What Is Data Augmentation and How Transforming Samples Expands Training Data
ELI5
Data augmentation creates new training examples by transforming the ones you already have—flipping images, swapping words, masking audio. The model sees more variety without anyone collecting more data, so it learns to generalize instead of memorize.
Train two identical models on the same five thousand photos. Feed the first the images untouched. Feed the second the same images—rotated a few degrees, cropped, slightly recolored—and nothing else. The second model consistently generalizes better on photos it has never seen, even though, by any strict information measure, you handed it no new data. That gap between “same pixels” and “better behavior” is the entire subject of this article.
The intuitive story is that augmentation is a cheap way to fake a bigger dataset. More rows, more learning. That story is wrong in a way worth correcting, because it predicts the wrong failures. Augmentation does not add information. It adds constraints—it tells the model which changes to an input are supposed to leave the answer alone.
Teaching a Model What Doesn’t Matter
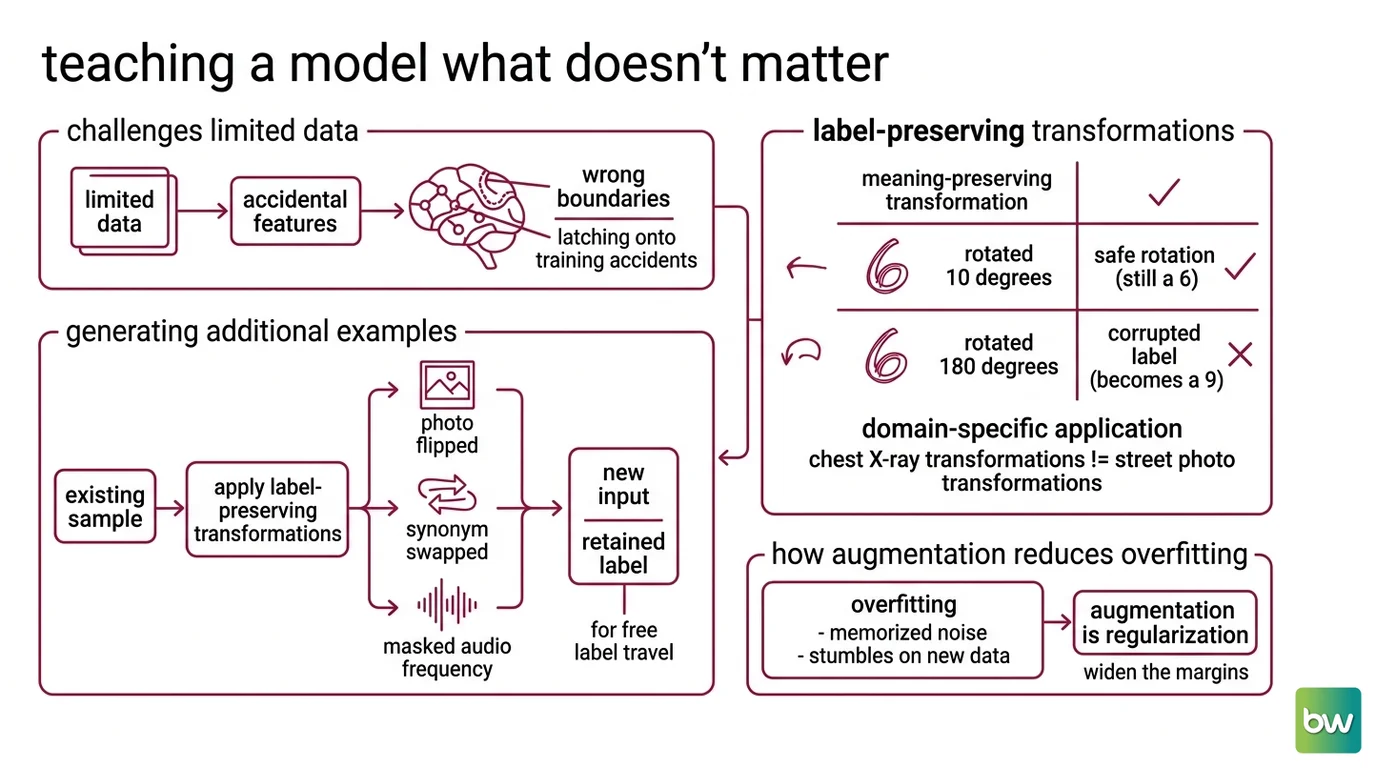
A trained model carves the input space into regions, one per label. The trouble is that with limited data, those boundaries get drawn through the wrong places—they latch onto accidents of the training set rather than the features that actually define a class. Augmentation attacks this directly by showing the model many versions of the same thing, each one declaring: this transformation changed the pixels but not the truth.
What is data augmentation in machine learning?
Data augmentation is the practice of generating additional training examples by applying label-preserving transformations to existing samples. A photo of a cat, flipped horizontally, is still a cat; a sentence with one word swapped for a synonym still carries its meaning; a spoken phrase with a short frequency band masked is still the same phrase. Each transformation produces a new input that shares the original’s label.
The key constraint hides in the phrase label-preserving. The transformation must change features the task should ignore while leaving the label intact. Rotating a handwritten digit by ten degrees is safe; rotating a 6 by 180 degrees turns it into a 9 and quietly corrupts your labels. This is why augmentation is domain-specific rather than universal—the set of meaning-preserving transformations for chest X-rays is not the set for street photos.
Done well, augmentation is the cheapest form of Training Data Quality improvement available, because it requires no new Data Labeling And Annotation. The label travels with the transformed sample for free.
How does data augmentation reduce overfitting?
Overfitting happens when a model memorizes the training set—including its noise and quirks—instead of the underlying pattern. The classic symptom is a model that scores near-perfect on training data and stumbles on anything new. Augmentation is a form of Regularization: it widens the slice of the input distribution the model sees during training, so memorizing individual examples stops being a viable shortcut.
The mechanism is best understood geometrically. Each augmented copy lands near its original in input space but not on top of it, populating the empty neighborhood around every real sample. The model can no longer draw a tight boundary that wraps each training point exactly; it has to find a smoother boundary that survives all the variations. That smoothness is exactly what generalizes to unseen data.
It helps to be precise about what is established and what is assumed here. The regularizing effect is well documented and reproducible. The cleanest causal account is that augmentation injects a prior—an assumption that certain transformations are irrelevant to the label—and the model inherits that invariance. But the size of the benefit is not guaranteed; it depends entirely on whether your transformations are genuinely label-preserving and realistic for the domain. Augmentation encodes an assumption, and a wrong assumption degrades the model.
The Families of Transformations
Augmentation techniques fall into a few recognizable families, separated by how they manufacture a new sample. The first family edits a single example. The second blends two. A third is built for the quirks of a specific modality. Knowing which family you are reaching for matters more than memorizing any single trick.
What are the main categories of data augmentation techniques?
The first and largest family is single-sample label-preserving transforms. For images, these are the geometric and photometric edits—flips, rotations, crops, brightness and contrast shifts. For text, they include synonym replacement and
Back Translation, where a sentence is translated to another language and back to surface a paraphrase. For audio, they include adding noise or shifting pitch. The open-source ecosystem here is mature: AlbumentationsX 2.1.3—the actively developed successor to classic
Albumentations—handles image and 2D/3D transforms and installs with pip install albumentationsx (Albumentations Docs);
Nlpaug provides character-, word-, and sentence-level text augmenters including back-translation and contextual word insertion (nlpaug GitHub); and Meta’s
AugLy bundles over 100 augmentations spanning audio, image, text, and video under an MIT license (AugLy GitHub).
The second family is mixing-based augmentation, which interpolates between two samples instead of perturbing one. Mixup constructs a new example as a linear interpolation of two random training samples and their labels, with the mixing weight λ drawn from a Beta(α, α) distribution (mixup paper). The α hyperparameter is a tuning choice rather than a fixed rule—values in the 0.1–0.4 range are common starting points for ImageNet, but the right setting is dataset-dependent. CutMix takes a more spatial approach: it cuts a rectangular patch from one image, pastes it onto another, and mixes the two labels in proportion to the patch area (CutMix paper). Both methods push the model toward smoother behavior in the gaps between classes.
The third family is modality-specific augmentation, designed around the structure of one data type. The clearest example is SpecAugment, which operates directly on the log-mel spectrogram of an audio clip rather than the raw waveform—applying time warping, frequency masking, and time masking (SpecAugment paper). Masking a band of frequencies forces a speech model to recognize a word even when part of its acoustic signature is missing, which is precisely the robustness a real microphone demands.
These families compose. A vision pipeline routinely stacks geometric transforms with mixup; a speech pipeline layers noise injection under SpecAugment.
Compatibility notes:
- Albumentations: Active development moved from the classic albumentations package to the dual-licensed AlbumentationsX. For current transforms and docs, install
albumentationsx, not the legacy package.- nlpaug: Still functional, but maintenance is inactive—no PyPI release in over a year (last version 1.1.11). Pin your version and test before relying on it in a pipeline.
What Augmentation Can and Cannot Buy You
Treating augmentation as an invariance prior, rather than as free data, turns it into something you can reason about predictively:
- If your augmentations match the variation in your test data, you should see the train/test accuracy gap shrink—that is overfitting receding.
- If you augment too aggressively—rotating digits until
6becomes9—you should observe training loss rising and labels effectively corrupting, because the transformations stopped preserving meaning. - If augmentation barely helps, your model is likely underfitting or your dataset is already large enough that the invariances are well sampled; the prior you are adding is one the model already had.
Augmentation also interacts with the rest of the data stack. It is not a substitute for Data Deduplication—duplicating a leaked test sample and then augmenting it just launders contamination. And when the real problem is too few examples of a rare category, targeted collection through Active Learning often beats blindly multiplying the samples you have.
Rule of thumb: Choose augmentations that mimic the variation your model will actually meet in production—and no transformation that could flip the label.
When it breaks: Augmentation reduces overfitting only when transformations are genuinely label-preserving and realistic for the domain; unrealistic or label-corrupting transforms inject noise that degrades the model, and no amount of augmentation can manufacture a class the model has never seen.
The Data Says
Data augmentation is not a way to fake a larger dataset—it is a way to encode, into the training process, which changes to an input should leave the answer unchanged. Its benefit is real and reproducible, but conditional: it scales with how well your transformations preserve labels and mirror real-world variation. Pick the wrong invariances and you are not regularizing, you are corrupting.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors