What Is AI for Technical Debt and How Machine Learning Detects Code Smells and Hotspots

ELI5
AI for technical debt uses machine learning and behavioral analytics to find where code is decaying, predict which weak spots will actually cause bugs, and estimate the cost of fixing them — turning “messy code” into a measurable map.
Run a static analyzer across a mature codebase and it will hand you thousands of warnings. Most teams glance at the number, sigh, and fix almost none of them. Yet the production incidents keep arriving from the same handful of files — the ones everyone is quietly afraid to touch. The warnings are spread everywhere. The pain is concentrated somewhere specific. That gap between where debt looks like it lives and where it actually hurts is the anomaly worth explaining.
The Difference Between a Mess and a Map
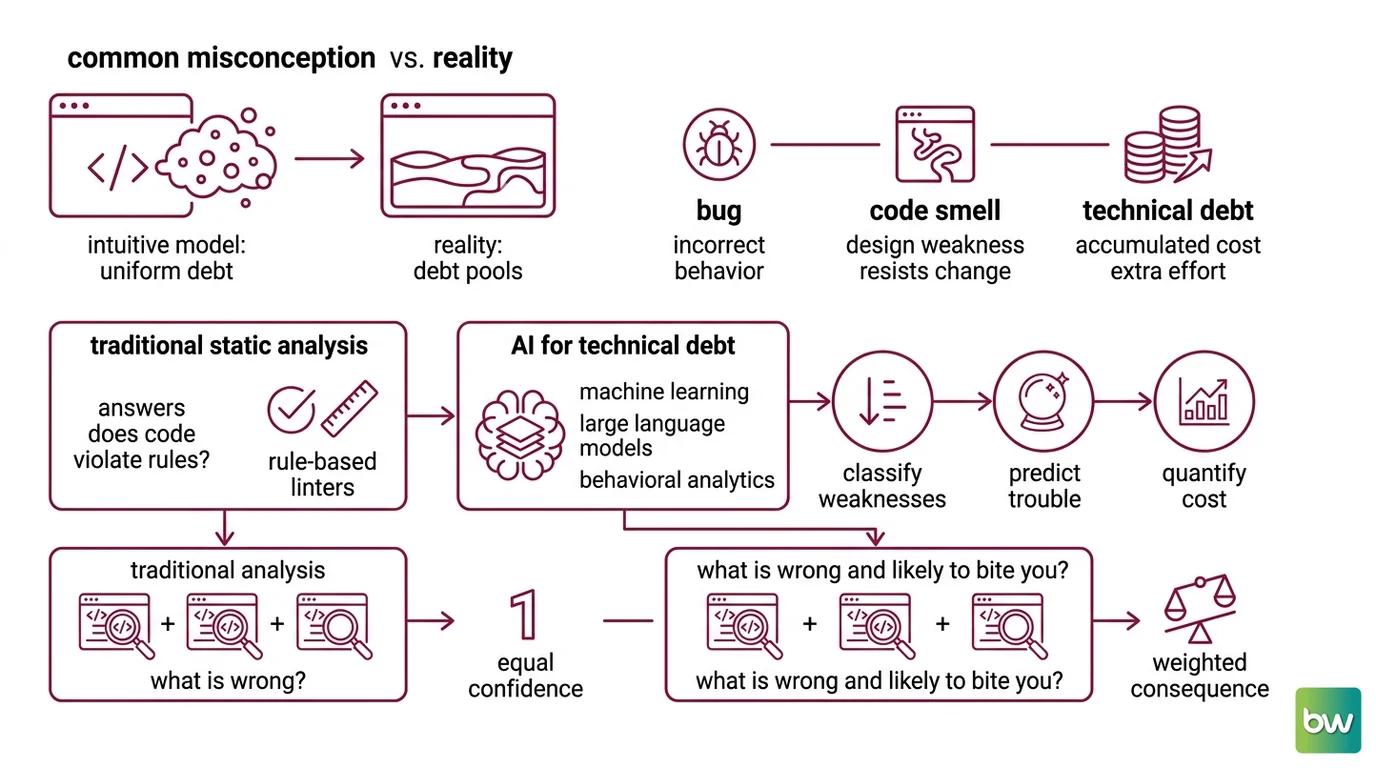
The intuitive model says technical debt is everywhere — a thin film of grime coating the whole repository, accumulating uniformly with every rushed commit. That model is wrong, and the way it is wrong determines everything that follows. Debt does not settle like dust. It pools.
Before the mechanism makes sense, three ideas that developers routinely collapse into one need separating. A bug is behavior that is already incorrect. A Code Smell is a design weakness — code that runs correctly today but resists change tomorrow. Technical debt is the accumulated cost of those weaknesses: the extra effort every future modification will pay. The term “code smell” was coined by Kent Beck and popularized by Martin Fowler’s Refactoring in 1999 (Martin Fowler). A smell is not a defect. It is a prediction about where defects will be cheaper to create than to avoid.
What is AI for technical debt?
AI for technical debt is not a single product. It is a category of tools and techniques that layer machine learning, large language models, and behavioral analytics on top of traditional Static Code Analysis to do three things that rule-based linters cannot do alone: classify weaknesses that resist hand-written rules, predict which of those weaknesses will actually cause trouble, and quantify the cost in a unit a manager can reason about.
Classical static analysis answers “does this code violate a known rule?” It is precise but literal. It will flag a deeply nested function and a trivially nested one with equal confidence, because it counts structure without weighing consequence. The AI layer changes the question from “what is wrong?” to “what is wrong and likely to bite you?” — and that shift is the entire reason the category exists.
Not noise. Signal.
From Counting Lines to Reading Behavior
Traditional analysis measures the code as it sits on disk. Behavioral analysis measures how the code lives — how often it changes, who changes it, and how tangled it has become while doing so. The first is a photograph; the second is a time-lapse. The mechanism of modern technical-debt detection is the fusion of the two.
How does AI identify and quantify technical debt across a codebase?
It happens in layers, each answering a narrower question than the last.
The first layer is structural measurement.
Cyclomatic Complexity — introduced by Thomas McCabe in 1976 as M = E − N + 2P, counting the independent paths through a function — remains the workhorse metric. NIST recommends a ceiling of 10 per function, a boundary widely treated as the line between acceptable and risky (Wikipedia). Duplication, file length, and coupling join it as raw structural signals.
The second layer converts structure into cost. This is where SonarQube made the abstract concrete: it expresses technical debt as the estimated effort to fix all maintainability issues, stored in minutes (Sonar Documentation). It then derives a technical-debt ratio — debt divided by the cost to develop the same code, using a default of 30 minutes per line — and maps that ratio onto a Maintainability rating from A (a ratio of 0 to 0.05) down to E (Sonar Documentation). Debt stops being a feeling and becomes a number with a grade attached.
The third layer is where the “AI” earns its name. Behavioral code analysis, the method that defines Codescene, combines each file’s Git change-frequency with its Code Health score rather than relying on static rules alone (CodeScene). Multiply “how messy” by “how often touched” and you get a Hotspot Analysis: the small region of code that is both complicated and constantly in motion. The payoff is the anomaly from the opening — CodeScene’s research finds that top hotspots, a minor fraction of the codebase, account for between 25% and 70% of reported and resolved defects (CodeScene). Debt pools, and the hotspot map shows you the puddles.
A fourth layer increasingly sits underneath the classifiers. A survey of 42 papers published between 2005 and 2024 traces code-smell detection from classical machine learning — support vector machines, Bayesian methods, rule-based systems — toward deep learning approaches such as Bi-LSTM and GRU networks (MDPI). These models learn the texture of a smell from labeled examples instead of waiting for a human to encode a rule for it. Their reported accuracy, however, swings widely depending on the dataset, and the datasets themselves are the field’s acknowledged weak point — so a single headline accuracy figure tells you very little.
Inside the Machine
Strip the marketing from any of these platforms and the same organs appear underneath, arranged in a pipeline from raw source to actionable verdict. Knowing the parts makes it obvious which capability you are actually buying — and which you are only being promised.
What are the components of an AI code quality and technical debt analysis tool?
| Component | What it does |
|---|---|
| Parser + AST builder | Turns source into an abstract syntax tree the rest of the pipeline can reason about |
| Static rule engine | Flags known smell patterns, style violations, and duplication |
| Metric calculators | Compute complexity, coupling, coverage, and the debt-in-minutes estimate |
| ML smell classifiers | Learn weaknesses that resist hand-written rules; increasingly built on Code LLMs |
| Behavioral analytics | Fuse version-control history with code health to surface hotspots |
| Quantification + gating | Aggregate into ratings and enforce a Quality Gate |
| Remediation layer | Suggest or apply fixes, from Refactoring hints to automated patches |
| Pipeline integration | Wire results into AI in CI/CD Pipelines so debt is checked on every change |
The quality gate deserves its own emphasis, because it is where measurement becomes policy. A quality gate is a set of pass/fail conditions, evaluated against both new and overall code, that a change must satisfy before it is merged (Sonar Documentation). It is the mechanism that prevents the debt number from being a report nobody reads.
The remediation layer is where the category is moving fastest. SonarQube, whose current release line is the 2026.1 LTA, now ships an AI “Remediation Agent” that proposes fixes rather than only reporting problems (Sonar Documentation). Newer AI-native entrants push further: Codeant AI advertises automatic scanning of commits for quality, security, and dead code, with an “Auto-Fix” capability spanning more than 5,000 issue types — figures the vendor reports itself, not independently verified (CodeAnt AI Blog). The trajectory is unmistakable: detection is becoming a commodity, and the differentiation is shifting to what the system can fix without a human in the loop.
What the Hotspot Map Predicts
Once you accept that debt concentrates rather than spreads, the map becomes predictive instead of merely descriptive. The intersection of complexity and change frequency is where you can place bets.
- If a file scores high complexity but rarely changes, it is debt you can usually afford to leave alone — it is frozen, and frozen code rarely surprises you.
- If a file is both complex and changed constantly, expect it to be the source of your next defect; treat it as a hotspot regardless of how few rule-violations it triggers.
- If you fix smells uniformly across the whole codebase, expect the defect rate to barely move — you will have spent effort proportional to the warnings rather than proportional to the risk.
Rule of thumb: Prioritize debt where complexity and change frequency intersect, not where the raw warning count is highest.
When it breaks: Hotspot and ML models read file-level and syntactic patterns, so they are largely blind to architectural debt that lives in the relationships between modules — a set of individually clean files can still form a tangled, fragile whole. And because deep-learning classifiers learn from labeled datasets that are notoriously inconsistent, a model that scores well on one project can degrade sharply when pointed at another.
The Debt a Classifier Cannot Feel
There is a deeper reason these tools cluster around the same metrics: complexity and churn are the parts of debt that happen to be cheap to measure. The most expensive debt — a wrong abstraction chosen three years ago, a domain model that no longer matches the business — leaves few syntactic fingerprints. The model assigns high confidence to what it can see, and silence to what it cannot. That asymmetry is worth holding onto: a green dashboard measures the absence of detectable debt, which is not the same as the absence of debt.
The Data Says
The signal in technical debt is not its total volume but its distribution. A minority of files carries the majority of defect risk, and the value of AI here is precision targeting — separating the complexity that costs you from the complexity that merely looks alarming. The frontier is no longer detection, which is becoming standard, but reliable automated remediation.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors