What Is an Evaluation Harness and How Standardized Frameworks Benchmark LLMs
Table of Contents
ELI5
An evaluation harness is a standardized framework that runs identical tests across different language models — same questions, same scoring, same conditions — so their results are actually comparable.
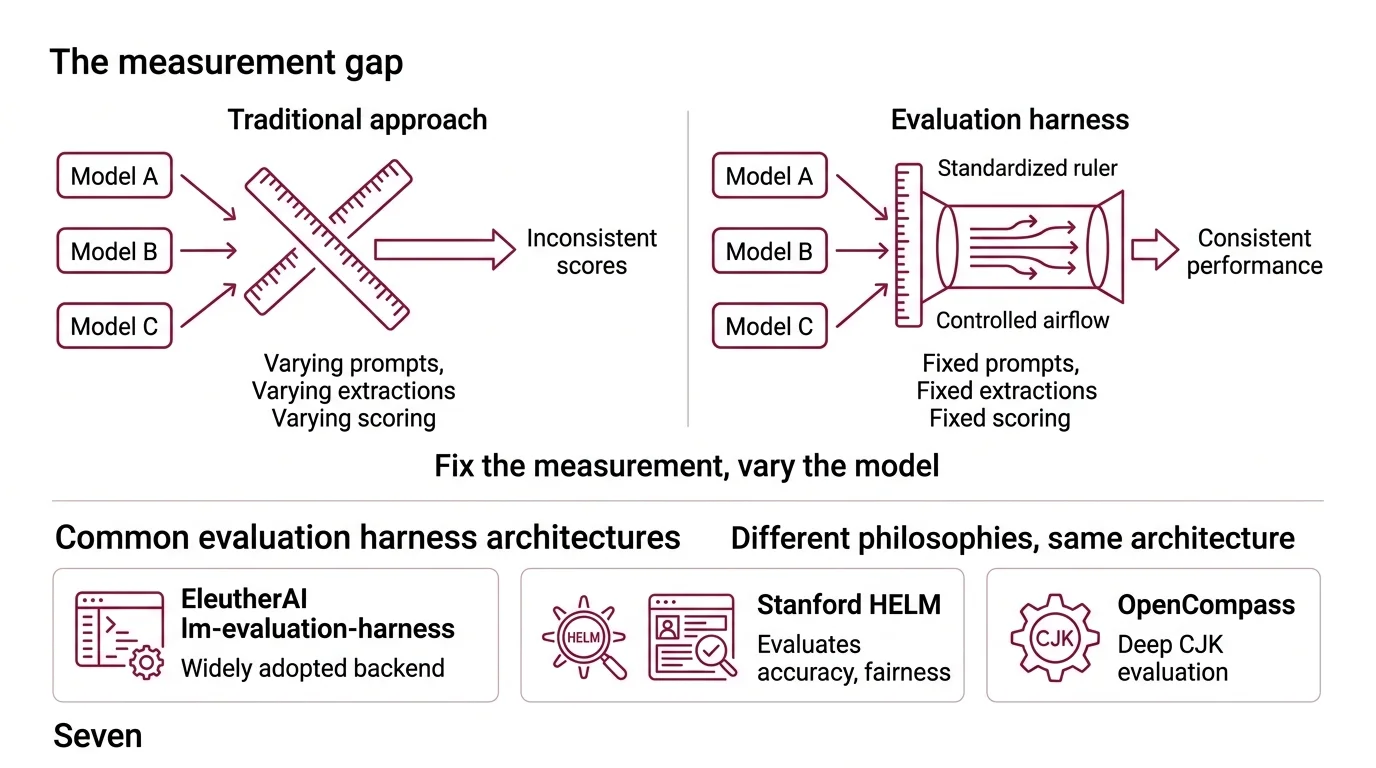
Two teams benchmark the same model on the same task. One reports 87% accuracy. The other reports 71%. Neither team made a measurement error — they used different prompting formats, different few-shot examples, different answer-extraction logic. The discrepancy isn’t a flaw in the model. It’s what happens when you measure without a standard.
The Measurement Gap That Leaderboards Forced Open
The instinct is to blame the model. A score looks low, and the assumption is that the model underperformed. But performance is always a function of two entangled variables: the model’s actual capability and the measurement’s consistency. Change how you phrase the question, how you extract the answer, or how you handle partial credit, and the same model produces a different number — not because it changed, but because the ruler did.
This is the problem that evaluation harnesses were built to solve, and the reason Model Evaluation cannot be reduced to “run a benchmark and read the score.”
What is an evaluation harness for large language models
An evaluation harness is a software framework that standardizes every variable in the measurement process except the model itself. It fixes the prompt template, the few-shot examples, the answer-extraction method, the scoring function, and the aggregation logic — then swaps models through a uniform interface.
Think of it like a wind tunnel. Aerospace engineers don’t test drag by flying different aircraft through different weather on different days. They fix the airflow, the temperature, the sensor placement — and change only the wing geometry. The harness is the controlled airflow. The model is the wing.
EleutherAI’s lm-evaluation-harness is the most widely adopted implementation and serves as the backend for the Open LLM Leaderboard (EleutherAI GitHub). Stanford’s HELM approaches the same problem from a different direction — rather than optimizing for a single accuracy metric, it evaluates across accuracy, calibration, fairness, and efficiency simultaneously (Stanford CRFM). OpenCompass, as of v0.5.2, covers 100+ datasets with particular depth in CJK language evaluation (OpenCompass Docs). Different philosophies, same underlying architecture: fix the measurement, vary the model.
Not a testing tool. A calibration standard.
Seven Stages Between a Question and a Score
Most people encounter evaluation results as single numbers on a leaderboard — a model scored 78.3, another scored 81.1, and the conclusion seems obvious. What that number conceals is the pipeline that manufactured it: a sequence of stages, each one a potential source of variance that the harness is engineered to eliminate.
How does an LLM evaluation harness run standardized benchmarks across different models
The pipeline flows through a fixed sequence: configuration loading, task instantiation, model interface binding, batch processing, filter application, metric computation, and result aggregation (Earl Potters Blog).
Configuration comes first — typically a YAML file that defines the entire task specification. In lm-evaluation-harness, this means specifying doc_to_text (a Jinja2 template that converts raw dataset rows into the exact prompt string the model sees), doc_to_target (the expected correct answer), a filter pipeline for post-processing model outputs, and the metrics to compute. The YAML isn’t decoration. It is the document that makes reproducibility mechanical rather than aspirational — anyone with the same config file and the same dataset version will produce the same measurement conditions.
The model interface layer is where the harness earns its name. Rather than requiring custom integration code for every model, the framework abstracts model interaction into three primitives: generate_until (open-ended text generation that stops at a defined delimiter), loglikelihood (probability scoring of a specific continuation given a context), and loglikelihood_rolling (perplexity-style scoring across a full sequence without conditioning on a prompt). Any model that implements these three methods slots into any benchmark the harness supports. The model doesn’t need to know which benchmark is running; the harness handles that translation.
Batch processing runs thousands of prompt-response pairs through the model under controlled conditions. Filter application then post-processes the raw outputs — stripping whitespace, normalizing case, extracting answer tokens from verbose responses. Filters are the unglamorous workhorses that prevent a model from scoring zero on a multiple-choice task because it prefixed every answer with “The correct answer is: " instead of returning the bare letter.
Metric computation converts filtered outputs into numbers — exact match accuracy, Precision, Recall, and F1 Score, log-likelihood scores, or task-specific metrics derived from a Confusion Matrix. Result aggregation normalizes these across tasks and produces the final score. The Open LLM Leaderboard normalizes to a 0-100 scale to make cross-benchmark comparison possible across tasks with different raw-score ranges.
What are the main components of an evaluation harness pipeline
Strip away the implementation specifics and five architectural components remain constant across every major framework:
Task registry — a catalog of benchmarks, each fully specified by its prompt template, dataset source, and scoring function. EleutherAI’s harness ships with hundreds of task definitions. The MMLU Benchmark alone, in its MMLU-Pro variant, spans 12,000 questions across 10 answer choices and 14 domains (TIGER-Lab). What matters structurally is that adding a new benchmark means writing a configuration file, not modifying framework code — the registry is extensible by design.
Model abstraction layer — the interface contract that decouples benchmarks from model-specific APIs. HELM wraps models through scenario-specific adapters. Inspect AI, built by the UK AI Security Institute, provides over 100 pre-built evaluation templates with a composable architecture (UK AISI). Deepeval integrates directly into pytest, treating each evaluation as a unit test — a design decision that trades general-purpose flexibility for CI/CD compatibility.
Prompt template engine — the system that converts raw data into the exact string the model receives. Jinja2 templates in lm-evaluation-harness allow conditional formatting, few-shot example injection, and task-specific instructions — all version-controlled alongside the benchmark definition. The template is the boundary between the dataset and the model; changing one word in it can shift scores by several points.
Scoring and metric system — the layer that maps model outputs to numeric assessments. This spans everything from simple exact-match counting to multi-metric evaluation; HELM scores on dozens of dimensions per scenario, including calibration and toxicity measurements. The choice of metric shapes the ranking — a model that leads on accuracy may fall behind on calibration, and the harness makes both visible.
Filter pipeline — the answer-extraction logic that normalizes raw model outputs before scoring. This is the component most likely to cause score discrepancies when different frameworks run the same benchmark, because different filter implementations parse identical model output differently. A regex that expects "A" will miss "(A)", and that miss propagates silently to the final score.
Where Standardization Meets Its Own Edge Cases
The architecture above predicts several things. If you change the prompt template for an existing benchmark — even rephrasing without altering meaning — expect score shifts. Research on Benchmark Contamination has shown that models can be acutely sensitive to exact prompt wording, and the harness can only control what it explicitly specifies. Contamination detection tools exist precisely because the harness guarantees identical test conditions but cannot guarantee the model hasn’t memorized the test itself.
If you evaluate a model using generate_until versus loglikelihood, expect different rankings. Some models generate correct answers fluently but assign lower log-probabilities to those answers than competing models do; others score well on probability metrics but produce awkward free-text responses. The interface you choose is not neutral — it measures a different facet of the same capability.
If you compare scores across harnesses — EleutherAI’s result for Model A against HELM’s result for the same model — treat the comparison with suspicion. Different filter pipelines, different prompt templates, and different metric normalizations mean the numbers occupy different measurement scales. The score is meaningful within the framework that produced it. Outside that context, it’s a number without a reference frame.
Running an Ablation Study on your evaluation configuration — removing one filter, swapping one prompt template, disabling one normalization step — often reveals that components you assumed were inert contribute more to the final score than the ones you designed carefully. The harness controls the measurement. It doesn’t make the measurement automatically meaningful.
Rule of thumb: trust score comparisons within a single harness version. Treat cross-harness comparisons as directional signals, not precise measurements.
When it breaks: evaluation harnesses assume the benchmark itself is a valid proxy for the capability you care about. When a benchmark saturates — models cluster near the ceiling — the harness faithfully reports near-identical scores that reveal almost nothing about meaningful capability differences. The measurement stays precise. The thing being measured stops being informative. No amount of pipeline engineering fixes a test that no longer discriminates.
Security & compatibility notes:
- lm-evaluation-harness v0.4.10+: The base package is now lightweight —
pip install lm_evalno longer includes the HuggingFace/PyTorch stack. Install backends explicitly (e.g.,lm_eval[hf]).- OpenCompass v0.4.0: Configuration paths were restructured and consolidated into the package. Older tutorials referencing
./configs/may point to deprecated locations.
The Data Says
An evaluation harness does not make a model better or worse. It makes the measurement honest enough to be falsifiable — same prompt, same scoring, same conditions, different model. The engineering is unglamorous: YAML configurations, filter pipelines, normalized metrics. But without it, every benchmark score is a number with no denominator, and comparing models becomes an exercise in comparing the setups that measured them. The harness is the denominator.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors