisms—the mask that enforces causality, the cache that makes generation fast, the objective that defines what “correct” means—are not independent features. They are the same architectural idea expressed at three different layers: structure, optimization, and learning.
What the Architecture Forces You to Accept
The decoder-only design encodes a specific set of trade-offs into every model that uses it. Understanding these trade-offs converts passive knowledge into engineering intuition.
If you increase context length, expect KV cache memory to grow linearly with sequence length (and quadratically with attention computation, absent optimizations like FlashAttention). Modern variants—RoPE for positional encoding, SwiGLU for activation functions, GQA for grouped query attention, RMSNorm for faster normalization—address specific bottlenecks without changing the fundamental architecture (Cameron R. Wolfe). Llama, for instance, replaced absolute positional embeddings with RoPE and swapped ReLU for SwiGLU, but the generation loop remains: one token, conditioned on all predecessors, masked against all successors.
If you want bidirectional understanding—the kind needed for tasks like named entity recognition or sentence classification—a decoder-only model is structurally disadvantaged. The causal mask prevents tokens from attending to future context, which means the model must infer right-side context from left-side patterns alone. Encoder-based architectures handle these tasks more naturally, though the decoder-only approach compensates through sheer scale and instruction tuning.
Rule of thumb: If your task requires generating sequential output—text, code, structured data—decoder-only is the architecture. If your task requires deep bidirectional understanding of a fixed input, you’re fighting the causal mask.
When it breaks: The autoregressive constraint means errors compound. A hallucinated fact in the early output shifts the probability distribution for all subsequent tokens, and the model has no built-in mechanism to detect or correct the drift. Long-form generation is where this failure mode is most visible—the model maintains local coherence while diverging globally.
The Data Says
The decoder-only architecture won not because it was the most elegant design, but because it was the most compatible with scale. One training objective, one generation mechanism, one direction of information flow—and the scaling laws did the rest. As of March 2026, nearly every frontier model—GPT, Claude, Llama, Gemini, DeepSeek—uses this architecture. The encoder was not defeated. It was made redundant by brute conditional probability.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors