What Is Data Deduplication and How MinHash LSH Detects Near-Duplicate Training Samples

ELI5
Data deduplication removes repeated or near-identical examples from a training set before a model sees them. MinHash LSH makes it fast enough for billions of documents by comparing compact fingerprints instead of full text.
In Google’s C4 corpus, one ordinary 61-word English sentence appears more than 60,000 times, a figure documented by Lee et al. 2021. That is not a scraping bug. It is a structural feature of how the open web copies itself: terms of service, boilerplate, syndicated articles, mirrored forums. When a model trains on data shaped like this, the duplication does not average out. It accumulates, and the model learns the repeated text far more confidently than it learns anything you actually wanted it to know.
The Web Copies Itself, and Models Remember
The intuition that “more data is always better” quietly assumes each new document carries new information. On a scraped web corpus, that assumption breaks. A large fraction of what looks like volume is the same content wearing different URLs, and the model has no way to discount it on its own. Every duplicate is another gradient step pointing in the same direction.
What is data deduplication in machine learning?
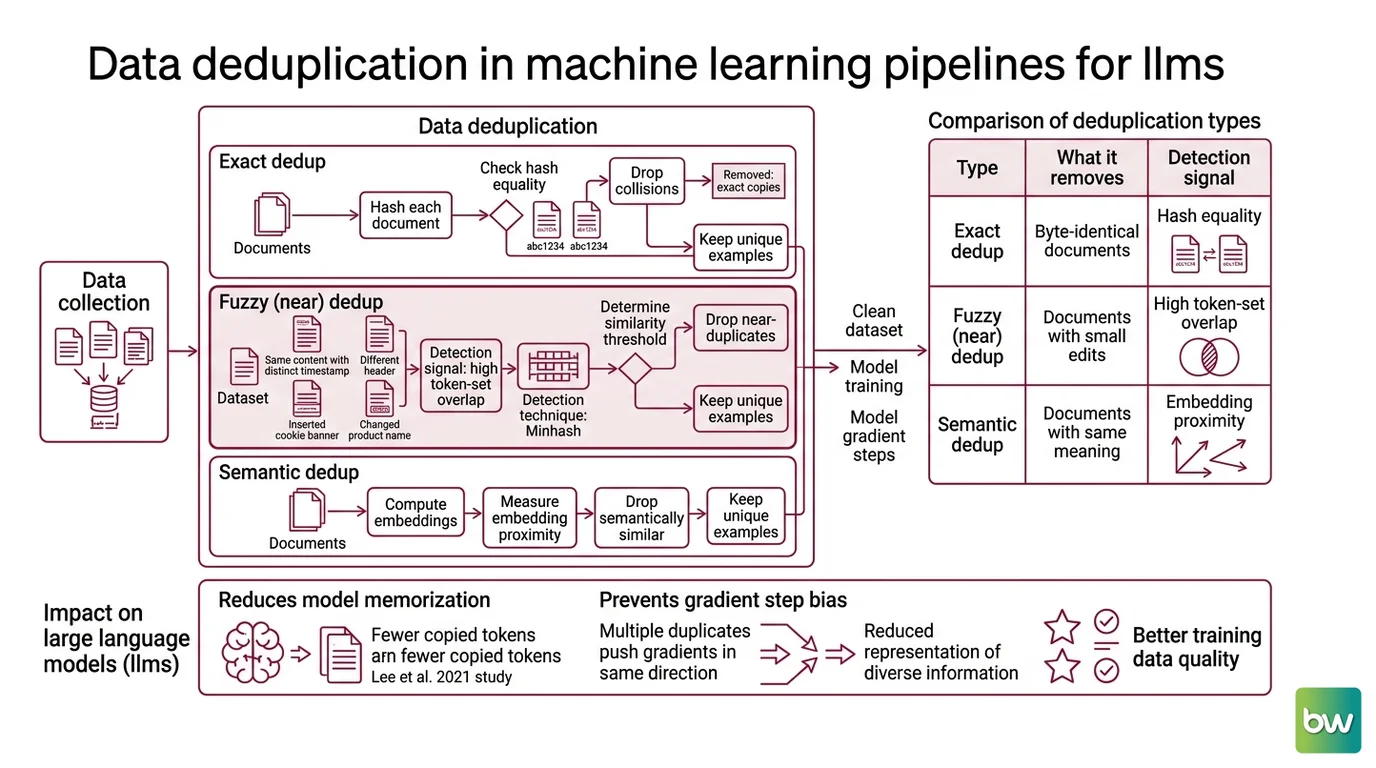
Data deduplication is the process of detecting and removing repeated or near-identical examples from a dataset before training. It sits in the Data Preprocessing stage, after collection and before the model ever computes a single gradient.
It helps to separate three regimes, because they require different machinery:
| Type | What it removes | Detection signal |
|---|---|---|
| Exact dedup | Byte-identical documents | Hash equality |
| Fuzzy (near) dedup | Documents that differ by small edits | High token-set overlap |
| Semantic dedup | Documents that say the same thing differently | Embedding proximity |
Exact deduplication is trivial; you hash each document and drop collisions. The hard and interesting case is the middle one. The web rarely copies text perfectly. It inserts a timestamp, swaps a header, appends a cookie banner, changes one product name. Two documents can be 99% identical and share not a single matching hash. That is the gap fuzzy deduplication exists to close, and it is where MinHash earns its keep.
What does deduplicating training data mean for large language models?
For a Training Data Quality pipeline feeding a foundation model, deduplication changes what the model is statistically pushed to do. Lee et al. 2021, in Deduplicating Training Data Makes Language Models Better, found that more than 1% of tokens emitted by an unprompted language model were copied verbatim from its training data. Deduplicating that data cut these memorized emissions by roughly an order of magnitude, and the deduplicated model reached equal or better accuracy in fewer training steps.
Read that second clause carefully, because it inverts a common fear. Removing data made the model better and cheaper to train, not worse. The duplicates were not adding knowledge; they were adding redundant gradient pressure that the model spent capacity absorbing.
Not memorization the model chose. Memorization the data forced.
This is the link to Memorization that makes deduplication more than housekeeping. A passage seen ten thousand times crosses the threshold from “pattern the model generalizes” to “string the model reproduces.” Deduplication lowers the count below that threshold, which matters for privacy, for benchmark contamination, and for whether the model generalizes or recites.
One precision note worth holding onto: the roughly 10x reduction is the specific result Lee et al. measured on C4-style corpora and their language models. Treat it as a strong, reproducible finding for that setting, not a universal constant you can promise for any dataset.
Exact Matches Are Easy; The Web Traffics in Near-Duplicates
The engineering problem is scale. Comparing every document to every other document is a quadratic operation, and at billions of documents, quadratic is a synonym for impossible. The entire design of a production dedup pipeline is an effort to never make that all-pairs comparison directly.
How does data deduplication work in foundation model training?
A foundation-model dedup pipeline usually runs in layered passes, cheapest filter first:
- Exact dedup. Hash every document; drop byte-identical copies. Fast, removes the obvious mirror sites.
- Substring dedup. Find long repeated spans across documents, not just whole-document copies. This is where a Suffix Array comes in: it indexes every suffix of the concatenated corpus so that long duplicated passages can be located in near-linear time, even when they sit inside otherwise-different documents.
- Fuzzy dedup. Catch documents that are near-duplicates but share no long exact span, using MinHash signatures plus Locality Sensitive Hashing.
- Semantic dedup. Optionally, catch paraphrases that survive all of the above using embeddings.
Each layer handles a failure mode the previous one misses. Exact hashing misses the timestamp-edited copy. Substring matching misses the document that was reworded sentence by sentence. Fuzzy matching misses the genuine paraphrase. The layers compound, which is why serious curation tools ship several of them in one pass.
The reason this ordering matters: each stage is more expensive than the last, so you want the cheap stages to shrink the corpus before the expensive stages ever run.
MinHash: Turning a Document Into a Fingerprint
Here is the central trick, and it is genuinely elegant. We want to know how similar two documents are without comparing them word by word. So we replace each document with a short numeric signature, engineered so that the signatures collide exactly as often as the documents overlap.
The similarity measure underneath is Jaccard Similarity: treat each document as a set of token shingles (overlapping n-grams), and measure the size of the intersection divided by the size of the union. Two documents that share most of their shingles have a Jaccard score near 1.
How does MinHash LSH detect near-duplicate documents at scale?
MinHash, introduced by Andrei Broder in 1997 for AltaVista’s near-duplicate web page detection, rests on one probabilistic identity. Apply a random hash function to every shingle in a document and keep only the minimum value. Now do the same for a second document. The probability that the two documents produce the same minimum equals their Jaccard similarity exactly, a relationship documented in the MinHash literature.
That is the whole engine. A single minhash is a coin flip weighted by similarity. Repeat with k independent hash functions and you get a signature of k numbers; the fraction of positions where two signatures agree is an unbiased estimate of their Jaccard similarity, with variance J(1−J)/k. More hashes, tighter estimate. A document of any length collapses to a fixed-size fingerprint, and similarity becomes a matter of counting matching slots.
But comparing every signature to every other signature is still quadratic. This is where locality-sensitive hashing turns similarity into a lookup. LSH splits each signature into bands of a few rows each. Two documents become candidate duplicates only if they hash identically in at least one entire band. Near-duplicates share many slots, so they almost certainly collide in some band; unrelated documents rarely share a whole band and are never compared. You tune the band geometry to place the detection threshold where you want it.
Think of it like a fingerprint bureau that files prints by groups of ridges. You never compare a new print against the whole archive. You look only in the drawers that match a partial pattern, and the physics of the filing system guarantees the true match is in one of them.
NVIDIA’s NeMo Curator implements exactly this for GPU-accelerated curation: MinHash signatures over character n-grams, then LSH for candidate matching. As of its v26.02 documentation, the defaults are 24-character n-grams, 20 bands of 13 minhashes each, a fixed seed of 42, and an operational similarity threshold around 80%. Those band-and-row numbers are not arbitrary; they are the knobs that set where the threshold lands, and they shift slightly between release versions, so pin the ones you actually run. For corpora that outgrow a single machine, the open-source Text Dedup library by Chenghao Mou packages the same MinHash-plus-LSH approach with a Spark backend for terabyte-scale jobs.
What Deduplication Predicts About Your Model
Once you see dedup as gradient accounting rather than tidiness, several consequences follow that you can check empirically:
- If you remove near-duplicates and hold compute fixed, expect the model to reach a target loss in fewer steps, because no capacity is spent re-learning repeated spans.
- If you tighten the LSH threshold too far (toward exact match), expect verbatim memorization to creep back, because reworded copies slip through.
- If you loosen the threshold too far, expect to delete legitimately distinct documents that merely share boilerplate, quietly shrinking real diversity.
- If your eval scores look implausibly strong, suspect benchmark contamination: test passages duplicated into the training set that dedup did not catch.
Rule of thumb: set your similarity threshold by what you are protecting against. Privacy and contamination call for aggressive dedup; raw scaling on a clean corpus tolerates a looser cut.
When it breaks: MinHash LSH only sees lexical overlap. Two documents that express the same fact in entirely different words have low Jaccard similarity and sail straight through, so a fuzzy pipeline systematically under-counts true redundancy in paraphrase-heavy data.
The Paraphrase Problem, and Why Embeddings Enter
That last failure mode is exactly what Semantic Deduplication addresses. Instead of comparing token sets, SemDeDup (Abbas et al. 2023) compares pretrained embeddings, clustering documents that are close in vector space even when they share no surface words. Their result is striking: removing 50% of a LAION subset by semantic near-duplication caused minimal performance loss. Half the data was, in information terms, ballast.
The progression is worth naming. Exact hashing asks “are these the same bytes?” MinHash asks “do these share the same words?” Embeddings ask “do these carry the same meaning?” Each step trades cheap, exact computation for a fuzzier but more powerful notion of “duplicate,” and each catches redundancy the previous step is blind to.
The Data Says
Deduplication is not data cleaning in the cosmetic sense; it is a correction to the gradient signal a model receives. The measured payoff in Lee et al. 2021 was about an order of magnitude less verbatim memorization and equal-or-better accuracy in fewer steps, achieved by removing data. MinHash LSH is the mechanism that makes this feasible at web scale, by converting an impossible all-pairs comparison into a fingerprint lookup whose collision rate equals the similarity you care about.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors