What Is AI Code Completion and How LLM-Powered Inline Suggestions Predict the Next Token

Table of Contents
ELI5
AI code completion is an inline autocomplete that uses a language model to predict the next characters of code based on what surrounds your cursor — not a search engine that looks up snippets.
A developer types def fibonacci(n): and pauses for a fraction of a second. Gray text appears — a recursive base case, a memoization cache, an idiomatic one-liner. It feels like the editor read their mind. It did not. It ran a probability calculation, conditioned on the surrounding code, that returned the highest-likelihood continuation in roughly the time it takes to blink.
The folk explanation says the model “found similar code somewhere.” That mental model is wrong in a useful way — useful because it survives contact with simple examples but collapses the moment the cursor lands in the middle of a function, surrounded by code on both sides, and the suggestion still arrives. Nothing was retrieved. Something was sampled.
The Geometry Hidden Under the Gray Ghost Text
Inline completion looks like search and behaves like prediction. The distinction matters because every design decision in a modern code-completion system — model size, prompt format, latency budget, caching strategy — falls out of one engineering constraint: you cannot make the user wait.
What is AI code completion?
AI code completion is a runtime feature inside an editor that uses a language model to predict and display likely continuations of the code the developer is currently writing. The model receives a prompt assembled from the user’s open file (and often nearby files), produces a probability distribution over the next sequence of tokens, samples a continuation, and the editor renders it as inline ghost text the user can accept with a single keystroke.
What the model does not do is consult a database of snippets or perform a fuzzy match against a corpus. Code completion in the LLM era is a generation problem, not a retrieval problem.
The seminal demonstration arrived in 2021, when OpenAI published Codex — a GPT-class model fine-tuned on public code that hit 28.8% pass@1 on the HumanEval benchmark, against 0% for the base GPT-3 of the same era (the Codex paper). The number itself is a marketing snapshot, but the architectural lesson was durable: a general-purpose autoregressive transformer, given enough code during pre-training and fine-tuning, can write functions it has never seen by sampling tokens one at a time.
Modern inline-completion systems inherit that mechanism. They differ from Codex mostly in size, prompt format, and serving infrastructure — and those differences are where all the interesting engineering hides.
How does AI code completion work under the hood?
Under the hood, inline completion is a three-stage loop that runs on every meaningful pause in the editor: context assembly, model inference, and acceptance arbitration.
Stage one is context assembly. The editor walks the file the user is editing and builds a prompt: code before the cursor, code after the cursor, often a handful of imports and nearby files. This prompt is not a question. It is the input to a fill-in-the-middle generation task.
Stage two is inference. The prompt goes to a language model — typically a smaller, latency-optimized one — which produces a probability distribution over the next token, samples, conditions on what it just produced, and continues until it hits a natural boundary or a stop token. The sampler usually runs with low temperature for code, which biases output toward the highest-probability continuation rather than creative variation.
Stage three is arbitration. The editor decides whether to show the suggestion at all. Was the user still typing? Has the cursor moved? Is the suggestion identical to what is already there? Most rejected suggestions never reach the screen.
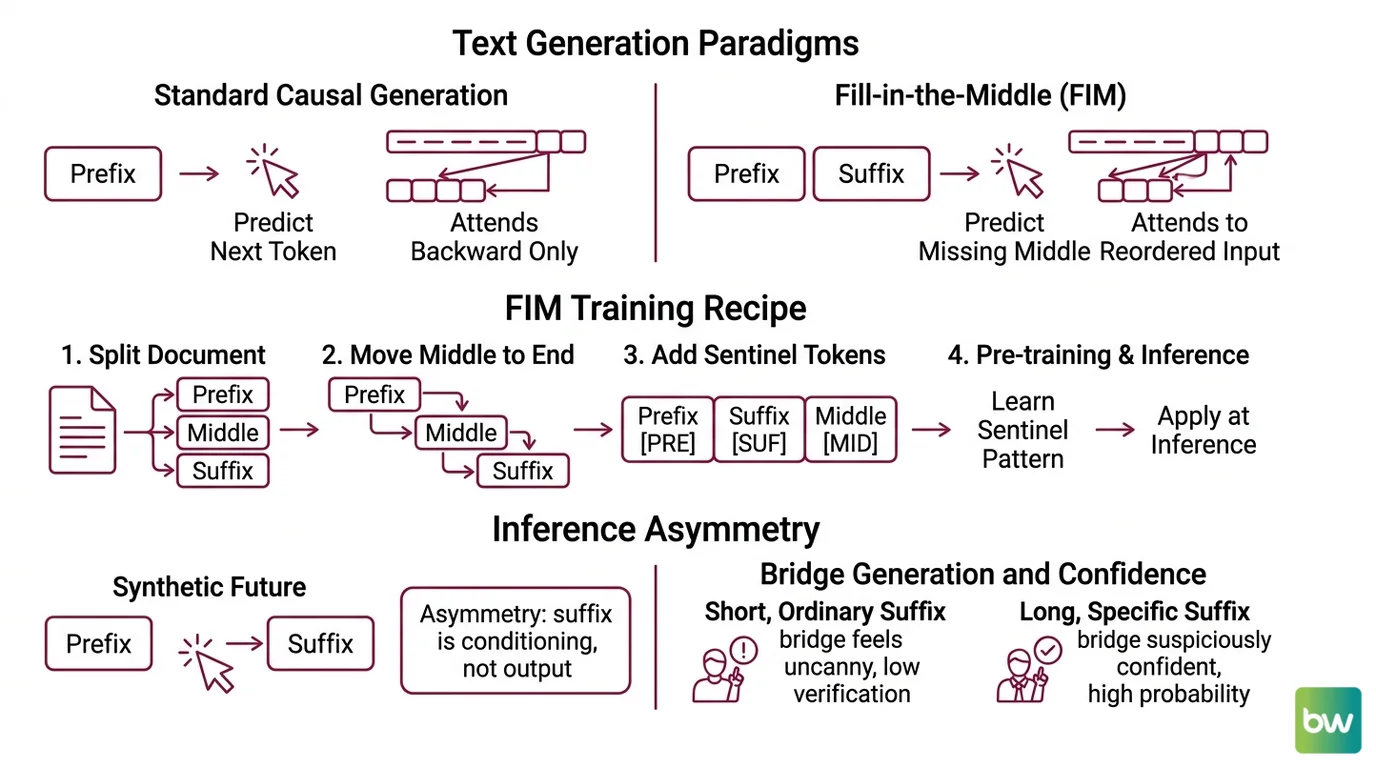
The non-obvious piece is the prompt format. Standard language models generate left-to-right: they see a prefix and predict what comes next. But a developer rarely writes code in pure append mode. They edit in the middle. They move the cursor up, change a parameter, jump back down. The model needs to see both what comes before the cursor and what comes after — and condition its prediction on both halves simultaneously.
That is the problem Fill-in-the-Middle solves.
The Fill-in-the-Middle paper, published by Bavarian and colleagues at OpenAI in mid-2022, showed something elegantly counterintuitive (the FIM paper). You can train a left-to-right language model to do infilling without changing its architecture. The trick: during pre-training, take a random document, cut out a span from the middle, and reorder the pieces. The new sequence looks like <prefix> <suffix> <middle> with sentinel tokens. The model still generates left-to-right. It just generates the middle last, conditioned on a future that has already been revealed.
The FIM paper’s central finding was that you get this infilling capability essentially for free — models trained with FIM data augmentation match the standard left-to-right capability on regular generation tasks. No quality regression. New capability unlocked.
GitHub Copilot’s inline completion uses Fill-in-the-Middle prompting on smaller fine-tuned models optimized for low latency (GitHub Docs). When you sit your cursor inside a function, the editor packages the code above as the prefix, the code below as the suffix, and asks the model to fill the gap. The model has never seen your file before. It has, however, seen millions of files with similar structure, and the geometry of code — its indentation, its symmetries, its naming conventions — collapses the space of plausible middles into a narrow band.
How Fill-in-the-Middle Rewrites the Generation Rules
The shift from pure left-to-right generation to FIM is small in code and large in consequence. A standard causal language model sees a sequence and predicts the next token, attending only backward. FIM reorders the inputs so the model can still attend only backward and yet condition on what is, semantically, ahead.
Imagine a writer asked to fill a missing paragraph in someone else’s essay. A left-to-right model is handed the first half of the essay and asked to keep writing — it never sees the conclusion, so it cannot land the paragraph in a way that connects to it. A FIM-trained model is handed the first half, then the conclusion, then asked to write the missing middle. Same generative process. Drastically different conditioning.
For code, this is the difference between guessing what a function might do and completing a function whose return statement is already written three lines below the cursor.
The FIM training recipe is deceptively plain: split documents into three parts at random offsets, move the middle to the end, mark the boundaries with special tokens. The model learns the sentinel pattern during pre-training and applies it at inference time when the editor formats prompts the same way.
There is a quiet asymmetry, though. The model still generates one token at a time, left to right. The suffix is part of the conditioning, not the output. At inference, the model is sampling token N given everything before token N — including a synthetic future that the prompt artificially placed earlier in the sequence.
This is why FIM completions sometimes feel uncanny when the suffix is short and ordinary, and feel suspiciously confident when the suffix is long and specific. The model assigns high probability to continuations that bridge the prefix to the suffix; it does not verify that the bridge is correct.
The Anatomy of a Latency Budget
A completion that arrives 600ms after the user pauses is, for most developers, a completion that does not exist. They have already typed past it. Every component of a production inline-completion system is designed around a single question: how do you keep total latency under the threshold where the suggestion still feels like prediction rather than interruption?
What are the main components of an AI code completion system?
A production inline-completion system has roughly six moving parts, and each one is a place where latency is either saved or spent.
The first is the trigger heuristic inside the editor. Not every keystroke fires a completion request — that would melt both the user’s CPU and the inference budget. Editors fire on natural boundaries: a newline, a closing paren, a brief pause. The heuristic is calibrated so requests track the rhythm of typing.
The second is the context window builder. This is the piece of editor logic that decides what to send. Just the current function? The whole file? Imports from other open files? Symbol definitions from across the project? More context generally helps quality and hurts latency. Every system makes a trade-off here, and the trade-off is constantly retuned. Cursor’s Tab feature, for example, is engineered for sub-100ms perceived latency, with the Fusion Tab model (Jan 2025) cutting server latency from 475ms to 260ms by changing how context is packed and how the model is served (Cursor Blog).
The third is the model itself. Inline-completion models are deliberately smaller than chat models. Codestral 25.08, Mistral’s current dedicated code-completion model, is specialized in low-latency FIM and code generation (Mistral AI Blog). Its predecessor, Codestral 25.01, ran 22 billion parameters with a 256K context window — roughly 2× faster than the original Codestral and benchmarked #1 on the LMSys Copilot Arena at launch (Mistral AI Blog). For comparison, the chat-and-edit side of these systems runs much larger models. Inline completion runs the model you can afford to wait for; chat runs the one you can afford to think with.
The fourth is the inference server. Speculative decoding, KV-cache reuse, batched serving, and quantization compress the time between “prompt arrived” and “first token returned.” Cursor reports serving 400M+ Tab requests per day and retraining on online reinforcement learning roughly every 1.5 to 2 hours (Cursor Blog), which means the model the user sees in the afternoon is not exactly the model they saw in the morning.
The fifth is the debouncer and acceptance loop. The editor must decide what to do when the user keeps typing while a request is in flight. Cancel? Show stale? Stream as the model generates? Most systems stream tokens into the ghost-text overlay and cancel aggressively when the user diverges from the predicted prefix.
The sixth is the acceptance signal pipeline. Every accept and reject becomes telemetry. That telemetry feeds the next round of fine-tuning or the next reinforcement-learning update. Completion systems are not static products. They are closed loops that improve with usage — assuming the telemetry is clean and the data flywheel is wired correctly.
A small detail with large consequences: GitHub Copilot’s completion model can be swapped from a menu, and the model that powers inline completion is not the same model that powers chat and edits (GitHub Docs). Two surfaces, two latency budgets, two cost profiles, one user.
The frontier here is also shifting. Windsurf’s Supercomplete — the inline completion in the editor formerly known as Codeium and now owned by Cognition — predicts the next action rather than the next token sequence (Windsurf Docs). The unit of prediction expands from “characters” to “edit operations,” which changes what the model needs to know and what counts as a successful completion. And in Copilot Arena’s Bradley-Terry head-to-head FIM evaluation, run by LMArena, general-purpose models like Claude and DeepSeek V2.5 compete with code-specific models when given the right prompt format (Copilot Arena). The line between “code model” and “general model with a good prompt” is thinner than it looks from the outside.
What the Probability Math Predicts in Practice
If completion is sampling from a conditional probability distribution rather than retrieval from a snippet store, several behaviors follow — and they are testable from your own editor.
If you write a function with a clear, conventional signature, expect a highly confident, mostly correct body. The prior over “what comes after def parse_json(text: str) -> dict:” is sharply peaked.
If you write a function with an idiosyncratic signature in a domain the model has seen rarely, expect either a hesitant completion or a fluent-but-wrong one. The probability distribution is flatter, so the sampler is forced to pick a continuation that looks plausible from a distance and falls apart on inspection.
If you change a variable name three lines up, expect the next completion in that scope to update accordingly. The prefix shifted, so the conditional distribution shifted with it. This is the same mechanism that lets a model “remember” a refactor without being told there was a refactor.
If you add detailed code below the cursor, expect FIM-trained completions to land more accurately at the point where the prefix meets the suffix. You gave the model more conditioning. The bridge it builds is narrower.
Rule of thumb: Inline completion is a probability machine, not a knowledge machine. The more constrained the surrounding context, the more reliable the suggestion — not because the model knows more, but because the distribution it samples from collapses to a sharper peak.
When it breaks: FIM completion fails most visibly when the prefix and suffix point at incompatible intents — for example, when a developer rewrites a function signature without updating the docstring below the cursor. The model dutifully tries to bridge them, the bridge is fluent and wrong, and the developer accepts a confident hallucination because gray ghost text never looks uncertain. The mechanism cannot tell you when it does not know; it can only sample from whatever distribution the prompt produced.
There is also a structural limit on benchmark-driven comparisons. HumanEval and SWE-bench scores quoted by vendors are point-in-time marketing snapshots, not standardized comparative benchmarks; treat exact percentages as illustrative. Sub-100ms latency numbers reported by completion vendors are similarly point-in-time and depend heavily on network round-trip time. They are not service-level guarantees.
Compatibility & naming notes:
- OpenAI Codex (original 2021 model): The standalone Codex API was deprecated in 2023. Do not describe today’s GitHub Copilot as “powered by Codex” in present tense — modern Copilot inline completions run on smaller, more recent fine-tuned models.
- Codeium → Windsurf: Codeium rebranded to Windsurf and is now owned by Cognition. The “Codeium” name still appears in some VS Code marketplace listings as a legacy alias.
- Codestral version: Codestral 25.08 supersedes Codestral 25.01 and the original Codestral. If citing Codestral, use 25.08 as the current version.
The Data Says
Inline code completion is a generation problem solved with a particular prompt format — Fill-in-the-Middle — running on small, latency-optimized language models inside a tightly engineered editor loop. The visible part is the gray ghost text. The invisible part is six layers of context assembly, sampling, debouncing, and telemetry, each tuned around a sub-second latency budget. Understanding that loop turns the experience from magic to mechanism, and makes the failure modes predictable rather than surprising.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors