What Is Data Labeling and Annotation, and How Ground-Truth Labels Train Supervised Models
ELI5
Data labeling attaches the correct answer to each raw example — a box around a pedestrian, a category on a review — so a supervised model can learn the mapping from input to output. The labels become its definition of “true.”
A supervised classifier confuses two product categories that no reasonable person would mix up. The instinct is to blame the architecture, add layers, tune the Learning Rate. But retraining changes nothing, because the model is doing exactly what it was told. Somewhere in the training set, hundreds of examples were labeled by three different annotators who quietly disagreed about where one category ends and the next begins. The model didn’t fail randomly. It inherited a boundary that was never coherent in the first place.
This is the uncomfortable part of supervised learning that benchmark leaderboards rarely advertise: the model’s ceiling is the quality of its labels. The term “ground truth” implies bedrock — something objective, sitting underneath the data, waiting to be read off. The reality is closer to a negotiated agreement between tired humans looking at ambiguous examples. Understanding how that agreement gets manufactured is the difference between debugging the model and debugging the data.
Ground Truth Is a Manufactured Artifact
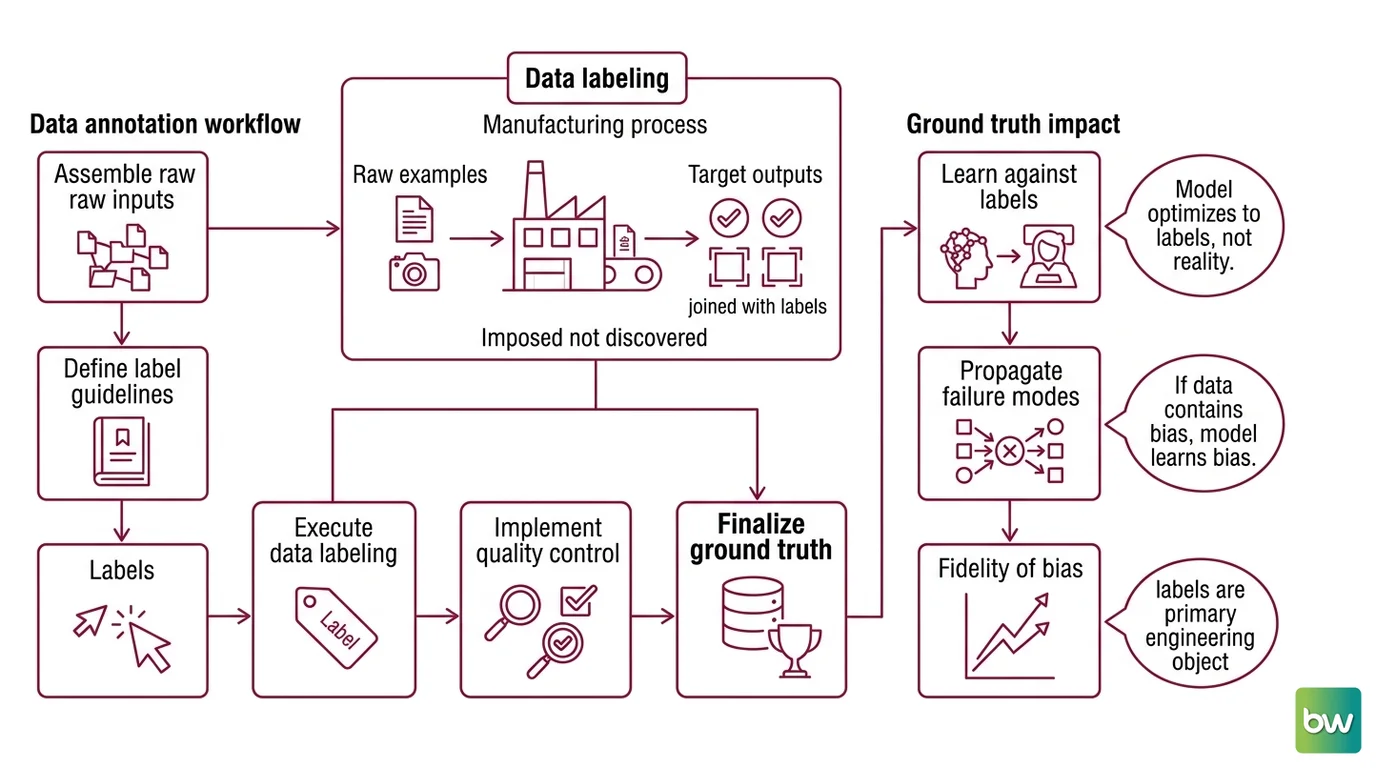
Before a Supervised Fine Tuning run ever begins, someone has to decide what the right answer is for every example. That decision is not discovered in the data — it is imposed on it. The labels are an artifact of a process, and like any process, it has variance, bias, and failure modes that propagate downstream with surgical precision.
What is data labeling and annotation in machine learning?
Data labeling is the practice of attaching a target output to each raw input so that a supervised algorithm has something to learn against. The raw input — an image, a sentence, an audio clip — carries no inherent answer. Labeling assigns one: this image contains a tumor, this sentence is negative sentiment, these pixels are road surface. The collection of inputs paired with their assigned outputs becomes the Ground Truth dataset.
The distinction worth holding onto is epistemic. The label is not the truth about the world; it is the truth the model will optimize toward. A supervised model has no access to reality outside its training distribution — it sees only the examples and their assigned answers, and it adjusts its parameters to reproduce that mapping. If the assigned answers encode a systematic human bias, the model learns the bias with the same fidelity it learns the signal. It cannot tell the two apart.
This is why labeling is the highest-leverage and most underexamined stage of the pipeline. A Data-Centric AI view treats the labels as the primary object of engineering, not an afterthought handled by whoever is cheapest. The model architecture is largely fixed and reusable; the labels are where your specific problem actually lives.
How does the data annotation workflow turn raw data into training labels?
The workflow that converts a pile of raw examples into a usable training set is a pipeline in its own right, and each stage adds or removes noise.
It usually runs in this order: write the annotation guidelines, collect and clean the raw data (deduplication matters here — near-duplicate examples split across train and test sets inflate your metrics), assign examples to annotators, collect their labels, measure how much they agree, adjudicate the disagreements, and feed the resolved labels into training. The guidelines stage looks bureaucratic and gets skipped under deadline pressure, which is precisely why so many datasets are quietly broken: ambiguous instructions produce annotators who each resolve the ambiguity differently, and their private resolutions become noise in the aggregate.
A concrete failure mode lives in the cleaning stage. Running Data Deduplication before the split is not housekeeping — it is the difference between a metric that means something and one that flatters you. If the same example appears in both training and evaluation, the model can memorize rather than generalize, and your reported accuracy measures recall of seen data, not performance on new data.
The agreement-and-adjudication stage is where ground truth stops being a single annotator’s opinion and becomes a defensible consensus. Which is the natural place to ask the next question: how do you measure whether your annotators agree at all?
Measuring and Building the Consensus
Two annotators looking at the same example will sometimes assign different labels. The question is whether that disagreement is rare noise or a sign the task itself is underspecified. You cannot eyeball this across ten thousand examples — you need a metric, and the metric has to account for the fact that some agreement happens by pure chance.
What are the main types of data annotation (classification, bounding boxes, segmentation, NER)?
The shape of the label depends on the shape of the task, and the cost of labeling rises sharply with that shape’s complexity. For images, the standard progression runs from simple to complex: classification, bounding box, polygon, semantic segmentation, and instance segmentation, according to HumanSignal.
| Annotation type | What the annotator produces | Relative cost |
|---|---|---|
| Classification | One label for the whole input | Low |
| Bounding box | A rectangle around each object | Moderate |
| Polygon | A tighter outline following object edges | Higher |
| Semantic segmentation | A class for every pixel | High |
| Instance segmentation | Per-pixel class plus separate object identity | Highest |
Classification assigns a single category to an entire image or document. A bounding box draws a rectangle around an object — enough for a detector to learn “there is a car, roughly here.” Semantic Segmentation goes to the limit: pixel-wise labeling, where every pixel is assigned a class, as HumanSignal describes it. Instance segmentation adds one more axis, distinguishing this car from that car at the pixel level.
Text has its own hierarchy. Document classification labels a whole passage. Named entity recognition — NER — operates at the span level, identifying and labeling entities like names, dates, and organizations inside a sentence, per HumanSignal. The relevant pattern across all of these: as the label gets more granular, annotation time, cost, and the surface area for disagreement all grow together. More granular labels carry more information and more noise at once. The Entity Extraction task that tags every organization in a legal contract is far more expensive — and far more error-prone — than one that simply flags whether the contract mentions any organization at all.
Why inter-annotator agreement is the real quality signal
Once multiple people label the same examples, you can measure Inter Annotator Agreement — the degree to which independent annotators assign the same label. Raw percent agreement is misleading, because two annotators flipping coins on a binary task would agree half the time by chance alone. The standard fix is a chance-corrected statistic.
Cohen’s kappa measures agreement between two annotators on categorical labels, corrected for the agreement expected by chance, according to TELUS Digital. When you have more than two annotators, Fleiss’ kappa generalizes the same idea to the larger group, per TELUS Digital. Both ask the same underlying question: how much do these people agree beyond what randomness would produce?
A low kappa is diagnostic, and it usually points at the guidelines rather than the annotators. If three trained people cannot converge on a label, the task boundary is genuinely ambiguous, and no amount of model capacity will resolve an ambiguity the humans could not. The disagreement is information — it tells you which slices of your problem are ill-defined. One caution worth stating plainly: conventional thresholds like “kappa above 0.8 means good agreement” are useful rules of thumb, not formal standards. Treat them as conversation starters, not pass/fail gates.
When labeling at scale, you rarely label everything by hand. Active Learning inverts the workload: the model itself nominates the examples it is least certain about, and humans spend their expensive attention only where it changes the decision boundary.
What the Labels Predict About Your Model
The mechanism gives you predictions you can act on, because label quality propagates into model behavior in patterns that are recognizable once you know to look for them.
- If your annotators show low agreement on a class, expect the model to confuse that class with its neighbors — the model is reproducing the boundary the humans couldn’t draw.
- If accuracy is suspiciously high on evaluation but collapses in production, suspect leakage from missing deduplication before the train/test split, not a brittle architecture.
- If one category is both rare and inconsistently labeled, Class Imbalance and Label Noise compound: the model sees few examples, and the few it sees disagree with each other.
To label at scale without hand-annotating every example, two strategies reduce human cost. Active learning routes only the uncertain cases to humans — Amazon SageMaker Ground Truth auto-labels easy examples and sends hard ones to human annotators, reporting roughly 27% cost savings on bounding-box case studies, according to AWS Docs. Treat that figure as a case-study result for a specific task type, not a universal guarantee. The complementary approach, Weak Supervision, generates noisy labels programmatically from heuristics and then models the noise statistically rather than paying for clean labels everywhere.
Rule of thumb: before you touch the model, measure inter-annotator agreement on a sample — if humans disagree, the model will too.
When it breaks: Ground-truth labels are only as coherent as the guidelines behind them; when the task boundary is genuinely ambiguous, no labeling budget or model capacity can manufacture a consensus that does not exist, and the resulting label noise sets a hard ceiling on achievable accuracy.
The Quiet Tradeoff Between Speed and Truth
There is a deeper tension underneath all of this. Every shortcut that makes labeling cheaper — automation, weak supervision, fewer annotators per example — trades away some of the redundancy that lets you detect when the labels are wrong. A single annotator is fast and gives you no way to measure agreement at all. The cost of knowing your labels are good is paid in duplicated effort, and most broken datasets are broken because someone declined to pay it.
The Data Says
Ground truth is not found; it is built, and it carries the variance of the process that built it. Training Data Quality is the real lever in supervised learning — label noise propagates into model error geometrically, along the boundaries where humans disagreed. Measure agreement before you blame the architecture.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors