What Is AI Image Editing? Inpainting, Outpainting, Edit Models
ELI5
AI image editing uses a generative model to alter part of an image while preserving the rest. Tell it where or what to change with a mask or an instruction, and the model denoises a new version of those pixels under that constraint.
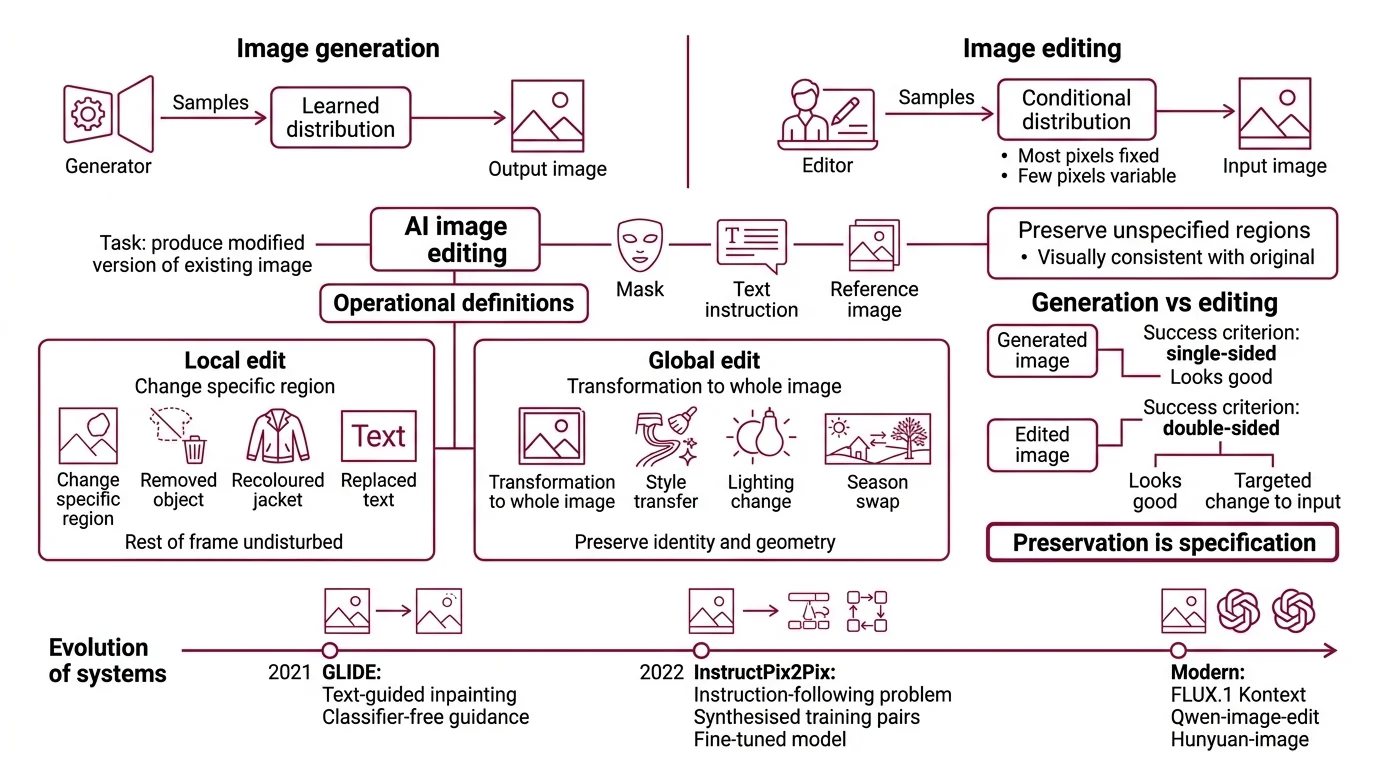
Generating an image from noise is one problem. Editing an image you already have is a different one. The second requires the model to preserve everything you did not specify — a constraint the probabilistic machinery of diffusion does not naturally respect. That preservation gap is the whole story of modern image editing, and every technique you hear about — inpainting, outpainting, instruction-based edits — is an answer to it.
Generation and editing solve two different problems
A generator samples from a learned distribution. An editor samples from a conditional distribution where most of the pixels are fixed and a few are variable. That asymmetry is what every image-editing technique is trying to solve.
What is AI image editing?
AI image editing is the task of producing a modified version of an existing image that follows a user specification — a mask, a text instruction, a reference image, or some combination — while keeping the unspecified regions visually consistent with the original. The underlying model is almost always a Diffusion Models system, sometimes paired with a language encoder that interprets the instruction.
Two operational definitions matter:
- Local edit: change a specific region (a removed object, a recoloured jacket, replaced text on a sign) without disturbing the rest of the frame.
- Global edit: apply a transformation to the whole image (style transfer, lighting change, season swap) while preserving subject identity and geometry.
Both are harder than “generate an image from a text prompt” because the success criterion is double-sided. A generated image only has to look good. An edited image has to look good and look like a targeted change to the input. Preservation is not a bonus. It is the specification.
Early systems treated editing as a bolt-on to generation. The seminal paper was GLIDE (OpenAI, 2021), which introduced text-guided inpainting via classifier-free guidance during the reverse diffusion pass (OpenAI GLIDE paper). The next shift was InstructPix2Pix in 2022, which reframed editing as an instruction-following problem — Brooks, Holynski, and Efros synthesised around 450,000 instruction-edit training pairs by combining GPT-3 with Stable Diffusion, then fine-tuned a single forward-pass model on them (arXiv 2211.09800). Modern systems — FLUX.1 Kontext, Qwen Image Edit, Hunyuan Image, Seedream, Adobe Firefly — are direct descendants of those two lines.
How does AI image editing work with diffusion models and inpainting?
Every diffusion-based edit is a controlled reverse process. The starting point is not pure noise — it is a noisy version of your input image, either everywhere (for a global edit) or only inside a masked region (for a local edit). The reverse process denoises from that partially corrupted state, guided by whatever conditioning you provide, and returns a clean output.
The classical inpainting recipe, popularised by RePaint (Lugmayr et al., CVPR 2022), is surgical about preservation. It starts from a pretrained unconditional diffusion model and, at every reverse step, resamples the unmasked region from the forward process of the original image while letting the network denoise only the masked region (arXiv 2201.09865). The unmasked pixels are dragged back toward the truth at every step; the masked ones are free to drift toward whatever the conditioning wants. Run this schedule to completion and the boundary between old and new pixels becomes statistically consistent.
Think of a river you are trying to redirect through a single patch of its bank. The water upstream and downstream of the patch must flow as before; only inside the patch are you allowed to carve a new channel. RePaint is the engineering that keeps the upstream and downstream flow pinned while you cut.
Instruction-based editors work differently. FLUX.1 Kontext, described in the FLUX.1 Kontext paper (arXiv 2506.15742), performs flow matching in latent space over both text and image prompts simultaneously. The input image is encoded into latent tokens that condition the entire reverse trajectory — there is no explicit mask, because the model has learned, from training data, which regions a given instruction should and should not touch. “Remove the car” does not require you to outline the car; the model resolves the extent of the edit itself.
That elegance comes with a cost: interpretation. When the model decides the scope of an edit, it can also decide wrong.
The three edit paradigms share one reverse process
The paradigms differ in what they condition on and what they preserve, not in the underlying sampler. Once you see the shared skeleton, the design choices become readable.
What are the main components of an AI image editing system?
A production image editor is a pipeline of four components, each of which has changed substantially in the last two years.
| Component | Role | What current systems do |
|---|---|---|
| Text encoder | Converts the instruction into conditioning tokens | CLIP, T5, or native LLM backbones — the encoder directly shapes how literally the instruction is followed |
| Image encoder | Projects the input image into the model’s latent space | VAE encoders in classical diffusion; unified tokenisers in newer in-context systems like FLUX.1 Kontext |
| Denoiser | Runs the reverse process under conditioning | U-Net in older systems; Diffusion Transformer in most 2026 releases |
| Control mechanism | Enforces the edit constraint | Explicit masks (inpainting), latent conditioning (instruction-based), or spatial controls (depth, pose, segmentation maps) |
The interesting variation is in the control mechanism. Three families dominate.
Mask-based inpainting is the oldest and most controllable. You supply a binary mask; the model treats the masked region as variable and the rest as fixed. RePaint is the academic reference; in production, the same mechanism survives inside OpenAI’s Images API Edits endpoint for GPT-Image-1 (OpenAI API Docs) and inside Adobe Firefly’s AI Markup feature, which lets a user draw the mask by hand and attach a text prompt to it (Adobe Blog). GPT-Image-1.5, rolled out in April 2026, improved edit fidelity and logo-and-face preservation at roughly twenty percent lower image I/O cost than its predecessor (OpenAI Blog). The tradeoff is operator labour: someone has to define the mask.
Outpainting is inpainting’s cousin. The canvas is extended with empty pixels, the empty region is treated as the mask, and the same reverse process fills it. The challenge is not the sampler — it is continuity at the seam, where the model must produce pixels consistent with the real image’s lighting, perspective, and texture gradient. Large-mask specialists like LaMa (LaMa paper) historically handled this by operating in the frequency domain with Fast Fourier Convolutions, but most current systems rely on their diffusion backbone’s attention over the original image to maintain coherence.
Instruction-based editing collapses the mask into the prompt. Qwen-Image-Edit, released by Alibaba’s Tongyi Lab as a 20B-parameter open-source model, organises edits into three operational classes: semantic (style transfer), appearance (add, remove, recolour), and text editing in Chinese and English (Qwen-Image Blog). HunyuanImage-3.0-Instruct, launched January 26, 2026, pushes the parameter count to 80B total with roughly 13B activated, using a mixture-of-experts architecture to support one-line edit instructions, multi-image fusion, and region reasoning — though the “reasoning” framing is a marketing label, not symbolic reasoning (Tencent GitHub). Seedream 4.5, ByteDance’s unified generation-and-editing model released in December 2025, outputs up to 2048×2048 natively and is tuned for multi-image reference fidelity and in-image typography (ByteDance Seed). The common thread: the instruction implicitly specifies the mask.
A unified pattern has also emerged — a single model for both generation and editing. Qwen-Image-2.0, released in February 2026 at 7B parameters, is a compact example (Qwen-Image Blog). These systems blur the old pipeline boundary where generation and editing were separate endpoints; the reverse process treats them as two instances of the same conditional sampling problem.
What the mechanism predicts
Once you see editing as conditional reverse diffusion, several behaviours follow logically rather than magically.
- If you supply a tight mask and a strong guidance scale, you should observe sharp, over-constrained edits that sometimes produce a visible boundary artifact — the inside of the mask is pulled hard toward the conditioning while the outside is pinned to the original.
- If you feed an instruction-based model an ambiguous prompt (“make it better”), you should observe global drift — changes in colour, subject pose, or composition in regions you did not intend to touch — because the model has no mask to restrain it.
- If you outpaint a photograph beyond its original context, you should observe plausible but invented geometry, because the model is sampling the most likely continuation of the visible edges, not recovering a ground truth.
- If you chain edits sequentially, you should observe drift accumulation — every pass is a lossy reconstruction of the previous pass, and small inconsistencies compound.
Rule of thumb: preservation is not a property of the model, it is a property of the control mechanism. The tighter you specify what must not change, the more reliably the edit stays local.
When it breaks: the hardest failure mode is semantic drift inside an instruction-based edit. When the prompt under-specifies the edit region, the model invents a scope — and “remove the person in the foreground” can quietly re-render the background, change the lighting, or nudge the subject’s identity. Mask-based pipelines avoid this but demand operator labour. Unified instruction-based models avoid the labour but reintroduce the drift. No current architecture gives you both surgical locality and hands-off convenience at the quality ceiling of 2026 models.
Source-caveat notes:
- FLUX.1 Kontext speed claim: Black Forest Labs’ “up to 8× faster than GPT-Image” figure is a vendor-reported benchmark from BFL’s own playground announcement, not an independent head-to-head test.
- Hunyuan “reasoning” framing: HunyuanImage-3.0-Instruct’s marketing describes the model as “reasoning” before editing. The underlying mechanism is a diffusion MoE pipeline, not symbolic reasoning — treat the framing as a product label.
- GPT-Image endpoint status: GPT-Image-1 remains available via the OpenAI Images API, but GPT-Image-1.5 is the default for new rollouts as of April 2026. InstructPix2Pix (2022) is still pedagogically central but is no longer state-of-the-art in production.
The Data Says
Image editing is not a specialised sub-problem of image generation. It is the harder problem — a conditional sample where most pixels are fixed — and the 2026 frontier, from FLUX.1 Kontext to Qwen-Image-2.0 to Hunyuan 3.0 to Seedream 4.5, is converging on a single architecture: a unified diffusion or flow-matching backbone that treats generation and editing as two points on the same conditional surface. The mask, once a hard-coded input, is increasingly something the model infers from language.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors