What Is AI Test Generation and How LLMs Write Unit and Integration Tests from Code

Table of Contents
ELI5
AI test generation is the practice of using a Large Language Model to write unit and integration tests for existing source code. The model proposes candidates; an automated filter discards the ones that do not compile, pass, or increase coverage.
A developer pastes a Java class into a chat window and asks for unit tests. The model produces a tidy @Test block, complete with imports, assertions, and a docstring that sounds vaguely confident. The test compiles. The test runs. The test passes. And then someone notices that the assertion is checking a value the method never returns — the model invented the contract it was supposed to verify. Nothing is broken. Nothing is true either.
This is the central anomaly of AI test generation, and it is the reason the field exists as a discipline rather than as a feature of autocomplete.
The Anomaly: Tests That Compile but Lie
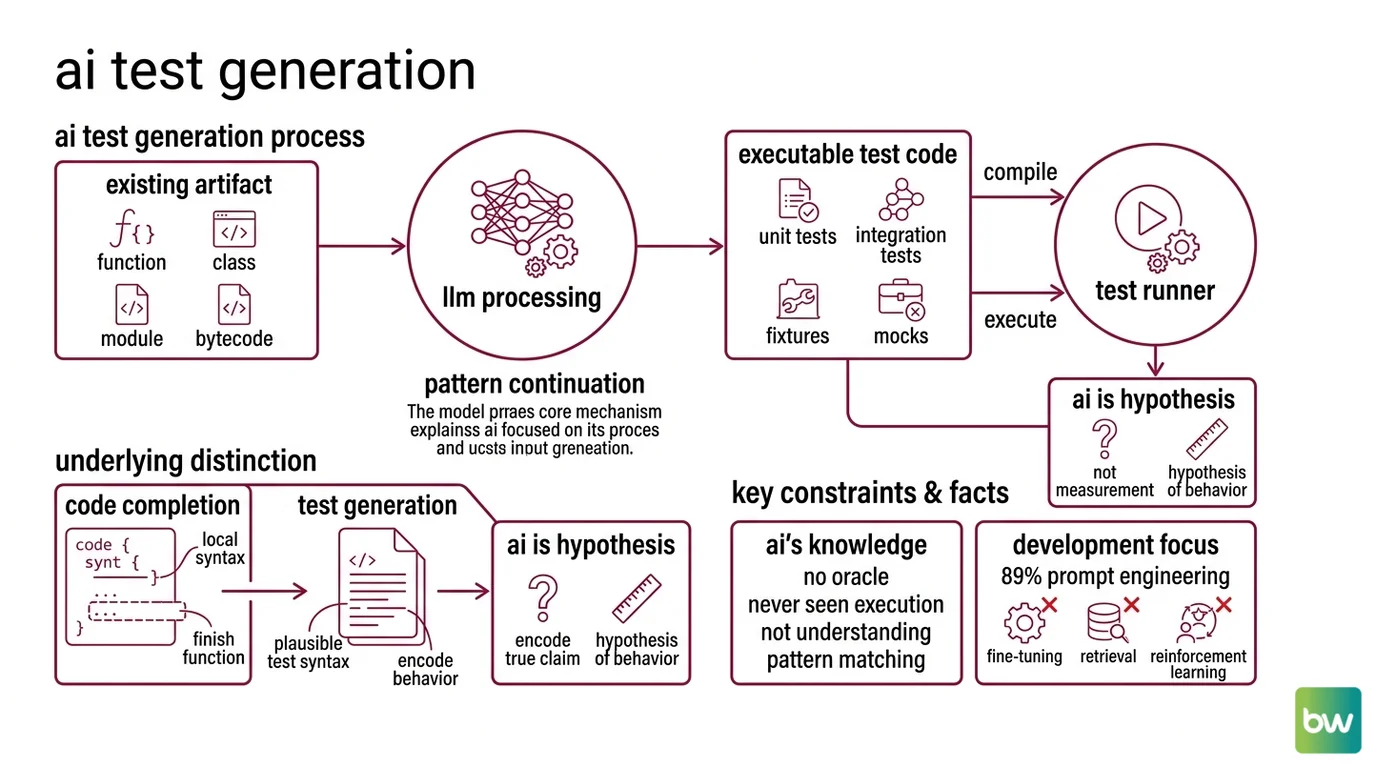
The earliest reflex was to treat test writing as a natural extension of
AI Code Completion — if the model can finish a function, surely it can finish a should_return_empty_list_when_input_is_null method. The reflex was correct about the surface. It was wrong about the mechanism. Code completion only needs to be plausible inside the local syntax. A test needs to be plausible and to encode a true claim about behavior the model has never directly observed.
The recent literature has caught up to this distinction. A survey of 115 publications between May 2021 and August 2025 found that prompt engineering — not fine-tuning, not retrieval, not reinforcement learning — accounts for roughly 89% of LLM-based unit test generation work (arXiv survey 2511.21382). The dominant strategy is not to teach the model to test; it is to stage the input so that the next-token distribution drifts toward plausible test syntax.
That distinction matters because it tells us what the model is doing, and what it is not.
What is AI test generation?
AI test generation is the use of an LLM to produce executable test code — unit tests, integration tests, fixtures, mocks — from an existing artifact: a function, a class, a module, sometimes bytecode. The output is not a test plan, not a coverage report, not a description of what could go wrong. It is source code that an existing test runner (pytest, JUnit, xUnit, Go’s testing, RSpec) can compile and execute.
The model has no oracle. It has never seen the system under test execute. It produces a string that looks like a test and is shaped by the statistical regularities of millions of tests it has read.
Not understanding. Pattern continuation.
Two consequences fall out of that fact immediately. First, an LLM-written test is a hypothesis about the code’s behavior, not a measurement of it — which is why the most cited failure mode in recent empirical work is syntactically invalid output from hallucinated APIs (arXiv 2406.18181). Second, no responsible system trusts the model’s output as-is. Every production deployment described in the literature wraps the generator in a filter.
The Two-Phase Pipeline
The arXiv survey (2511.21382) imposes a useful taxonomy on the field: a generative phase that turns code into test artifacts, and a quality-assurance phase that refines or rejects them. Almost every system described in the literature, regardless of vendor, fits this skeleton. The interesting design choices are inside each phase, not in the shape itself.
How do LLMs generate unit tests from source code?
The generative phase reads a target — function, class, file, or, in Diffblue Cover’s case, compiled Java bytecode — and assembles a prompt that contains some combination of: the code itself, the surrounding context (imports, sibling classes, type signatures), conventions extracted from the existing test suite, and an instruction template. The LLM then samples a candidate test in the project’s idiom.
Idiom detection is what distinguishes a serious tool from a toy. GitHub Copilot’s /tests slash command reads project conventions to decide whether to emit Jest, pytest, JUnit, Go’s testing, RSpec, or xUnit syntax (GitHub Docs). It does not pick a framework; it infers one. The inference is itself a probability estimate from prior tokens in the repository.
For Java, the pattern diverges. Diffblue Cover does not parse source files at all. It analyzes bytecode and uses reinforcement learning to select inputs that cover testable execution paths through the compiled artifact (Diffblue Docs). The LLM, where it appears, is a renderer of the resulting test logic — not the originator of the test strategy. The model writes the words; the search algorithm decides what claim the words are supposed to encode.
This is the structural answer to a question that gets asked repeatedly: do LLMs really generate tests, or do they format them? In practice, in mature systems, they format constrained candidates produced by a search loop. The pure “prompt the model, accept the output” approach exists, but mostly in the studies the survey classifies as exploratory.
What are the main components of an AI test generation system?
Below the marketing surface, a production AI test generation system is a pipeline of separable components. Listing them is more instructive than naming products.
| Component | Function | Example implementation |
|---|---|---|
| Context extractor | Pulls the target function, signatures of called methods, existing tests, project conventions | Copilot reading repo + test files; Diffblue Cover decompiling bytecode |
| Prompt assembler | Inserts target + context + few-shot examples into a structured template | Vendor-specific; ~89% of studies use this approach per arXiv survey 2511.21382 |
| LLM sampler | Generates candidate test source code | Project-tuned model, Claude, GPT-class model, or local LLM |
| Compile/build filter | Discards candidates that do not parse, type-check, or compile | Mandatory in Meta TestGen-LLM, Qodo Cover, Diffblue Cover |
| Execution filter | Discards candidates that throw on first run or fail deterministically | Same |
| Coverage delta gate | Keeps only tests that strictly increase coverage of the existing suite | Meta TestGen-LLM’s “assured improvement” principle |
| Repair loop | Feeds compile or runtime errors back into the model for a fixed number of retries | Common across recent systems; ties to the QA phase of the survey taxonomy |
The component most newcomers underestimate is the coverage delta gate. A generated test that compiles, passes, and exercises a path already covered by the existing suite is noise — possibly harmful noise, because it lengthens CI runs and trains reviewers to skim. Meta’s TestGen-LLM design treats this as the central problem: the system only forwards candidates that pass build, pass execution, and increase coverage on the target class (Meta TestGen-LLM paper).
What the Filter Geometry Predicts
Once the pipeline is laid out as a sampler followed by a cascade of filters, the system’s behavior becomes much easier to reason about. The model is not a test author; it is a candidate generator inside an acceptance region defined by the build system, the runtime, and the coverage tooling. Most of the field’s results are consequences of where that acceptance region falls.
When Meta deployed TestGen-LLM internally on Instagram Reels and Stories, 75% of generated test cases built correctly, 57% passed reliably, and 25% measurably increased coverage on the target class (Meta TestGen-LLM paper). Across the broader Meta deployment, the system improved 11.5% of all classes it ran against, and 73% of its surviving recommendations were accepted by engineers into production. Those numbers describe the geometry of the filter, not the genius of the model. The model emits a distribution; the filter slices it.
A second prediction follows from the same shape. If you compare LLM-based generators to traditional Search-Based Software Testing (SBST) tools like EvoSuite — which evolve inputs through a fitness function rather than a language prior — the LLM systems trail on raw line and branch coverage but tend to score higher on mutation kill rate (Test Wars study, arXiv 2501.10200). The geometric reading: SBST optimizes directly for coverage and gets it; LLMs optimize for plausible-looking assertions and accidentally encode more semantic intent, which catches more injected faults.
The Meta evaluation numbers come from one product surface inside one company. Pre-2025 figures, and figures across other studies, vary by language, prompt strategy, and model — there is no industry-wide benchmark to point to yet.
If/then predictions fall out of this directly:
- If the system under test has unusual or framework-internal idioms, then expect the failure mode to be syntactically invalid tests from hallucinated APIs (arXiv 2406.18181).
- If the target code is well-typed and has an existing test file as few-shot context, then expect a much higher build-rate than the 75% Meta floor.
- If the project lacks a coverage instrument the generator can read, then the assured-improvement filter cannot fire, and the acceptance gate degrades to “compiles and passes” — which lets through tautological tests.
- If you measure success by mutation score rather than coverage, then LLM-based tools become more competitive against SBST baselines than the coverage-only comparison suggests.
Rule of thumb: treat the LLM as a candidate proposer, not as the verifier. The verifier is the build, the runtime, and the coverage delta.
When it breaks: the dominant failure mode is the syntactically invalid test from a hallucinated API call — the model invents a method on a real class or imports a package that does not exist. The empirical literature converges on this as the largest single source of wasted candidates (arXiv 2406.18181). The deeper limitation is that no filter in the pipeline can certify semantic correctness of an assertion. A test that compiles, runs, passes, and increases coverage can still encode the wrong specification — and if developers accept it, the wrong specification becomes the test suite’s ground truth.
The Tools in Play (as of May 2026)
A short orientation to the systems most often referenced in the literature and product docs, with no pricing claims — vendor pages change too often for any quoted number to age well.
- Meta TestGen-LLM — Internal Meta tool, the canonical “assured improvement” reference architecture. Closed-source. The 2024 paper is the most-cited point of departure for serious work in the field.
- Qodo Cover — Open-source TestGen-LLM implementation (formerly under the CodiumAI brand). After the Qodo 2.0 release in February 2026, the parent product naming was unified into a single “AI Code Review Platform” — older module names (Qodo Merge, Qodo Gen, Qodo Command) are deprecated even though documentation references may still appear (Qodo Blog).
- Diffblue Cover — Enterprise Java tool. Bytecode-level analysis with reinforcement learning; ships as IDE plugin, CLI, and CI pipeline, and runs locally — no source code leaves the developer’s environment (Diffblue Docs).
- GitHub Copilot — General-purpose. The
/testsslash command spans multiple languages; the dedicated .NET test-generation feature went generally available in Visual Studio 2026 v18.3 for xUnit, NUnit, and MSTest (Microsoft .NET Blog).
The research roadmap published in arXiv 2509.25043 names the field’s three unresolved problems: the test oracle (how do we know the assertion is right?), flakiness (do these tests stay green for the right reasons?), and long-term maintainability (do they survive refactors without becoming change-detectors?). None of these are filter problems. They are specification problems, and the literature is honest that LLM test generation, at present, does not solve them — it accelerates them.
The Data Says
AI test generation is best understood as a constrained sampling process: an LLM proposes candidate tests, and a pipeline of build, execution, and coverage filters decides which proposals survive. The measured benefit at Meta — 11.5% of classes improved with 73% of recommendations accepted — comes from the filter, not from the model’s intuition. Code review for the resulting tests is not optional; it is what the filter cannot do, which is why most mature deployments still treat the output as input to AI Code Review rather than as finished work.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors