What Is Benchmark Contamination and How Training Data Overlap Inflates LLM Evaluation Scores
Table of Contents
ELI5
Benchmark contamination happens when an AI model’s training data includes test questions it will later be graded on, inflating scores without improving real ability.
A model scores 88% on a standardized evaluation. Impressive, clean, the kind of number that ends up in press releases. Then someone rephrases the same questions without changing their meaning, and the score drops by 14 percentage points. The knowledge didn’t evaporate. It was never there. What looked like understanding was pattern-matching against memorized answers, and the only variable that changed was the surface wording of the test.
The Score That Evaporates When You Change the Wording
Standardized benchmarks exist to answer one question: what can this model actually do? Benchmark contamination turns that question inside out. Instead of measuring capability, the score begins to measure exposure — how much of the test the model has already encountered during training. The gap between those two things is wider than most leaderboard rankings suggest.
What is benchmark contamination in AI?
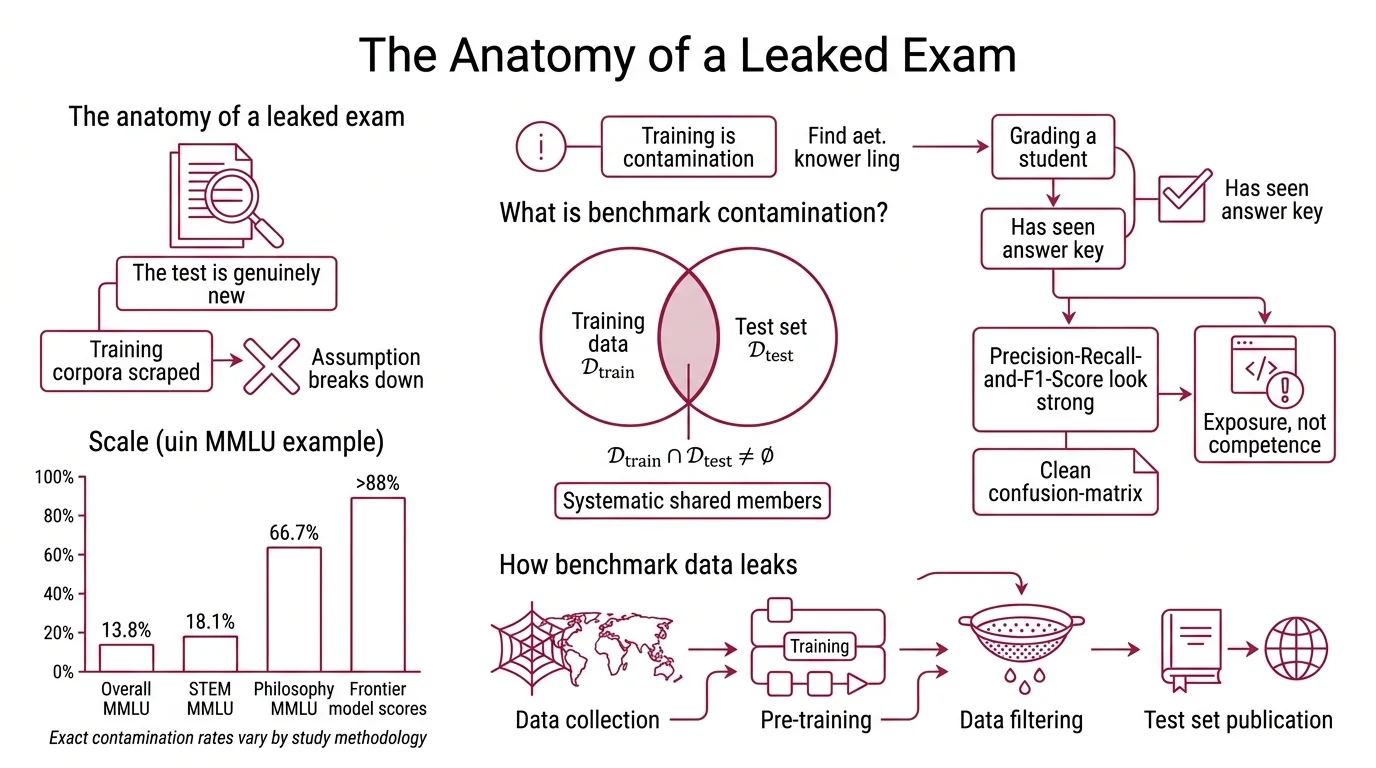
Benchmark contamination occurs when a model’s training data overlaps with the evaluation data used to measure its performance. The formal condition is direct: when the intersection of training data and test data is non-empty — 𝒟_train ∩ 𝒟_test ≠ ∅ — the evaluation is compromised (Cheng et al. survey). The model is not being tested on novel problems. It is being quizzed on material it has already seen, and the resulting score conflates Model Evaluation with recall.
Think of it like grading a student who found the answer key before the exam. The transcript looks clean. The grade looks real. But the number measures memory, not competence — and no one checking the transcript can tell the difference.
The scale of this problem resists the word “marginal.” A 2026 study across six frontier models found that 13.8% of MMLU Benchmark questions showed direct contamination, with STEM subjects at 18.1% and Philosophy reaching 66.7% (Reddy & Karmakar). Contamination rates vary by study methodology — no single authoritative number exists — but the direction is consistent. More troubling still: 72.5% of MMLU questions triggered memorization signals above random baseline. The model’s output distribution shifted in ways consistent with prior exposure even when exact text matches were absent.
This is not an edge case. It is a systemic measurement failure.
How does benchmark test data leak into LLM training sets?
The leakage pathways are structural, not conspiratorial. No one is sneaking test sets into training pipelines on purpose. The problem emerges from scale.
Large language models train on internet-scale corpora — web crawls spanning billions of pages, forum threads, academic repositories, documentation sites. Benchmark datasets like MMLU, GSM8K, and HumanEval are published openly for reproducibility. Their questions, answers, and metadata circulate through papers, blog posts, GitHub repositories, and educational platforms. By the time a model’s training data is assembled, benchmark content has been paraphrased, discussed, and redistributed across thousands of pages that a web crawler treats as ordinary text.
Pre-training leakage is the most common pathway: benchmark items enter the training corpus as part of the crawl, indistinguishable from the billions of other text fragments. But contamination also enters during fine-tuning, when curated instruction datasets inadvertently include benchmark-adjacent examples, and even post-deployment through reinforcement learning from human feedback, where annotators may reference benchmark-style problems in their evaluations.
The detection arms race reflects this. GPT-3 used 13-gram overlap to flag potential contamination; by GPT-4, the threshold had shifted to 50-character substring matching (Xu et al. survey). The detection evolved because the earlier threshold missed too much — shorter overlaps, paraphrased variants, and structural duplicates slipped through the filter. Each generation of decontamination reveals the limits of the previous one.
The uncomfortable arithmetic: the more data you train on, the higher the probability that benchmark content appears somewhere in the corpus. Decontamination is not a one-time filter applied before training begins. It is an ongoing adversarial problem, and the adversary is the sheer scale of the internet itself.
When the Model Has Already Seen the Exam
The distinction between memorizing an answer and understanding a problem is the fault line running through every contaminated benchmark score. Surface-level metrics — accuracy, Precision, Recall, and F1 Score — report correct answers. They cannot report whether those answers arrived through genuine reasoning or through recognition of a familiar pattern. The diagnostic requires a different kind of test.
What is the difference between memorization and generalization in benchmark contamination?
A model that generalizes can solve a problem it hasn’t seen before by applying learned patterns to novel inputs. A model that memorizes can reproduce the correct answer only when the input matches — or closely resembles — something from training. Both behaviors produce identical accuracy on the original benchmark. The difference only surfaces when you change the test conditions.
The simplest diagnostic: rephrase the questions and watch what happens.
When researchers paraphrased MMLU questions without altering their semantic content, accuracy dropped an average of 7.0 percentage points; in some domains, the drop exceeded 19 points (Reddy & Karmakar). The underlying competence didn’t change. The surface cues did. For a memorizing model, surface cues are the competence — the specific wording activates a stored pattern, and when that wording shifts, the activation fails.
The MMLU-CF benchmark — a contamination-free reconstruction built by Microsoft Research with a five-step decontamination pipeline — demonstrated this at scale. GPT-4o dropped from 88.0% to 73.4%; Llama-3.3-70B fell from 86.3% to 68.8% (MMLU-CF paper). Those gaps — 14.6 and 17.5 percentage points — represent the portion of the score that was memorization, not capability.
A separate experiment confirmed the mechanism from another angle entirely. When answer options were masked and models were asked to guess the missing choices, GPT-4 correctly identified 57% of them (Deng et al., NAACL 2024). A model encountering those questions for the first time would guess at chance level. Fifty-seven percent is not chance.
Not ignorance. Recognition.
What are the different types of benchmark contamination in machine learning?
Contamination is not a single phenomenon. It varies by when it enters the pipeline and how it manifests in the data, and these distinctions matter because they determine which detection methods will catch it and which won’t.
By pipeline phase, the taxonomy identifies four categories: pre-training leakage, where benchmark items enter through web crawls; fine-tuning contamination, where instruction-tuning datasets include benchmark-adjacent examples; post-deployment contamination, where RLHF annotators echo benchmark patterns; and multi-modal contamination, where test images or audio appear in training data for vision-language models (Cheng et al. survey).
By data manifestation, the spectrum ranges from exact text-label matches — where both the question and the correct answer appear verbatim in training data — to augmentation-based contamination, where paraphrased or restructured versions of benchmark items enter the corpus without triggering string-matching decontamination filters.
The most difficult variant to detect is soft contamination: semantic duplicates that share the logical structure of a benchmark problem without matching its surface text. A 2026 study found that 78% of CodeForces problems and 50% of ZebraLogic puzzles had soft duplicates in training data (Spiesberger et al.). These duplicates boosted performance roughly 15% on items with seen-style structure but only 5-6% on genuinely unseen problems — and the benefit did not transfer to distinct benchmarks at all.
That last detail is the diagnostic. If contamination produced real generalization, the improvement would carry across evaluations. It doesn’t. The improvement is local, shallow, and benchmark-specific.
What Inflated Scores Actually Predict
If a model’s benchmark performance includes a contamination component, the score overstates capability on any task that differs from the memorized patterns. For engineering teams selecting models based on leaderboard rankings, this produces a specific class of failure: the model that looked best on paper underperforms in production, and the Confusion Matrix built from real-world outputs does not match the benchmark-predicted distribution.
GSM8K, a grade-school math benchmark, demonstrated the pattern cleanly. When Scale AI created GSM1k — a parallel benchmark with equivalent difficulty but problems the models had never seen — accuracy dropped up to 13% for some model families. Mistral, Phi, and Gemma variants showed systematic overfitting; frontier models like GPT-4 and Claude showed minimal signs (Zhang et al., Scale AI). The contamination hit mid-tier models hardest — precisely the range where teams are most sensitive to benchmark differences when choosing between options.
Dynamic benchmarks attempt to solve this by ensuring evaluation data postdates training cutoffs. LiveBench updates monthly with fresh questions across six categories; LiveCodeBench pulls from recent competitive programming contests. As of 2026, static benchmarks like MMLU are saturated above 88% for frontier models and are being supplemented by MMLU-Pro and contamination-resistant alternatives.
Rule of thumb: If the benchmark is older than the model’s training data, treat the score as an upper bound, not a measurement.
When it breaks: Detection methods like n-gram overlap and output distribution analysis catch verbatim and near-verbatim contamination, but soft contamination — semantic duplicates with different surface text — remains difficult to detect at scale. No public contamination audit exists for frontier models; labs rarely disclose training data composition. An Ablation Study can isolate whether performance on a specific benchmark survives paraphrasing, but this requires building parallel test sets for every evaluation — an effort most teams skip.
The Data Says
Benchmark contamination is not a technical footnote. It is a measurement crisis. When 72.5% of a major benchmark’s questions trigger memorization signals, and scores drop 14-17 percentage points on decontaminated versions, the gap between reported performance and actual capability is large enough to change model selection decisions. The score is not the signal. The score’s robustness to rephrasing is.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors