What Is AI in CI/CD Pipelines and How Automated Code Analysis and Deployment Checks Work
ELI5
AI in CI/CD pipelines uses machine-learning models trained on build and test history to predict which commits are risky, which tests to run first, and which failures are real — turning a binary pass/fail gate into a probability-weighted forecast.
Push a one-line change to a stylesheet and a well-configured pipeline might run eight thousand tests, none of which touch styling. Push a schema migration that could corrupt production data, and the same pipeline runs those same eight thousand tests with exactly the same urgency. Both commits get one verdict — green or red — because a traditional pipeline has no memory and no sense of risk.
That symmetry is the anomaly. Two changes with wildly different blast radii receive identical treatment. There is a tempting story about why AI shows up here: that it writes the code, runs itself, and ships without you. That story is wrong, and the reason it is wrong tells you exactly what AI is actually doing inside the pipeline.
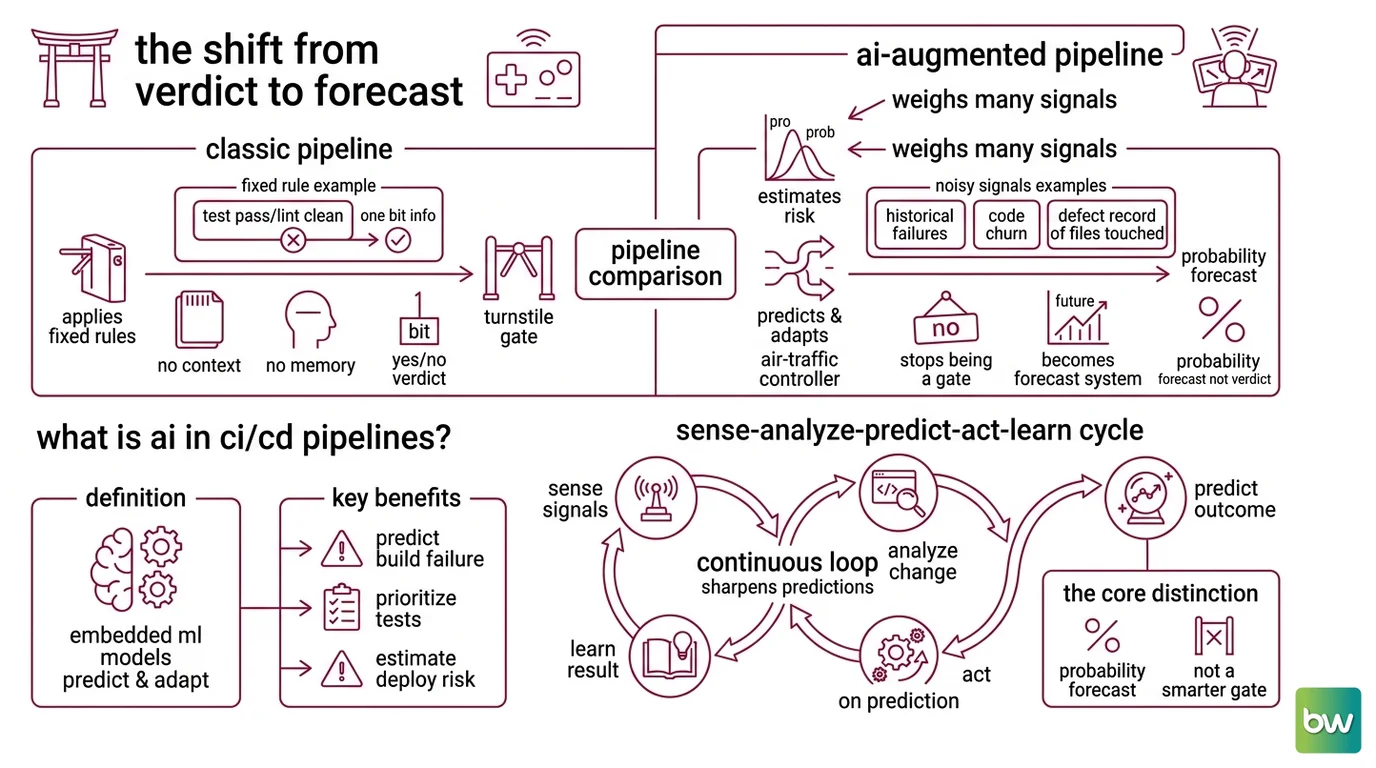
The Shift From Verdict to Forecast
A classic Continuous Integration pipeline is a turnstile. It applies a fixed rule — these tests must pass, this lint must be clean — and emits one bit of information. Valid ticket or not. The turnstile has no opinion about which traveler is likely to cause trouble, because it cannot remember any traveler it has ever seen.
An AI-augmented pipeline behaves more like an air-traffic controller. It weighs many noisy signals — historical failures, code churn, the defect record of the files you touched — and produces a continuous estimate of risk rather than a single yes/no. The pipeline stops being a gate that opens or closes. It becomes a system that forecasts.
What is AI in CI/CD pipelines?
AI in CI/CD pipelines is the practice of embedding machine-learning models and code-focused language models into the build, test, and Continuous Deployment cycle so the pipeline predicts and adapts instead of only executing static rules. The models learn from the telemetry every pipeline already produces — pass/fail logs, durations, commit metadata — and use it to estimate things a rule cannot: how likely this build is to fail, which tests are worth running first, how risky this particular deployment is.
One representative way to frame the loop comes from recent academic work, which describes a Sense → Analyze → Predict → Act → Learn cycle (Frontiers in AI). Sense the signals, analyze the change, predict the outcome, act on the prediction, then feed the result back so the next prediction is sharper. Treat it as a useful mental model, not an industry standard — it is one proposed framework among several.
The distinction that matters is small and easy to miss. The pipeline is producing a probability forecast, not a verdict. Not a smarter gate. A probability estimator.
How the Pipeline Reads Risk Before It Runs
Before a single test executes, an AI pipeline has already formed an opinion about your commit. That opinion is assembled from several specialized models, each trained on a different slice of pipeline history, each answering a narrower question than “is this good?”
How does AI analyze code and predict deployment risk inside a CI/CD pipeline?
The work splits across a handful of models that operate on the same underlying telemetry but predict different things.
Test Prioritization reorders the suite so the tests most likely to fail run first. The models here are familiar supervised learners — random forests, gradient boosting, and neural networks, sometimes pretrained across projects so a new repository inherits priors from older ones (Frontiers in AI). The payoff is feedback latency: a likely failure surfaces in the first minute instead of the fortieth.
Build failure prediction asks a different question — will this pipeline run break at all? One studied approach uses an LSTM recurrent network (the DL-CIBuild model), a Code LLMs cousin built to read sequences, in this case the temporal sequence of past builds. Studies report roughly 75% cross-project accuracy — a research figure, not a vendor guarantee, and worth treating as such.
Flaky Test Detection tackles the most maddening anomaly in testing: a test that passes and fails on identical code. Hybrid models combine machine learning with historical pattern analysis to separate genuine regressions from noise, with studies reporting precision in the 73–91% range. The goal is ranking risk before the code runs, not explaining a failure after the fact.
Deployment Risk Assessment sits closest to production. It scores a change by combining signals — code churn, the defect history of the touched files, complexity, who last changed them — into a single estimate of how dangerous it is to ship right now.
Code analysis adds the language-model layer. GitHub Copilot Autofix, for instance, generates suggested fixes by combining the surrounding codebase with CodeQL scan results and proposes them directly inside the pull request (GitHub Docs). GitLab Duo runs a Root Cause Analysis that reads CI/CD logs, errors, and recent changes to pinpoint why a pipeline failed (GitLab Docs). Behind these features sit general-purpose code models: on the SWE-bench Verified leaderboard, Claude Opus 4.6 leads at 81.4% as of May 2026, with Gemini 3.1 Pro close behind on a native million-token context, and GitLab’s Duo platform has since added Claude Opus 4.7. The model names move fast; the mechanism underneath does not.
The Parts List of a Predictive Pipeline
It helps to see the pieces as a stack, because each layer feeds the one above it. Strip any layer out and the forecast degrades in a predictable way.
What are the building blocks of an AI-powered CI/CD pipeline?
A predictive pipeline is built from five cooperating layers:
| Layer | What it does | Example |
|---|---|---|
| Telemetry | Collects build logs, test outcomes, commit metadata — the raw fuel | Historical pass/fail records |
| Signal extraction | Turns raw history into features: code churn, file ownership, complexity | Per-file defect rates |
| Prediction models | Estimate test priority, build failure, flakiness, deployment risk | Random forests, LSTM, gradient boosting |
| Code-language models | Read and explain code: suggest fixes, analyze failures | Copilot Autofix, Duo Root Cause Analysis |
| Action layer | Surfaces predictions and routes remediation | Self Healing Pipelines |
The action layer is where the autonomy myth dies cleanly. Self-healing pipelines can retry a transient failure, quarantine a flaky test, or open a fix — but in production, those fixes route through pull-request review with a human holding merge authority. The pipeline proposes; a person disposes.
Holding the stack together is Pipeline As Code: when the pipeline itself is versioned configuration, the learn loop becomes reproducible, because every prediction can be traced back to the exact pipeline state that produced it. And every prediction is only as good as its telemetry — the data layer is not the boring part of the stack, it is the part that decides whether the rest works.
The language-model layer also carries security weight, since some of these tools execute commands or touch your repository directly:
Security & compatibility notes:
- GitHub Copilot CLI (CVE-2026-45033): Arbitrary code execution via a nested bare repo. Fix: upgrade to v1.0.43 or later.
- GitHub Copilot CLI (CVE-2026-29783): Shell-expansion remote code execution. Fix: upgrade to v0.0.423 or later.
- Model names drift: Older Copilot model names (Claude Sonnet 4, Gemini 3 Pro) were deprecated in 2026 — pin to current model identifiers, not ones copied from older blog posts.
What a Probabilistic Pipeline Predicts About Your Builds
Once you see the pipeline as a forecaster rather than a gate, its behavior becomes predictable in a useful way. The model is estimating conditional probabilities from history, so its strengths and its failure modes both follow from the data it learned on.
- If you push a commit touching files with a long defect history, expect the pipeline to rank those tests first and raise the deployment-risk score — even if your change looks trivial.
- If your suite is full of nondeterministic tests, expect flaky detection to absorb much of the noise, but also expect a quieter risk: real regressions occasionally hiding inside the flaky bucket.
- If your historical data is thin or skewed — a young repo, a recent rewrite — expect the predictions to inherit that skew and read as more confident than they deserve.
Rule of thumb: an AI pipeline is exactly as calibrated as the telemetry it learned from — no more.
When it breaks: the sharpest failure mode is distribution shift. When a codebase changes character — a new language, a major refactor, a migrated framework — the model’s historical priors stop matching reality. Risk scores then become confidently wrong, prioritizing the wrong tests and under-rating genuinely dangerous changes, until enough new history accumulates to retrain. A probabilistic forecast read as a guarantee is not a tooling failure; it is a category error on the reader’s side.
The Data Says
AI in CI/CD does not replace the pipeline’s logic — it adds a probabilistic layer on top of it, estimating risk from the history the pipeline was already generating. The accuracy figures are real but research-bound, and the autonomy is bounded by human merge authority. Read the scores as forecasts, calibrate them against your own telemetry, and the pipeline stops treating every commit as an identical stranger.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors