What Is an Ablation Study and How Removing Components Reveals What Makes AI Models Work
Table of Contents
ELI5
An ablation study removes one piece of an AI model at a time and measures what changes — like pulling fuses from a circuit board to find which fuse powers which room.
A 200-million-parameter model passes your benchmark. You’re reasonably satisfied. Then someone asks a sharper question: which part of the architecture is responsible for that performance? The attention heads? The skip connections? The dropout schedule? You cannot point to any single component and say with certainty what it contributes — because watching a working system work tells you almost nothing about why it works. The answer, counterintuitively, begins with breaking it.
Borrowed from Brain Surgery
The technique predates machine learning by roughly two centuries. Experimental neuropsychologists pioneered ablation by destroying specific regions of animal brains and observing which behaviors vanished — mapping function to structure through targeted destruction (Wikipedia). The method was brutal, but the epistemological logic was sound: if removing a region eliminates a behavior, that region is implicated in producing it.
The concept crossed into AI through a 1974 speech-recognition tutorial, published in 1975 by Allen Newell, who argued that computational systems obey the same logic: remove a module, measure the degradation, and the delta between intact and damaged performance is your evidence (Wikipedia).
The transplant from neuroscience to computer science is not merely metaphorical. It rests on a shared insight that most engineers underestimate: presence alone does not prove contribution. A component might be critical, redundant, or quietly harmful — and the only reliable way to distinguish these states is to observe the system without it.
That insight raises an immediate practical question: how do you measure absence precisely enough to trust the result?
The Arithmetic of Subtraction
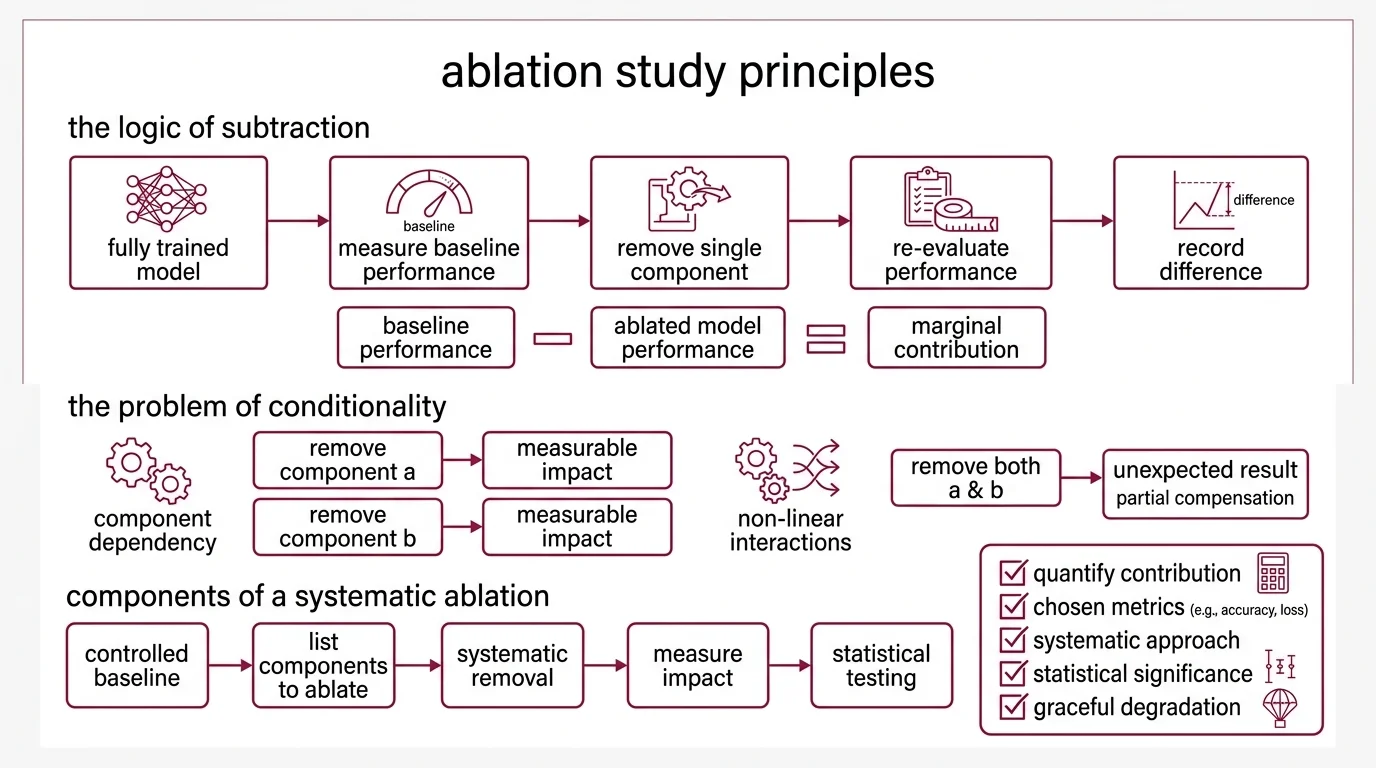
The logic is deceptively clean. Start with a fully trained model at its measured Baseline Model performance. Remove a single component — one attention head, one layer, one preprocessing step. Re-evaluate. Record the difference between the baseline and the ablated version.
That difference is the component’s marginal contribution.
But simplicity in description masks conditionality in practice. The contribution of any component depends on what else remains in the system. Remove dropout and accuracy drops by some measurable amount. Remove both dropout and batch normalization and accuracy drops less than expected — because the two were partially compensating for each other. Interactions are non-linear, and every ablation result is conditional on the configuration that surrounds it.
What is an ablation study in machine learning?
An ablation study is the systematic removal of individual components from a machine learning system to quantify each component’s contribution to overall performance. The definition is precise: degrade the system along one axis and measure the impact on a chosen metric — accuracy, Precision, Recall, and F1 Score, loss, or any other evaluable output.
The word “systematic” matters. A proper ablation is not trial-and-error tinkering; it requires a controlled baseline configuration, a predetermined list of components to ablate, and Statistical Significance testing on the results. NeurIPS requires error bars, confidence intervals, or statistical significance tests for main claims in submitted papers (NeurIPS Checklist). ICML 2026 encourages code submission and weighs reproducibility in decisions (ICML 2026). The expectation across top venues is that architecture claims come with ablation evidence — not anecdote.
One prerequisite is easy to overlook: the system must exhibit graceful degradation — it must continue functioning when components are removed or degraded (Wikipedia). A model that crashes entirely when you remove a layer tells you that layer is necessary for execution, not that it is responsible for any particular learned capability.
Not structural importance. Functional importance. The ablation study measures the second.
How does an ablation study measure the contribution of each model component?
The measurement follows a pattern that is consistent across most implementations:
- Establish the baseline. Train and evaluate the complete model. Record performance on your chosen metrics across a held-out evaluation set.
- Define ablation targets. Enumerate every component under investigation — layers, attention heads, Regularization techniques, data augmentation strategies, loss function terms, preprocessing steps.
- Remove one component. Retrain the model (or, in some designs, simply re-evaluate the existing weights) with that component absent.
- Record the delta. The performance gap between the baseline and the ablated variant isolates the removed component’s marginal contribution.
- Repeat. One ablation per component, one delta per row in the results table.
The resulting table — component in one column, performance delta in the next — maps the architecture’s internal dependencies. Neural networks, it turns out, selectively represent features in specific areas of their architecture, and some of those representations are redundant, providing robustness to structural damage; damaged networks can even recover capability through retraining (Meyes et al.).
That redundancy finding matters. Redundancy in a neural network is not waste. It is distributed insurance — and ablation is the method that reveals where the policies are written. If your ablation table shows that two components have individually small deltas but a combined removal produces a large delta, you’ve detected a compensatory relationship that a leave-one-out design alone would miss.
Designing the Experiment
Leave-one-out is the default protocol, but its limitations surface quickly in architectures with hundreds of interacting components. The design decisions researchers make before running a single experiment determine whether the results are informative or misleading.
How do researchers design leave-one-out ablation experiments for neural networks?
The classic design removes exactly one component per experiment while holding everything else constant. For a network with n ablation targets, this requires n + 1 evaluated configurations — one baseline plus one per ablation. Computational cost scales linearly with the number of targets; manageable for small models, prohibitive for large ones.
Three decisions shape the experiment:
Retraining versus re-evaluation. After removing a component, do you retrain the remaining model from scratch or evaluate the incomplete model using existing weights? Retraining measures the component’s unique contribution, accounting for the model’s capacity to compensate. Re-evaluation measures raw dependency — how much the current trained solution relies on the removed piece. Both answers are informative; they address different questions, and conflating them is a common source of misinterpretation.
Granularity. A transformer ablation might target entire layers, individual attention heads, or specific weight matrices within a single head. Finer granularity yields higher-resolution functional maps but multiplies the required experiments. The choice is a tradeoff between insight and compute.
Interaction effects. Leave-one-out assumes additive, independent contributions — an assumption that complex models routinely violate. Factorial designs that test component pairs or groups can capture synergistic and antagonistic interactions, but the combinatorial explosion makes full factorial ablation impractical beyond small architectures. In practice, researchers run single-component ablations first, then conduct targeted interaction tests where the initial results suggest dependencies.
The tooling layer for ablation studies is still maturing. ABLATOR, a PyTorch-based framework, automates stateful experiment design with automatic result artifacts — though it remains a niche project with limited community adoption as of late 2023 (ABLATOR Docs). AblationMage, presented at ACM EuroMLSys in 2025, proposes using large language models to semi-automate the planning and execution of ablation experiments (ACM Digital Library), an approach that could lower the barrier for teams without dedicated infrastructure — though full methodology details from the original paper remain behind a paywall.
What Disappearance Predicts
The practical value of ablation extends well beyond architecture papers. If you know which components carry the largest deltas, you can make informed decisions about model compression, pruning, and knowledge distillation. A component with a negligible ablation delta is a candidate for removal where inference cost matters. A component with a large delta is a bottleneck — and understanding why it matters opens the path to targeted improvement.
If you remove a regularization technique and validation performance barely shifts, you are paying a training-time cost for no generalization benefit. If you remove a data augmentation step and the Confusion Matrix shifts dramatically on a specific class, you have isolated a data dependency rather than an architectural one. If a component’s ablation delta is large on a standardized test like the MMLU Benchmark but negligible on your domain-specific evaluation, that component may be optimizing for benchmark structure rather than the capability you actually need — a signal that warrants checking for Benchmark Contamination.
The if/then structure is the point. Ablation transforms Model Evaluation from does it work? to why does it work? — and the second question is the one that generalizes to new problems.
Rule of thumb: if your architecture paper lacks an ablation table, reviewers at top venues will ask for one. Ablation is not optional in serious model evaluation; it is expected.
When it breaks: ablation studies assume that component contributions are separable enough to measure in isolation — and large models violate this assumption routinely. When two components compensate for each other, removing either individually shows minimal impact, but removing both collapses performance. Leave-one-out designs are structurally blind to these interaction effects. Factorial designs that could catch them scale combinatorially, making them impractical for models with hundreds of ablation targets. The method is powerful within its assumptions, and fragile outside them.
The Data Says
Ablation studies are the empirical mechanism for distinguishing necessary architecture from architectural accident. They cannot map every interaction in a system where components compensate, compete, and collude — but they remain the most direct method for answering the question that matters: which pieces of this model are actually doing the work, and which ones are along for the ride.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors