What Is AI Code Review and How LLM-Powered PR Reviewers Catch Bugs Before Humans

Table of Contents
ELI5
AI code review is software that reads a pull request, builds a model of the whole repository, and writes inline comments — bugs, security issues, missing edge cases — the way a senior engineer would, except it never skims and never gets tired.
A senior reviewer opens a Friday-afternoon pull request, sees four hundred changed lines across nine files, and does what every overworked reviewer does: scrolls fast, approves on trust, ships it. The race condition in the new retry loop survives because nobody read it carefully. Three days later it surfaces in production as a phantom duplicate-payment bug. The cause was not a missing test — it was a tired human pretending to be a code reviewer.
This is the gap that LLM-powered PR reviewers were built to fill. And the most interesting thing about them is not that they are smarter than humans. They are not. They are just differently attentive.
What the Reviewer That Never Skims Actually Does
This is the inverse of AI Code Completion, where the model writes code one token at a time while the engineer steers. In review, the code is already written; the model’s job is to react to it. Modern AI code review tools do not look at a diff in isolation. They build a model of the repository — files, functions, call graphs, past pull-request comments — and then evaluate each change against that model. The diff is the question. The repository is the context. The output is a set of inline comments that a human would have written if a human had the patience.
Two facts make this approach work. First, LLMs are very good at reading a few hundred lines of code and noticing patterns that resemble known bug shapes. Second, the cost of being wrong on a code-review comment is low — the human merges anyway if the comment is noise. The asymmetry favors machines that comment generously and let humans filter.
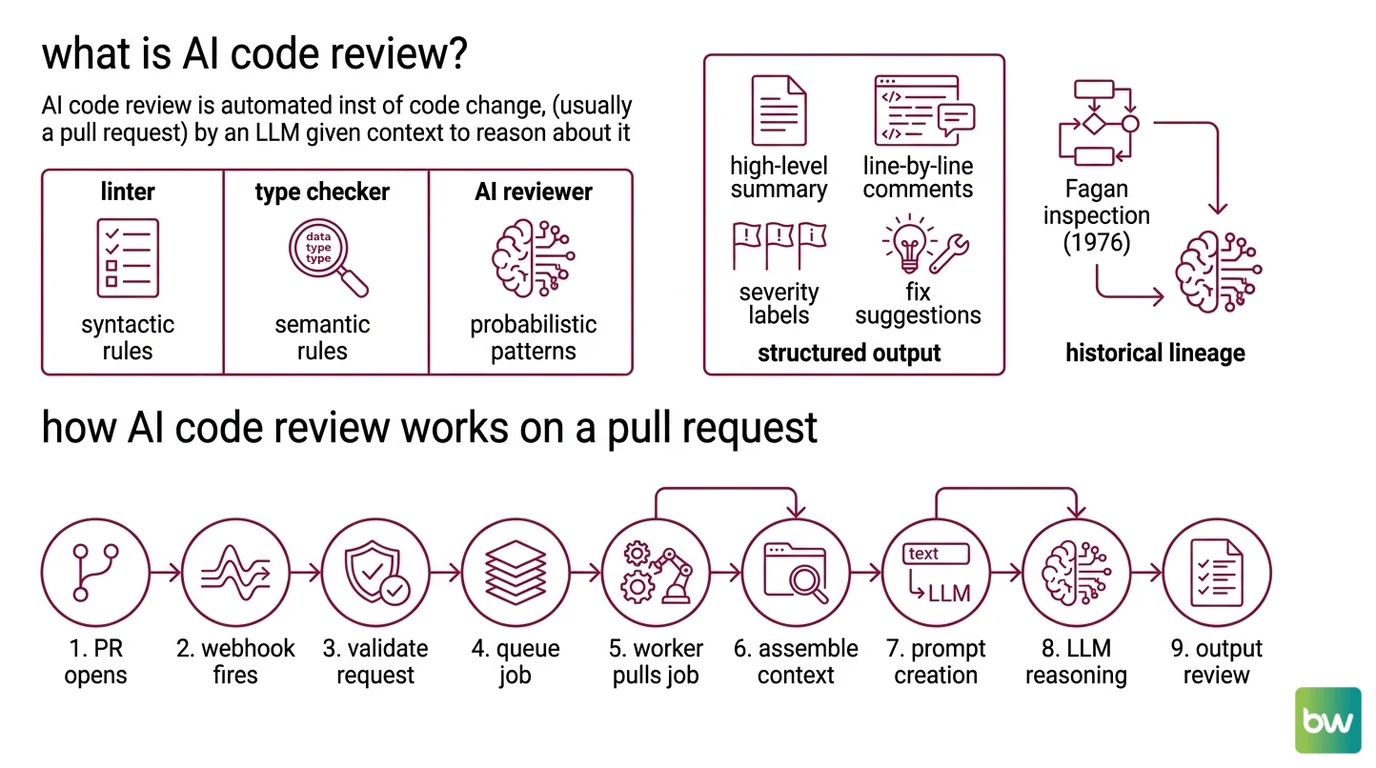
What is AI code review?
AI code review is the automated inspection of a code change — almost always a pull request — by a large language model that has been given the diff plus enough surrounding repository context to reason about it. The output is structured: a high-level summary, line-by-line comments, severity labels, and (in some products) one-click fix suggestions.
The lineage is older than the tooling suggests. Michael Fagan’s 1976 inspection process at IBM — planning, overview, preparation, inspection, rework, follow-up — is the canonical ancestor of every peer-review workflow we still use, and every AI reviewer inherits its framing (Wikipedia). What is new is not the idea of structured inspection. What is new is who performs it.
Not a smarter linter. A different kind of reader.
A linter applies syntactic rules. A type checker applies semantic rules within one file. An AI reviewer applies probabilistic pattern-matching across the whole repository — and it can articulate why a change looks suspicious in prose a junior engineer can act on. The first academic survey of the technique, the Rasheed et al. paper (arXiv:2404.18496), reported that LLM agents could detect code smells, identify bugs, and predict future risks; the authors observed a measurable drop in post-release defects when the reviewer ran in the loop.
That last detail matters more than the precision number. The bugs an AI reviewer catches are not exotic. They are the boring ones — null derefs that a human would catch on a good day and miss on a tired day. The value is not superintelligence. It is uniform attention.
How does AI code review work on a pull request?
The pipeline is more mechanical than the marketing suggests. When a PR opens, a webhook fires. A lightweight service receives the event, validates billing and permissions, and queues a job. A worker process pulls the job, clones the relevant slice of the repository, and assembles a prompt that contains the diff, the surrounding code, and — in the more sophisticated systems — a graph of which other files depend on the changed ones.
The worker then asks the LLM a series of structured questions: Are there bugs here? Security issues? Performance regressions? Violations of the team’s past conventions? Each answer becomes a candidate comment. A second filtering pass — sometimes a smaller, cheaper model — discards low-confidence noise and ranks what remains by severity. The surviving comments are posted to the pull request through the platform’s API.
CodeRabbit, one of the better-documented examples, runs this pipeline as a webhook into a Cloud Run service, which queues the work into Google Cloud Tasks, which dispatches to a sandboxed micro-VM worker with a 3600-second timeout and concurrency of 8 (Google Cloud Blog). The exotic part is not the model — the exotic part is the orchestration that makes the model behave like a service rather than a research demo.
Two design choices separate the products. One: how much context does the reviewer see? Greptile indexes the entire codebase as a graph and runs parallel agents across it, so a comment on a small diff can flag impact in a distant module the diff never touched. GitHub Copilot code review gathers full project context before commenting (GitHub Docs). BitsAI-CR, the production system ByteDance described in the BitsAI-CR paper (arXiv:2501.15134), uses a two-stage RuleChecker + ReviewFilter architecture and a continuous data flywheel — the system learns from which comments engineers accept and which they dismiss.
Two: what does the reviewer try to catch? Cursor’s BugBot is the most extreme example of focus — it intentionally ignores formatting and style and looks only for real bugs: logic errors, race conditions, null derefs, edge-case handling (Cursor Docs). The May 11, 2026 release added Default, High, and Custom effort levels so teams can dial how aggressively the reviewer searches (Start Debugging). CodeRabbit takes the opposite stance and combines the LLM pass with 40+ linters and security scanners — a vendor-published claim the exact list of which is not in the public docs, so treat that figure as marketing rather than spec.
The probabilistic nature of the reviewer matters. The same PR, reviewed twice, may yield slightly different comments — not because the code changed, but because token sampling at temperature greater than zero is stochastic. This is why every serious vendor invests in deterministic post-processing: severity buckets, dedup, conventions enforcement. The model proposes. The pipeline edits.
Inside the Box
What are the components of an AI code review system?
Strip away the marketing and an AI code review system is four mechanical parts plus one cultural part.
First, the retrieval layer decides what context the model sees. This is where review-as-a-product is won or lost, and the place where vendors differ most. The naive approach hands the model the raw diff and nothing else — fast, cheap, blind to anything outside the changed lines. The graph approach, used by Greptile and Copilot code review, parses the repository, builds a dependency graph, and pulls in related code on demand. Greptile’s coverage is full for Python, JavaScript, TypeScript, Go, Elixir, Java, C, C++, C#, Swift, PHP, and Rust, and partial for others (Greptile).
Second, the reasoning layer is the LLM call itself. This is the part that looks like magic and is in fact the most boring. The model receives a prompt of the form “here is a diff, here is some context, here is the team’s style guide, list every issue you see with severity.” The cost of a single review call has dropped low enough that products like Qodo’s PR-Agent run each command (/review, /improve, /ask) as a single LLM call lasting roughly thirty seconds (Qodo Docs).
Third, the filter layer turns the model’s raw output into something a team will tolerate in their PR feed. Without filtering, the model is a firehose — every borderline observation, every speculative concern. BitsAI-CR’s ReviewFilter, GitHub Copilot’s High/Medium/Low severity labels (the labeling scheme announced in the May 12, 2026 GitHub Changelog), and CodeRabbit’s grouping of similar comments are all responses to the same problem: a model that comments on everything is a model nobody reads.
Fourth, the action layer is what closes the loop. One-click apply, suggested patches, the ability to converse with the reviewer in PR comments. The cheaper this loop is, the more reviews convert into actual code fixes. Independent measurements that try to compare tools head-to-head — bearing in mind every benchmark publisher picks its own bug set, which DeepSource frames as the “every vendor benchmarks itself and wins” problem — give a rough sense of the shape of the field. The Macroscope benchmark on 118 production bugs reported Macroscope at 48%, CodeRabbit at 46%, Cursor BugBot at 42%, and Greptile at 24% with substantial false-positive noise (Macroscope, who publishes the benchmark — read the rankings as illustrative). Graphite reports a fix-conversion rate of 82% on its flagged issues per DEV Community summaries. Treat the numbers as evidence of variance, not a settled leaderboard.
Then comes the cultural part — the spec. The configuration file (.cursor/BUGBOT.md, custom rules, team conventions) is what makes the reviewer’s behavior match the team’s expectations. A reviewer with no spec drifts toward the conventions of its training distribution, which is to say: the conventions of GitHub’s public repositories, which are not your conventions.
What the Architecture Predicts
Once you see the four-plus-one structure, several behaviors stop being surprising and start being predictable.
- If your repository has poor retrieval — a giant monorepo with no clean dependency graph — the reviewer’s comments will be shallow on cross-file impact, even if the model itself is excellent.
- If your filter layer is tuned for recall, expect more noise. If it is tuned for precision, expect false negatives — bugs the model saw and discarded as low-confidence.
- If you change the team’s conventions without updating the spec file, the reviewer will keep enforcing the old rules and you will spend a week wondering why every PR has the same wrong comment.
- If you migrate to a new framework, the reviewer’s code-smell detection will degrade gracefully — it has seen the framework in training — but its repo-specific reasoning will lag until enough new PRs accumulate to retrain the data flywheel.
Rule of thumb: an AI reviewer is only as smart as its retrieval is wide and its spec is explicit.
Compatibility and billing notes:
- GitHub Copilot code review billing change (June 1, 2026): Copilot code review runs consume GitHub Actions minutes starting that date. Any pre-June 2026 guidance that calls Copilot review “free” is stale (GitHub Changelog).
- Qodo Merge → Qodo 2.0 (Feb 2026): Qodo Merge was rebranded and restructured into Qodo 2.0, a multi-agent platform with separate agents for bug detection, security, code quality, and test coverage. The name “Qodo Merge” still resolves, but the underlying architecture changed (Qodo Docs).
- Cursor BugBot effort levels (May 11, 2026): Default / High / Custom effort tiers shipped for paid plans. Older write-ups that describe BugBot as a single-tier product are now stale (Start Debugging).
When it breaks: AI code reviewers fail most predictably on changes that depend on context the retrieval layer never fetched — a tacit deployment convention, an unwritten security rule, a quirk of the production database that lives in someone’s head. The model is not wrong. The model is uninformed. No amount of cleverness at the reasoning layer compensates for missing context at the retrieval layer.
The Reviewer Reshapes Who Reviews What
The interesting consequence is not that humans are replaced. The interesting consequence is that human reviewers stop being the first reader. They become the second reader — the one who arbitrates after the machine has already commented, prioritized, and proposed fixes. The cognitive load shifts from “find every issue” to “decide which of the machine’s flags deserve action.”
That is a different skill. And it is the skill the next generation of senior engineers will need to develop deliberately, because the field has spent forty years training reviewers to be the first reader.
The 1976 Fagan inspection assumed the inspector was the one with the eyes. In 2026, the inspector is the one with the judgment.
The Data Says
AI code review is now a working production capability, not a research demo. The Rasheed et al. paper showed measurable bug-reduction effects in their study; BitsAI-CR documents a deployed system at ByteDance; CodeRabbit reports more than 2 million connected repositories as of early 2026 (DeepSource). The mechanism is mature enough that the bottleneck has moved — from “can the machine review code at all” to “can the team supply the retrieval context and spec the machine needs to be useful.” That bottleneck is not algorithmic. It is organizational.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors