Contextual Retrieval: How Prepended Context Reduces RAG Failures

ELI5
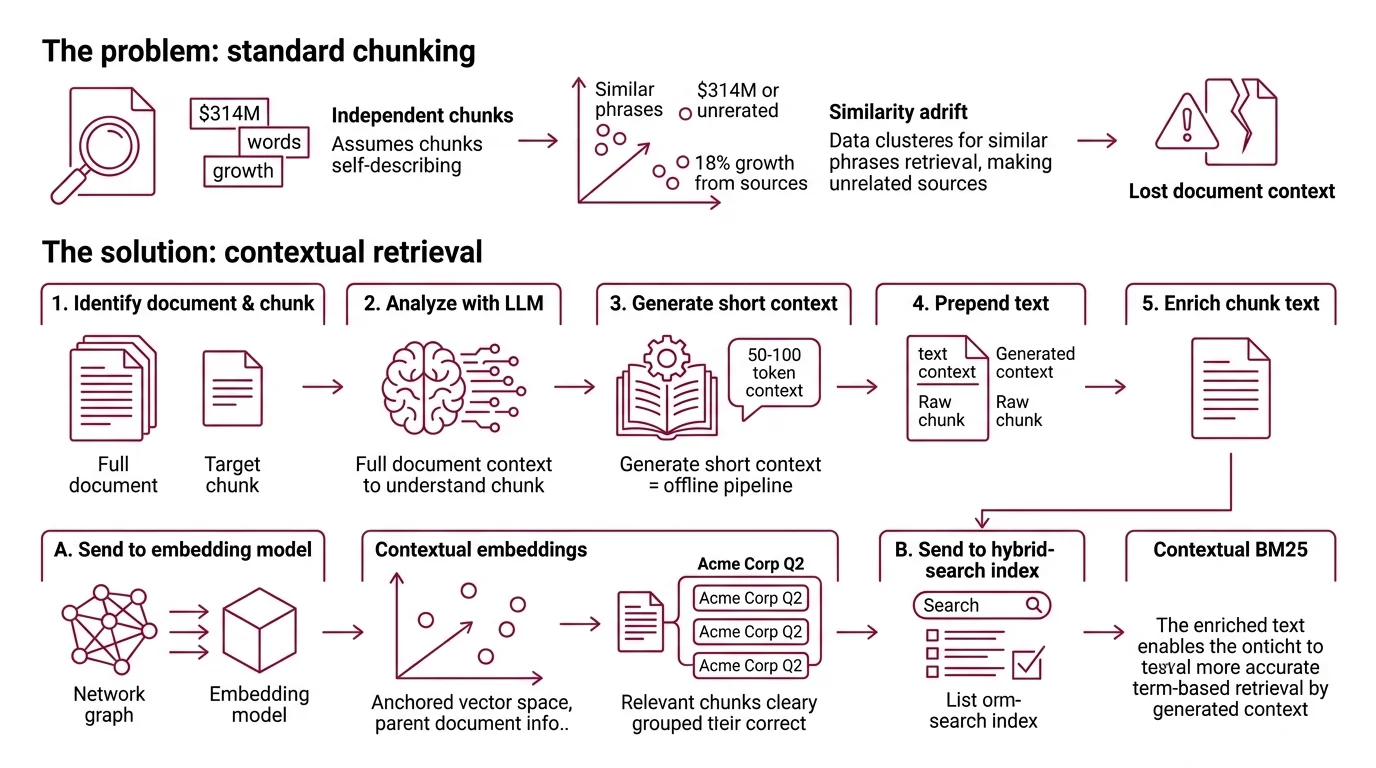
Contextual retrieval is a Retrieval Augmented Generation technique that prepends a short, LLM-generated explanation to each chunk before embedding and indexing — so retrieval sees what the chunk is about, not just what it says.
A user asks: “What was Acme’s revenue in Q2 2023?” The vector store dutifully retrieves a chunk containing the sentence “The company reported revenue of $314M, an 18% year-over-year increase.” Plausible. Confident. Wrong company, wrong quarter.
The chunk was correct in its source document. The chunk became wrong the moment it lost its source document.
This is the failure mode contextual retrieval was built to fix.
What Standard Chunking Forgets
Vector retrieval starts from a clean assumption: chunks are self-describing. Embed the words; similarity will find what matters. The assumption breaks the moment a chunk relies on its parent document for meaning — which, for any document longer than a paragraph, is most chunks.
What is contextual retrieval in RAG?
Contextual retrieval is a recipe published by Anthropic in September 2024 (Anthropic Blog) that enriches each chunk with a short, document-aware explanation before embedding and before BM25 indexing. The chunk is no longer just the raw text. It is the raw text plus 50 to 100 tokens of LLM-generated context: “This chunk is from Acme Corp’s Q2 2023 earnings report; the prior section discussed segment-level revenue growth.” Then embed that.
The change is small. The consequence is geometric. The chunk’s vector now lives in a region of Hybrid Search space anchored by its parent document, not adrift among every other chunk that happens to mention “$314M” or “18% growth.”
Not a clever embedding model. A pre-processing step that gives the embedding model something worth embedding.
How does contextual retrieval work to enrich chunks before indexing?
The pipeline runs offline, once per document. For each chunk, the recipe is:
- Pass the whole document plus the target chunk to an LLM.
- Ask: in 50–100 tokens, situate this chunk within the document — what is it about, and how does it relate to what surrounds it?
- Prepend that generated context to the chunk text.
- Send the enriched chunk to the embedding model.
- Send the same enriched chunk to a hybrid-search BM25 index.
Anthropic calls the two arms of this “Contextual Embeddings” and “Contextual BM25” (Anthropic Blog). A precise reading: BM25 itself is unchanged. Plain BM25, run over context-enriched chunks. The index is the same. The input is richer.
The expensive part is step 1 — calling an LLM once per chunk, multiplied by every chunk in the corpus. Anthropic reports the cost falling to roughly $1.02 per million document tokens when prompt caching is enabled, since the same parent document is reused across all its chunks (Anthropic Blog). Caching cuts the bill by up to ~90% relative to uncached generation. Treat the figure as order-of-magnitude — it was measured against then-current Haiku pricing in late 2024, and today’s exact cost depends on the model and caching tier you actually run.
Three Components Stacked Together
The technique is rarely run alone. The interesting result is what happens when contextual retrieval is layered with two other steps the RAG community already understood: hybrid retrieval and Reranking.
What are the components of a contextual retrieval pipeline?
A full contextual retrieval pipeline has four stages, each addressing a distinct failure mode:
| Stage | What it adds | What it fixes |
|---|---|---|
| 1. Contextual enrichment | LLM-generated 50–100 token preface per chunk | Chunks that depend on their parent document |
| 2. Contextual Embeddings | Dense semantic retrieval over enriched chunks | Misses on paraphrase and conceptual similarity |
| 3. Contextual BM25 | Lexical (sparse) retrieval over the same enriched chunks | Misses on rare names, IDs, exact strings |
| 4. Reranking | Cross-encoder scoring of top candidates, then top-20 to the model | Order quality among already-relevant candidates |
Anthropic’s reference implementation uses Voyage and Gemini embeddings paired with Cohere Rerank for the final ordering (Anthropic Blog). The original 2024 post named a specific Gemini embedding version — Google’s text-embedding family has shifted since, so treat embedding model choice as a benchmark-it-yourself decision rather than a hard recommendation.
The shape of the pipeline is the point: each stage corrects a different category of error, and the gains compound rather than substitute. Note also what this pipeline does not address — it improves the index, not the question. Reformulating the user’s input is the job of Query Transformation, and dynamic retrieval logic that decides what to fetch belongs to Agentic RAG systems. Different stages, different concerns; layer them together.
What the Layers Predict When You Stack Them
Here is where the geometry gets interesting. Anthropic’s evaluation reports retrieval-failure rates across the stack, measured against a 5.7% baseline (Anthropic Blog):
- Contextual Embeddings alone: 35% reduction in retrieval failures, dropping the failure rate from 5.7% to 3.7%.
- Contextual Embeddings plus Contextual BM25 (hybrid): 49% reduction, dropping to 2.9%.
- All three plus reranking: 67% reduction, dropping to 1.9%.
A clarification the third-party blogosphere keeps mangling: a 67% reduction in retrieval failures is not a 67% accuracy lift. The headline is “1.9% of queries still fail to surface the right chunk in the top 20.” The improvement is enormous in relative terms and modest in absolute terms — both readings are true. These numbers also come from Anthropic’s own internal evaluation. They have been widely cited but, as of the time of writing, have not been independently reproduced at the same scale.
If you change one variable at a time, the predictions are reasonably clean:
- If your corpus is mostly long, structurally cohesive documents — legal filings, financial reports, scientific papers — contextual enrichment should help more than on a corpus of standalone snippets. The fix is to chunks that need their parent; standalone chunks have nothing to gain.
- If your queries lean on rare identifiers — product SKUs, error codes, person names — the BM25 leg matters disproportionately. Embeddings smooth over exact tokens; BM25 doesn’t.
- If your top-k is small (k=5), reranking matters more than retrieval recall, because there is less room to be wrong before the right chunk falls out of the window.
Rule of thumb: before tuning embedding models, check whether your chunks know what document they came from.
When it breaks: the technique assumes a corpus that fits the offline-enrichment economics. Generating context for every chunk costs real money on multi-billion-token corpora, and the index must be re-enriched whenever the source documents change. For high-churn or massive corpora, the LLM-context step is the bottleneck — not the embedding model.
A Detail Most Implementations Miss
The token budget on the prepended context is not a hyperparameter to over-engineer. The recipe specifies 50 to 100 tokens for a reason: short enough that the chunk text still dominates the embedding, long enough to anchor the chunk to its document. Push the context to 300 tokens and the embedding starts representing the document summary more than the chunk content — relevance scores degrade, retrieval shifts toward whichever chunks share parent-document framing rather than whichever chunks actually answer the query.
The pre-processing is solving a specific problem: chunks that are ambiguous without their document. It is not solving “embeddings are bad.”
This is also why two newer approaches sit alongside the technique rather than replacing it. Voyage AI’s voyage-context-3, released July 23, 2025, embeds chunks with global document context built into the model itself — no separate LLM enrichment step (Voyage AI Blog). Jina’s late chunking takes a different route entirely: embed the whole document with a long-context encoder first, then mean-pool chunks after token-level embedding (Jina AI). Different architectures, same diagnosis. The original failure mode — chunks losing their document — is now a recognized class of problem, not a quirk of one recipe.
What this tells us, indirectly, is that “Contextual Retrieval” (Anthropic’s branded September 2024 recipe) and “contextualised chunk embeddings” (the broader technique family) are not synonyms. The recipe is one implementation. The category is older and wider.
The Data Says
Contextual retrieval’s contribution is not a new index or a new embedding model. It is the recognition that the embedding model is being asked to represent something the chunker stripped away. Prepend the missing context, and Anthropic reports retrieval failures drop by roughly half before reranking, and by two-thirds with reranking — measured against their own internal eval, on a baseline that was already only 5.7% wrong.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors