What Is AI Documentation Generation? How LLMs Turn Code Into Docstrings and Architecture Docs
Table of Contents
ELI5
AI documentation generation uses Large Language Models to read source code and produce docstrings, API references, and architecture summaries — without humans writing the prose, but with humans (or other models) auditing the result.
There is a recurring failure mode in early attempts at this. A developer points a frontier model at a 200,000-line repository, asks for “complete documentation,” and gets back something that sounds confident, reads fluently, and quietly invents functions that never existed. The mechanism behind that failure is not stupidity. It is geometry.
The Discipline Hidden Inside “Just Generate the Docs”
AI documentation generation is not autocomplete with a wider scope. The naive prompt — “summarize this file” — produces local fluency and global incoherence. What separates a research-grade system from a chatbot pasting a file into a prompt is the order in which code gets read, what gets pulled into context, and who checks the output afterwards.
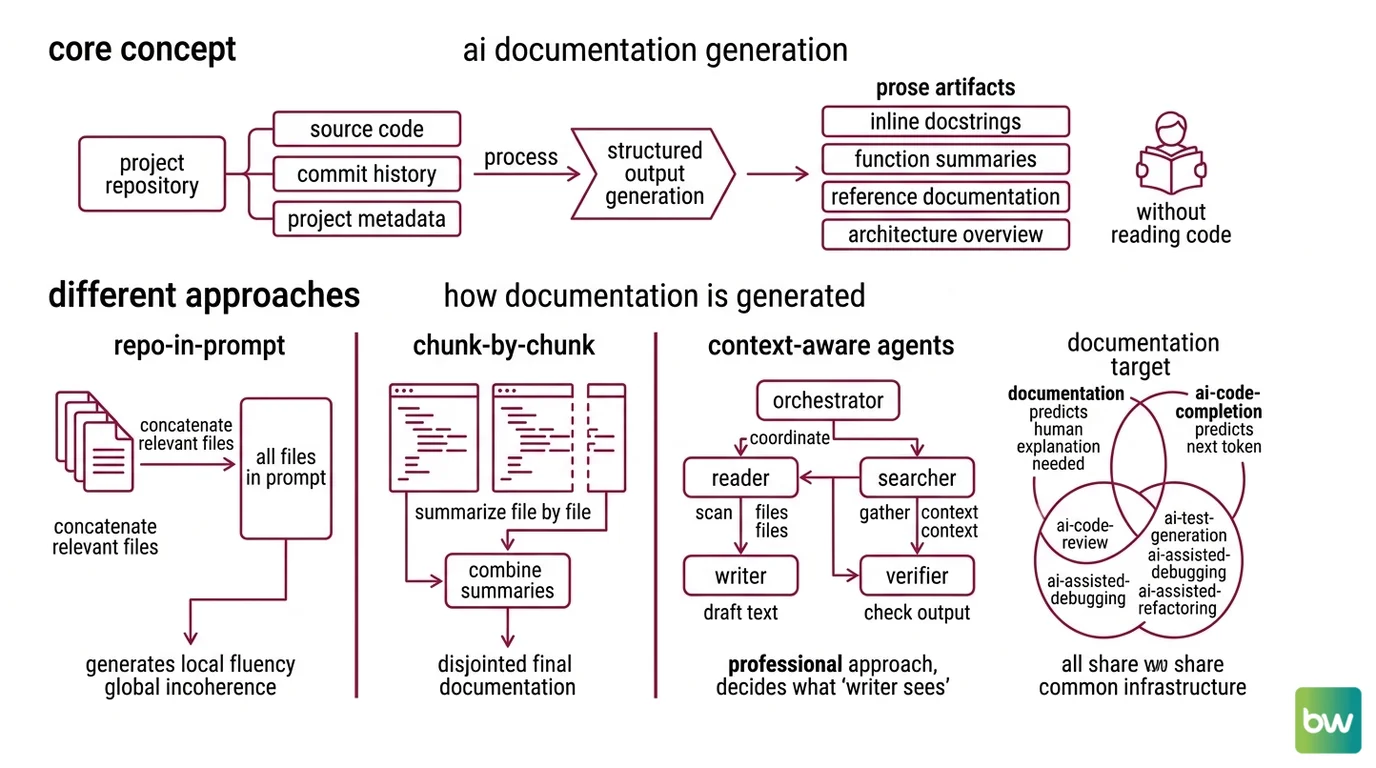
What is AI documentation generation?
AI documentation generation is the practice of using LLMs to produce structured prose artifacts — inline docstrings, function and class summaries, REST and SDK references, and architecture overviews — from source code, commit history, and project metadata. The model’s parameters stay frozen; the leverage comes from how code is chunked, sequenced, and verified.
The discipline overlaps with sibling practices like AI Code Completion, AI Code Review, AI Test Generation, AI-Assisted Debugging, and AI-Assisted Refactoring. They share infrastructure — the same model APIs, the same IDE plugins — but they differ in their output target. Completion predicts the next token. Documentation predicts the explanation a human, or another agent, will need to use the code without reading it.
The DocAgent system from Meta, accepted at ACL 2025, frames this distinction explicitly. Its multi-agent architecture splits the work across five roles — Reader, Searcher, Writer, Verifier, Orchestrator (arXiv DocAgent paper). The Writer is not the hero. The hero is whatever decides what context the Writer sees.
How does AI generate documentation from source code?
The honest answer is: it depends on whether the system was designed by someone who has worked with a real codebase, or by someone who believed the context window marketing.
There are roughly three architectures in use today.
Repo-in-prompt. The simplest. Concatenate the relevant files — or all of them, if you are brave and the repo is small — into the model’s context. Ask for documentation. This works for a 500-line script. It collapses on a real codebase, and not for the reasons most people suspect.
The advertised context length is not the effective one. In independent testing, models claiming 200K-token windows typically become unreliable around 130K, with attention cost growing quadratically in sequence length (Atlan). So even when the repo “fits,” the model’s ability to bind the name process_order in file A to the call in file B degrades long before the token counter complains.
Retrieval-augmented documentation. Tools like Mintlify, Cursor, and GitHub Copilot index the repository and retrieve only the relevant slices for each documentation target. The model writes one function’s docstring at a time, pulling in callers, callees, and tests. Smaller context per call. Higher fidelity. Quadratically cheaper.
Topologically-ordered multi-agent. This is DocAgent’s contribution. The system builds an AST-based Dependency DAG over the codebase and walks it in topological order — leaf symbols documented first, their consumers next, modules last (arXiv DocAgent paper). Each Writer call sees the code being documented plus the already-documented dependencies. The Verifier then checks the output against the source for three properties — Completeness, Helpfulness, Truthfulness — before it is allowed to land.
The reason this matters: documentation is not a per-file task. It is a graph problem. The order in which you document is more consequential than the model you pick.
What are the main types of AI-generated documentation: docstrings, API references, and architectural docs?
Three layers, each with its own failure modes.
| Layer | Granularity | Typical Input | Typical Failure |
|---|---|---|---|
| Docstrings | function / class | function body + immediate callers | hallucinated parameters that don’t exist |
| API references | endpoint / SDK method | route handlers + schemas + examples | stale signatures after refactors |
| Architecture docs | module / system | dependency graph + commit messages + tests | plausible-sounding diagrams of systems that don’t exist |
Docstrings are the most studied. DocuMint fine-tuned small language models — CodeLlama, CodeGemma, StarCoder — specifically for Python docstring generation, showing that a focused small model can match a generalist frontier model on this narrow task at a fraction of the inference cost (arXiv DocuMint paper). A parallel study evaluated LLaMA-3.1, Gemma-2, Phi-3, Mistral, and Qwen-2.5 for context-aware Javadoc generation across zero-shot, few-shot, and fine-tuned regimes (arXiv context-aware docs paper). The pattern that emerges across both: small models with good context beat large models with bad context.
API references shift the problem from prose to structure. Mintlify auto-generates llms.txt, llms-full.txt, and skill.md, and hosts an MCP server alongside the human-readable docs (Mintlify Docs). The same source becomes two artifacts — one optimized for human readers, one optimized for AI agents that need to call the API correctly.
Architecture docs are where most systems still fail. They require the model to abstract over the dependency graph without inventing relationships. Swimm’s Auto-sync approach addresses one part of this — docs are coupled to specific code snippets and updated in CI whenever the referenced code changes (Swimm Docs). The model is not asked “what is this system?” It is asked “what changed in this commit, and which docs need to reflect that?”
What the Graph Predicts
Once you accept that documentation is a graph problem, several practical consequences fall out.
- If your codebase has cyclic imports, expect documentation quality to drop sharply. The topological traversal degrades to an arbitrary order, and the Writer loses its scaffolding.
- If you regenerate the entire docs site from scratch on every CI run, you are paying quadratic attention costs without the corresponding quality gain. Incremental, change-coupled regeneration — Swimm’s model — is cheaper and more accurate.
- If you measure quality only by reader satisfaction, you will miss the failure mode that matters most for AI consumers: silently incorrect parameter types. The truthfulness dimension from DocAgent’s evaluation framework needs to be a separate gate (arXiv DocAgent paper).
Rule of thumb: treat the documentation pipeline like a build pipeline. Inputs are code and context; outputs are artifacts; verification is non-optional.
When it breaks: the dominant failure mode is hallucinated APIs — function signatures, parameter names, or return types that read like working code but do not exist in the source. This happens when the Writer is given prose context (commit messages, README fragments) without the binding code, and improvises. The mitigation is structural, not stylistic: never let a Writer emit a symbol it has not seen defined in the chunked source.
What Changes When the Reader Is Not Human
Internal data from Mintlify suggests nearly half of documentation traffic now comes from AI agents rather than humans (Mintlify Docs). The Model Context Protocol layer is becoming the connective tissue between docs sites and coding assistants like Claude Opus 4.7, GPT-5.5, and Gemini 3.1 Pro — the current frontier as of May 2026. The implication: documentation is no longer a human comprehension artifact with AI as a bonus consumer. It is increasingly a machine-readable contract with humans as the secondary audience.
That changes what “good documentation” means. A page that reads beautifully for a human but lacks an unambiguous parameter table is now actively harmful — the AI consumer will guess, and the guess will compile.
The Data Says
AI documentation generation works when it treats code as a directed graph, not a flat corpus. The systems that produce reliable output — DocAgent, Mintlify, Swimm — share a single architectural choice: they verify before they emit. The ones that fail share the opposite — they trust the context window. Pick the architecture before you pick the model.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors