What Is Context Engineering for Code and How It Shapes AI Coding Assistant Output
Table of Contents
ELI5
Context engineering for code is the practice of curating which tokens — system prompts, files, tools, conversation history — your AI coding assistant sees during inference, so its output stays accurate as your codebase grows.
A developer pastes the same prompt into two identical Claude Code sessions; one runs inside a fresh repo and the other inside a sprawling monorepo. The first produces a clean function. The second produces something that looks correct, compiles, and silently calls a method that was deprecated several releases back. The model is the same. The prompt is identical. Only the surrounding tokens differ — and that difference is doing all the work.
For a while it was tempting to call this a prompt problem. Better instructions, the thinking went, would close the gap. But the prompt did not change. What changed was everything around it: the open files, the tool responses, the half-remembered conversation, the documentation the IDE auto-injected and forgot to remove. That surrounding state has a name now. And it is not prompt engineering.
The token environment around your AI assistant
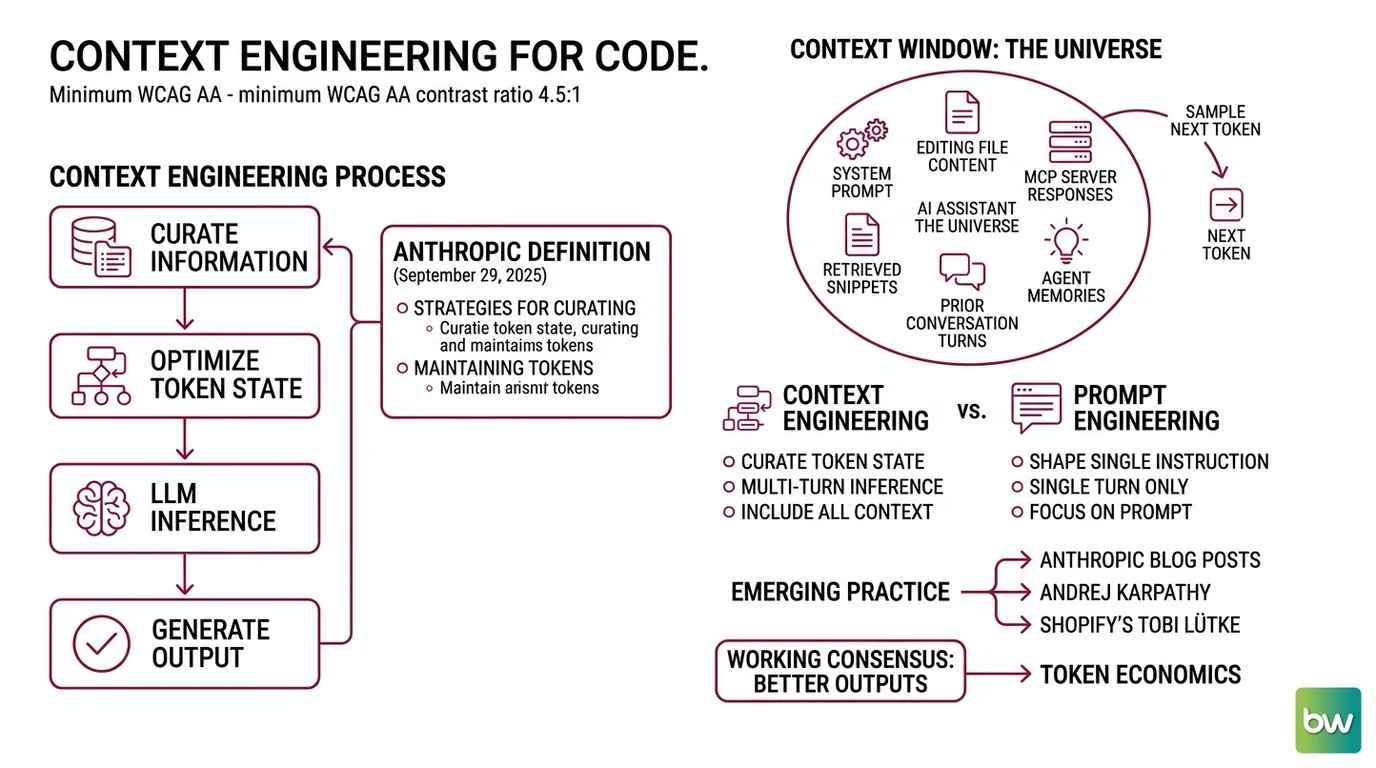
Every coding assistant runs the same fundamental operation: it samples the next token conditioned on everything currently inside the Context Window. The window is the universe; nothing outside it exists from the model’s point of view. So the question of “what is in the window, in what order, and at what cost” turns out to determine output quality more than the prompt itself.
What is context engineering for code?
Context engineering is “the set of strategies for curating and maintaining the optimal set of tokens (information) during LLM inference” — the definition Anthropic published on September 29, 2025 (Anthropic Engineering). The phrasing is deliberate. The unit of design is not the instruction. It is the token state.
For coding agents, that state is unusually rich: a system prompt with project conventions, the contents of the file you are editing, responses from Model Context Protocol servers, retrieved snippets from elsewhere in the repo, prior turns of conversation, and whatever the agent decided to remember from earlier sessions. Prompt engineering shapes a single instruction; context engineering curates the full token state across multi-turn inference, including system prompts, tools, external data, and message history (Anthropic Engineering). Both still matter. But for an agent that runs through many turns inside a million-token window, the prompt is a small share of what the model actually attends to.
Frame the discipline as emerging practice, not a settled field. The phrase was popularised through 2025 blog posts from Anthropic, Andrej Karpathy, and Shopify’s Tobi Lütke; as of mid-2026 it has no formal peer-reviewed canon. What it does have is a working consensus about which token-state strategies repeatedly produce better outputs.
Not prompt nicety. Token economics.
The mechanism beneath assistants like Claude Code and Cursor
The model’s behaviour is a deterministic function of weights and a probabilistic function of inputs. The weights are frozen at training. The inputs — context — are the only lever a tool builder has at runtime. So every coding assistant is, at the architectural level, a context-management system wrapped around a frozen model. The differences between them are differences in curation strategy.
How does context engineering work in AI coding assistants?
The dominant strategy as of mid-2026 is just-in-time loading. Instead of pre-loading every potentially relevant file into the window, the agent keeps lightweight identifiers — file paths, search queries, symbol names — and dynamically retrieves data at runtime via tools (Anthropic Engineering). The cost of a token grows with how many other tokens you keep alongside it. Carrying a long file just in case the agent needs one line wastes attention on every other line.
Claude Code implements this through a layered memory model. A project-root CLAUDE.md file is always loaded; it carries conventions the model should treat as background knowledge. Rules apply when a file matches a path pattern. Skills are lazy-loaded markdown bundles the agent decides to call on. Subagents run with isolated context windows so a deep search does not pollute the main thread. Hooks intercept tool calls deterministically (Martin Fowler / Böckeler). Each layer is a different answer to the same question: when should this information enter the window, and when should it leave?
Cursor takes a different cut. Its @codebase mention triggers indexed semantic plus structural retrieval that cites the files it pulls (SitePoint). The retrieval interface is more explicit — you ask, it fetches, the agent reasons. Same principle, different UX surface.
The connective tissue across vendors is Model Context Protocol, the open standard Anthropic introduced in November 2024 (Anthropic Newsroom) and donated to the Linux Foundation’s Agentic AI Foundation in December 2025 (Wikipedia). MCP standardizes how a model talks to external tools and data sources, which means a single tool server can plug into Claude Code, Cursor, Copilot, or anything else that speaks the protocol. Python and TypeScript SDKs see roughly 97 million monthly downloads, with more than 10,000 MCP servers running in production (WorkOS). Scale matters here because it tells you which interface the ecosystem is converging on.
Underneath the interface, indexing is hybrid. Most production assistants combine abstract-syntax-tree or code-graph traversal — which preserves structural relationships such as “this function calls that one” — with vector embeddings stored in a vector database for semantic similarity. MCP is becoming the standard query layer over that index.
What are the components of a code context window?
Birgitta Böckeler’s taxonomy, widely cited by 2026, organizes the components into four layers (Martin Fowler / Böckeler):
| Layer | What it is | Lifetime |
|---|---|---|
| Reusable prompts | System prompts, persona instructions, project-level guidance | Session or longer |
| Context interfaces | Tools the agent can call, including MCP servers and skills | Defined at startup, invoked on demand |
| Workspace files | Open files, retrieved code, documentation snippets | Just-in-time |
| Conversation history | Prior turns; trimmed or compacted as it grows | Within session, decays under pressure |
The taxonomy maps cleanly onto a memory distinction that matters in practice: short-term memory is the live context window — open files, recent actions, tool responses from this session. Long-term memory is anything that survives the session — rules files, project conventions such as CLAUDE.md, external memory services, persisted vector indexes. The agent feels continuous to a developer who returns the next morning only because something outside the window restores the right pieces back into it.
Claude Code’s context window reaches up to 1 million tokens (SitePoint), which sounds like enough room to stop curating. It is not.
What the token economics predict
The mechanism implies specific failure modes you can predict before you observe them.
- If you load a large file purely for one symbol, expect the agent to lose track of details elsewhere in the window. Attention is finite; it dilutes across long inputs.
- If the relevant information sits in the middle of a long context, expect roughly a 30% or larger accuracy drop on retrieval — the lost-in-the-middle pattern (Morph LLM).
- If you mix semantically similar but irrelevant snippets into a retrieval result, expect the model to confuse them with the target. Distractor interference scales with similarity, not with topical correctness.
- If your conversation history grows past the point where summarization kicks in, expect details from earlier turns to vanish without warning. Compaction is lossy by design.
Chroma’s 2025 study tested 18 frontier models — including GPT-4.1, Claude Opus 4, and Gemini 2.5 — and found that every one of them degraded as input length grew. Irrelevant tokens did not sit neutrally in the window; they actively worsened output (Morph LLM). That finding contradicts the older “just enlarge the window” narrative. A larger window helps when the right information lives in it. It hurts when junk lives in it too.
Rule of thumb: the smallest context that contains the answer almost always beats the largest context that might contain the answer.
When it breaks: even well-engineered context cannot guarantee deterministic behaviour — a model conditioned on the same tokens twice can still produce different completions, because sampling is probabilistic by design (Martin Fowler / Böckeler). Context engineering raises the floor of expected quality; it does not flatten the variance.
The deeper consequence
Curation reframes what an AI coding assistant actually is. The model is not the product. The model is a frozen function; the product is the policy that decides which tokens reach it. Two teams using the same underlying weights can build assistants that behave very differently, and the difference is downstream of weights and upstream of output. It lives in the curation layer, where humans still write the rules.
That layer is also where most of the durable engineering work now happens. Tweaking a prompt is cheap. Designing the memory model that decides what your agent remembers between sessions, what it loads on demand, and what it refuses to load — that is architecture.
It is also what separates serious Agentic Coding workflows from quick exploratory sessions or Vibe Coding hacks, and it is what determines whether an AI Code Migration project produces something maintainable instead of a tall pile of plausible-looking diffs.
The Data Says
Context engineering shifted the design surface for AI coding tools from prompts to token-state policies. Claude Code’s layered memory model, Cursor’s @codebase retrieval, and the MCP ecosystem all converge on the same insight: bigger windows do not rescue bad curation, and the 18-model Chroma study quantifies the cost. The discipline is emerging, not settled — frame it that way.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors