What Is Data Preprocessing and How Cleaning, Scaling, and Encoding Turn Raw Data into Training Sets
ELI5
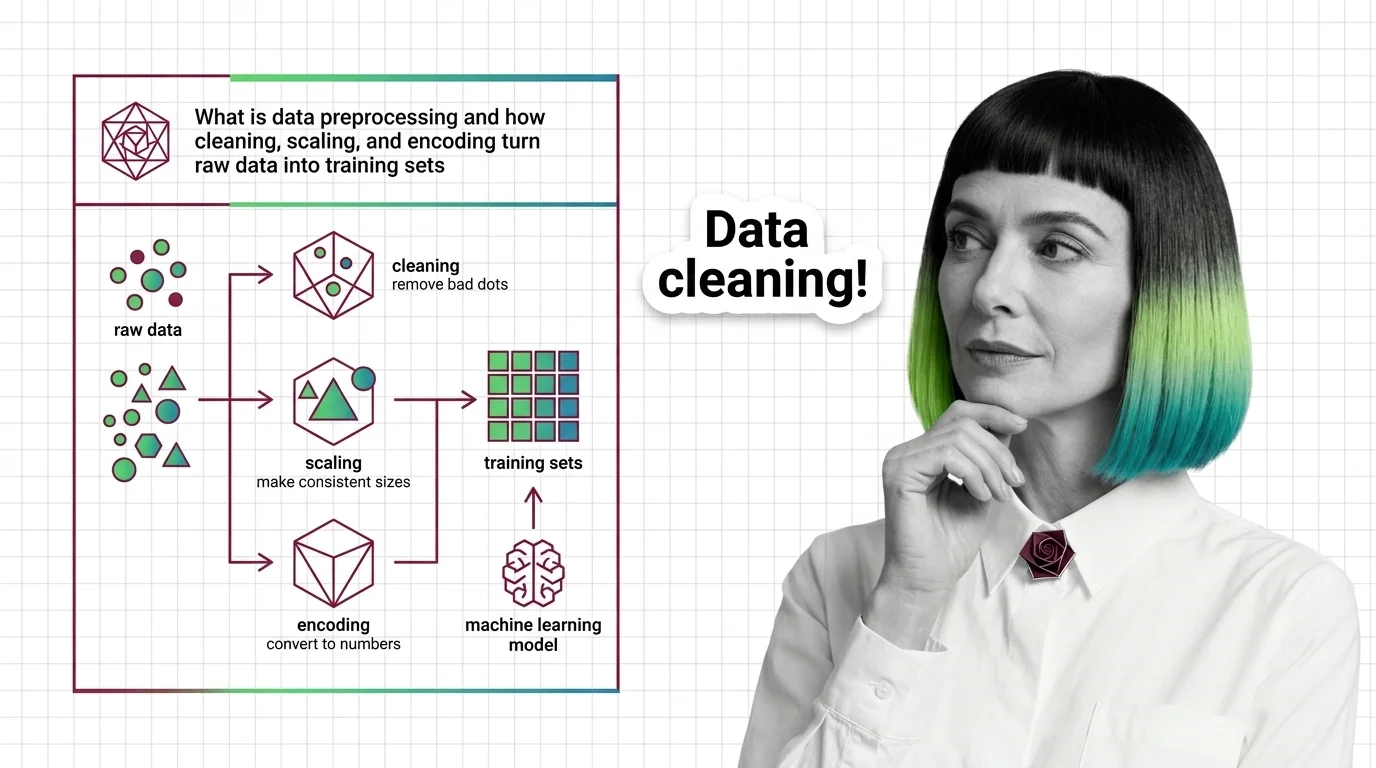
Data preprocessing turns messy raw data — missing values, text labels, wildly different units — into clean numeric arrays a model can actually learn from. Cleaning, scaling, and encoding are the three core moves.
Take two models with the same architecture, the same hyperparameters, the same training data. One converges to high accuracy. The other stalls near random guessing and never recovers. The code that differs between them is four lines long, and not one of those lines touches the model. They touch the data on the way in. This is the part of machine learning that gets the least attention and decides the most: whether the numbers you hand the model carry the signal you think they do — or whether they carry the same signal wearing the wrong units.
The Numbers Lie Before the Model Ever Sees Them
A model does not perceive a dataset the way you do. You see a spreadsheet: customer ages, account balances, city names, a few blank cells where someone forgot to fill a field. The model sees a matrix of floating-point numbers and a loss function it is trying to minimize. Everything in between — the blanks, the text, the fact that balance ranges from 0 to 200,000 while age ranges from 18 to 90 — is your problem to solve before training begins.
That solving is Data Preprocessing.
What is data preprocessing in machine learning?
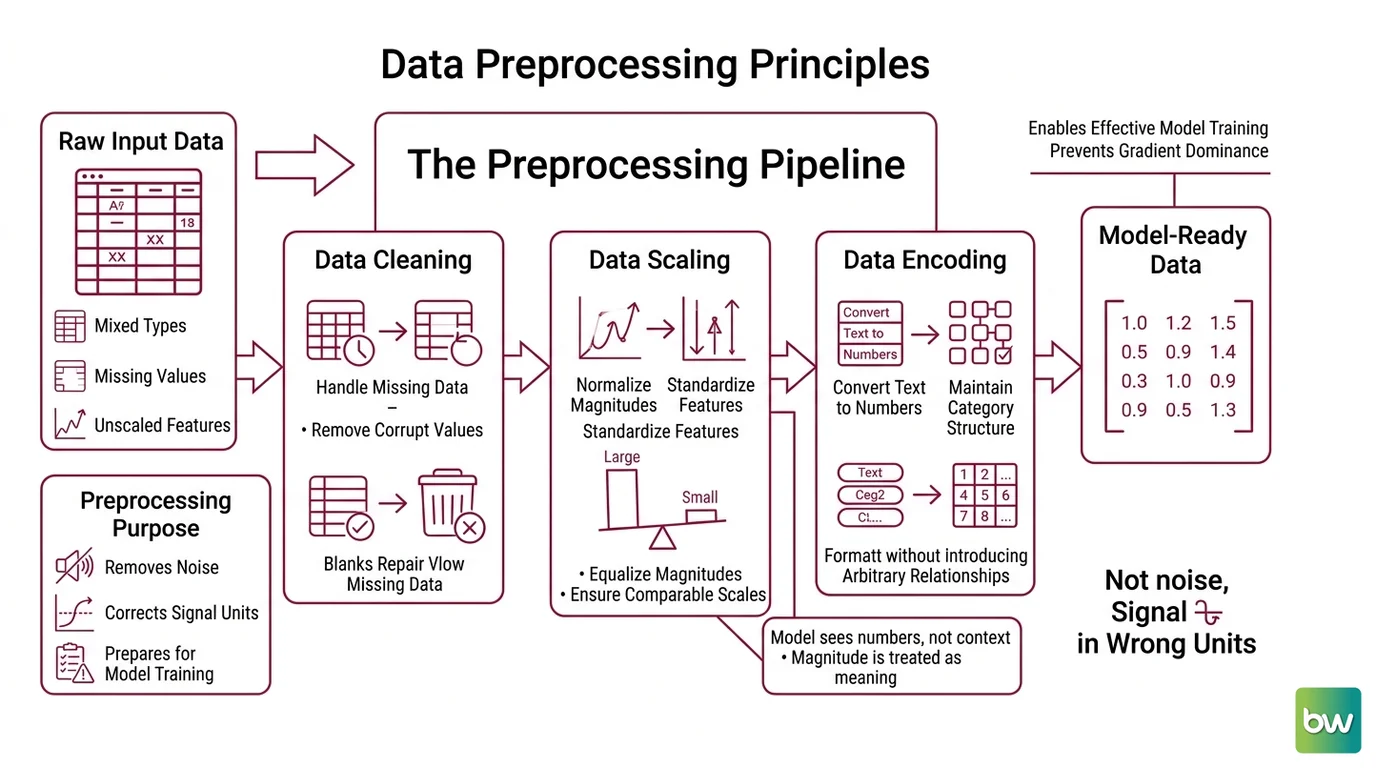
Preprocessing is the set of transformations that convert raw, heterogeneous data into a clean numeric representation suitable for a learning algorithm. It sits between data collection and model training, and it does three things that matter: it removes or repairs corrupted and missing values, it puts numeric features onto comparable scales, and it converts non-numeric information into numbers without inventing structure that was not there.
The reason this is not optional comes down to how most algorithms compute. Gradient descent, distance metrics, and dot products all treat magnitude as meaning. A feature that ranges into the hundreds of thousands will dominate the gradient simply because it is large, not because it is important. The model has no way to know that a balance of 200,000 and an age of 90 are measured in different things. To the optimizer, both are just numbers, and the bigger number shouts louder.
Not noise. Signal in the wrong units.
From Raw Rows to Model-Ready Arrays
The transformation from a raw table to a training set is not one operation. It is a short pipeline of distinct moves, each correcting a specific way that real-world data fails to match the assumptions a model makes. Cleaning handles what is missing or wrong. Scaling handles incompatible magnitudes. Encoding handles information that is not numeric at all.
How does data preprocessing transform raw data into model-ready features?
Start with the gaps. Real datasets have holes — sensors drop readings, users skip fields, joins fail to match. Missing Data Imputation fills those holes with a defensible estimate: the column mean or median for numeric features, the most frequent category for categorical ones, or a model-based guess for harder cases. The alternative — dropping every row with a missing value — quietly discards data and can bias what remains, because rows with missing values are rarely missing at random.
Then the scaling.
Standardization centers a feature to zero mean and rescales it to unit variance — the behavior implemented by StandardScaler in scikit-learn, where fit learns the mean and standard deviation from the data and transform applies them, according to scikit-learn Docs. The effect is geometric: every feature now contributes to distances and gradients on the same footing, so the optimizer weighs them by relevance rather than by raw size. This is the broader practice of
Feature Scaling, and standardization is one of its two dominant forms.
The other is
Normalization — rescaling a feature to a fixed range, typically [0, 1], using MinMaxScaler. The distinction matters and gets blurred constantly: standardization assumes nothing about bounds and tolerates outliers better; normalization compresses everything into a fixed interval and is sensitive to extreme values. Some texts use “normalization” loosely for both. Keep them separate in your head — they reshape the data differently, and the choice changes what the model sees.
Finally, the text. A model cannot multiply a weight by the word “London.”
Categorical Encoding solves this, and the safest default is
One Hot Encoding: a categorical feature with n distinct categories becomes n binary columns, exactly one of which is hot per row — the one-of-K scheme that scikit-learn’s OneHotEncoder implements, per scikit-learn Docs. The reason to prefer this over simply numbering the categories (London = 1, Paris = 2, Tokyo = 3) is subtle but decisive: integer labels imply an ordering and a distance the model will happily exploit. Tokyo is not three times London. One-hot encoding refuses to smuggle in an order that does not exist.
What are the main steps of a data preprocessing workflow?
A workflow assembles those moves into a fixed sequence, and the sequence is where most quiet failures hide. The order that survives contact with production looks like this:
- Split first — perform the Train Test Split before fitting any transformation. This single decision prevents an entire class of bug, explained below.
- Clean — repair or impute missing values, learning the imputation statistics from the training split only.
- Detect outliers — use Outlier Detection to flag or cap extreme values that would distort scaling statistics, again measured on training data.
- Scale numeric features — fit the scaler on the training split, then apply it to both splits.
- Encode categorical features — fit the encoder on training categories, then transform both splits.
- Engineer features where useful — the deliberate construction of new informative columns, which is the domain of Feature Engineering and sits on top of, not instead of, the steps above.
The non-negotiable rule running through every step: each transformer learns its parameters from the training data and applies them everywhere. scikit-learn formalizes this with Pipeline and ColumnTransformer, which bind the fit-then-transform discipline into a single object so different column types get different treatment without leaking statistics between them, according to scikit-learn Docs.
What the Pipeline Predicts Will Go Wrong
Once you see preprocessing as a sequence of learned transformations, its failure modes become predictable rather than mysterious. Each one follows from a violated assumption.
- If you scale before splitting, expect validation scores that look excellent and production scores that collapse. The scaler saw the test set’s statistics during
fit, so your evaluation was quietly contaminated. - If you impute with the global mean computed over all data, expect the same optimistic bias, smaller but real — the test rows influenced the fill value they were later judged against.
- If you integer-encode an unordered category, expect the model to learn a phantom ranking and behave strangely on categories near the numeric extremes.
- If a category appears at inference that was absent at fit time, expect a crash — unless the encoder was configured to expect it, which is why
handle_unknown='ignore'exists onOneHotEncoder.
The common thread is Data Leakage: information from outside the training set bleeding into the preprocessing parameters. It is the most expensive bug in applied machine learning precisely because it does not announce itself. Your metrics improve. Everything looks correct. The model fails only when it meets data that the preprocessing never legitimately saw.
Rule of thumb: fit every transformer on the training split alone, then transform train and test with those frozen parameters — no exceptions, no shortcuts.
When it breaks: the dominant failure is fitting scalers, encoders, or imputers on the full dataset before the train-test split, which leaks test-set statistics into training and inflates every validation metric you trust. The model that looked strong in the notebook degrades the moment it meets genuinely unseen data.
The Tooling Is Stable, the Discipline Is Not
The libraries that implement all of this are mature and converging. scikit-learn provides the transformers and the pipeline machinery; Pandas handles the tabular cleaning and wrangling; Polars, a Rust-based DataFrame library, covers the same ground when data outgrows memory or speed becomes the constraint. None of these tools is exotic, and none of them will save you from a leak. The tooling enforces how a transformation runs. It does not enforce when you fit it — that judgment stays with you.
Compatibility notes:
- pandas 3.x: Copy-on-Write is now the default behavior (since version 3.0.0, January 2026), so chained-assignment patterns that used to mutate a DataFrame in place no longer do. Default string columns are PyArrow-backed. Write examples assuming pandas 3.x semantics. Current release: 3.0.3 (pandas Release Notes). Requires Python 3.11 or newer.
- scikit-learn 1.9.0:
StandardScaler,MinMaxScaler,OneHotEncoder, andOrdinalEncoderlive insklearn.preprocessing; combine them withPipelineandColumnTransformerfor leakage-safe fitting (scikit-learn Docs).- polars 1.41.2: current PyPI release for performance-sensitive or larger-than-memory preprocessing (polars PyPI).
The Data Says
Preprocessing is where a model’s ceiling is set. Cleaning, scaling, and encoding decide what signal survives the trip from raw table to numeric array, and the single discipline that separates a trustworthy pipeline from a deceptive one is fitting every transformation on training data alone. The model gets the credit; the preprocessing did the work.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors