What Is AI Hallucination and How Statistical Next-Token Prediction Creates Confident Falsehoods

Table of Contents
ELI5
An AI hallucination is when a language model generates text that reads as confident and correct — but is factually wrong, because the model predicts likely words, not true ones.
Ask a large language model to name the longest river in Spain and it will answer without hesitation. It might even be right. But ask it for the third-longest, or for the river that briefly changed course after a 1962 flood in Catalonia, and something shifts. The answer arrives with the same composure — same syntax, same authority — except now the facts are fabricated. The model did not look anything up. It predicted what a correct answer would sound like, and the prediction was wrong.
That gap between fluency and accuracy is not a bug in the software. It is a direct consequence of how the software was built.
The Confidence Engine With No Truth Detector
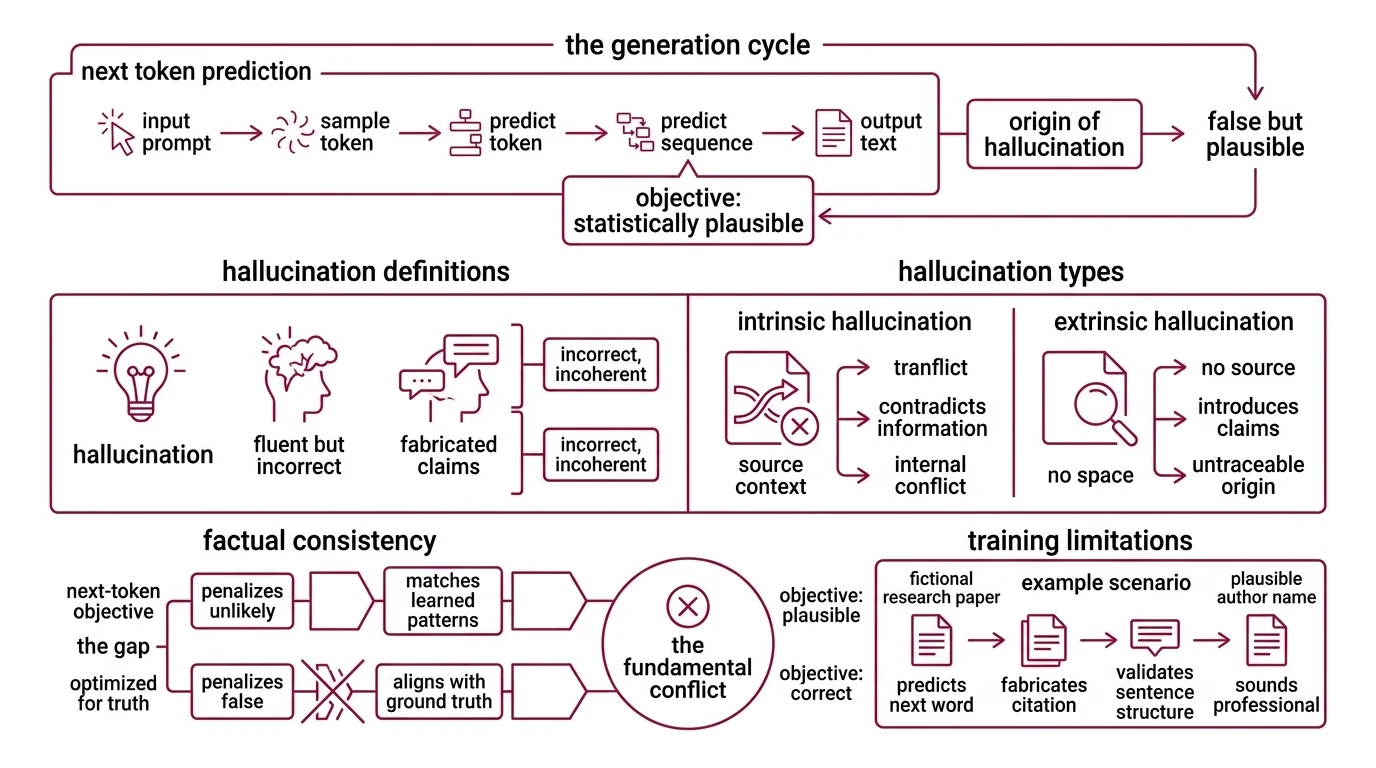
A language model generates text one token at a time. Each token is sampled from a probability distribution conditioned on everything that came before — the prompt, the tokens generated so far, and the patterns encoded during training across billions of parameters. The training objective is clean and narrow: predict the next token. Not the correct token. The statistically plausible one.
That single distinction is where hallucination originates.
What is hallucination in large language models
A hallucination is an LLM output that appears fluent and coherent but is factually incorrect, logically inconsistent, or entirely fabricated (Huang et al., ACM TOIS). The term borrows from psychiatry, but the analogy is imprecise — a human hallucination involves perception without stimulus; an LLM hallucination involves generation without grounding.
The taxonomy is worth knowing if you intend to do anything about the problem. Intrinsic hallucinations contradict information already present in the source context — the model asserts one thing in paragraph two and the opposite in paragraph five, within the same output. Extrinsic hallucinations introduce claims that cannot be traced to any source: not in the training data, not in the prompt, not verifiable anywhere. Both types look identical to the reader.
Factual Consistency — the property of aligning generated text with verifiable ground truth — is precisely what the next-token prediction objective fails to optimize. The training loss penalizes unlikely continuations. It does not penalize false ones, so long as they are statistically plausible within the learned distribution. A sentence about a fictional research paper, complete with a plausible author name and a year that fits the topic, scores well under this objective. The loss function cannot tell it apart from a real citation.
How do LLMs generate false information that sounds correct
Consider a model completing the prompt: “The capital of Australia is ___.” The training corpus contains enough mentions of Canberra that the correct token receives dominant probability mass. The model gets this right reliably, for the same reason a parrot trained on Australian geography trivia would — sheer repetition.
Now consider a harder case: “The lead architect of the Sydney Opera House resigned in ___.” The model has encountered fragments — Jorn Utzon, controversy, a year in the 1960s — scattered across thousands of documents. The probability distribution for the next token is shaped by co-occurrence patterns across those fragments, not by a factual lookup. If the fragments are sparse or contradictory, the distribution flattens. The model still samples a token. And the token it samples will be whichever has the highest conditional probability — even if that probability is only marginally above alternatives, and even if the token is wrong.
The model has no way to separate confidence from accuracy. The softmax output is a distribution over vocabulary tokens; it is not a score of factual reliability. A model can assign overwhelming probability to an invented date because that date pattern-matches well against the surrounding context — the right format, the right decade, syntactically coherent with the sentence structure.
This is the core of the Calibration problem. A well-calibrated system would express high certainty only when it is right at a correspondingly high rate. Current LLMs are poorly calibrated in factual domains — they produce “definitely 1966” and “definitely 1968” with comparable conviction, regardless of which is true.
When Deeper Reasoning Digs a Deeper Hole
There is a counterintuitive finding in recent evaluations that complicates the standard mitigation story. The assumption is straightforward: if models reason step by step, they should make fewer factual errors. On logic and math benchmarks, this holds. On factual recall, the picture inverts.
Why do language models make up facts instead of saying I don’t know
The training objective provides a structural answer. During pre-training, every position in the sequence requires a prediction. There is no “I don’t know” token that scores well against the cross-entropy loss. The model learns that generating a plausible continuation — any plausible continuation — is the strategy that minimizes loss. Silence is never rewarded.
Reinforcement learning from human feedback compounds the incentive. Human raters tend to prefer confident, detailed answers over hedged ones. A response that says “I’m not sure, but it may have been 1966” scores lower with evaluators than one that states “It was 1966” — even when both reflect the same underlying uncertainty. The reward signal systematically pushes toward fluent bluffing.
Chain-of-Thought reasoning makes this dynamic worse in a way that is easy to miss. Reasoning models produce intermediate steps before arriving at an answer. On structured problems — arithmetic, formal logic — these intermediate steps constrain the output toward correctness. But on factual questions where the model lacks grounding, each intermediate step becomes another sampling opportunity from an uncertain distribution. OpenAI’s o3 hallucinated on 33% of PersonQA questions, compared to 16% for o1 (Lakera). Each reasoning step is another chance to fabricate, and the guesses compound.
A 2025 empirical study found that chain-of-thought prompting reduces hallucination frequency on reasoning tasks but obscures the detection cues that help downstream systems catch remaining errors — incorrect tokens are produced with higher confidence when wrapped in reasoning scaffolding (ACL 2025 Findings).
Not a failure of reasoning. A consequence of reasoning without ground truth.
What the Failure Modes Predict
The mechanism produces testable predictions. If hallucination is an artifact of the prediction objective and the shape of the training distribution, then specific conditions should raise or lower the rate — and they do.
If you query a model about topics densely represented in training — common entities, frequently cited facts, well-documented events — expect low hallucination rates. Gemini 2.0 Flash achieves a 0.7% hallucination rate on the Vectara HHEM benchmark (Suprmind). But that benchmark measures summarization faithfulness within a narrow task; rates vary wildly across benchmarks like Vectara, AA-Omniscience, and FACTS, each of which captures different failure modes. As of 2026, no single benchmark measures the full spectrum of hallucination behavior.
If you query about rare entities, recent events beyond the Knowledge Cutoff, or domains where training data is thin — expect the rate to climb sharply. GPT-4o’s hallucination rate dropped from 53% to 23% with prompt-based mitigation in a 2025 medical study (Lakera). That tells you two things simultaneously: mitigation works, and a 23% hallucination rate in clinical contexts is still dangerous.
If you ground the model with retrieved documents, expect measurable improvement — a Neptune AI analysis found reductions of 42–68% in tested settings, though this figure reflects specific experimental conditions, not a universal constant (Neptune AI). The field has also moved past naive 2023-style chunk-embed-retrieve pipelines; current approaches combine graph-based retrieval, agentic verification loops, and hybrid search to address failure modes that standard retrieval-augmented generation could not handle.
Rule of thumb: The further a query falls from the dense center of the training distribution, the higher the probability of hallucination — and no prompt strategy changes the underlying distribution.
When it breaks: Every current mitigation — retrieval grounding, calibration-aware reward models, best-of-N reranking, activation probing — reduces hallucination rates without eliminating them. The training objective itself generates the failure mode. Until models optimize for objectives that explicitly represent epistemic uncertainty rather than token-level prediction, hallucination remains a rate to manage, not a defect to patch.
The Data Says
Hallucination is not a defect in the implementation. It is a mathematical consequence of optimizing for next-token prediction without a truth-grounding mechanism. The model cannot distinguish what is likely from what is true — and its training explicitly rewards the likely. Every mitigation strategy, from retrieval augmentation to reasoning chains to activation probes, operates within this constraint: reducing the rate, but never escaping the architecture that produces it.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors