What Is AI Background Removal? How Salient Object Segmentation Works
ELI5
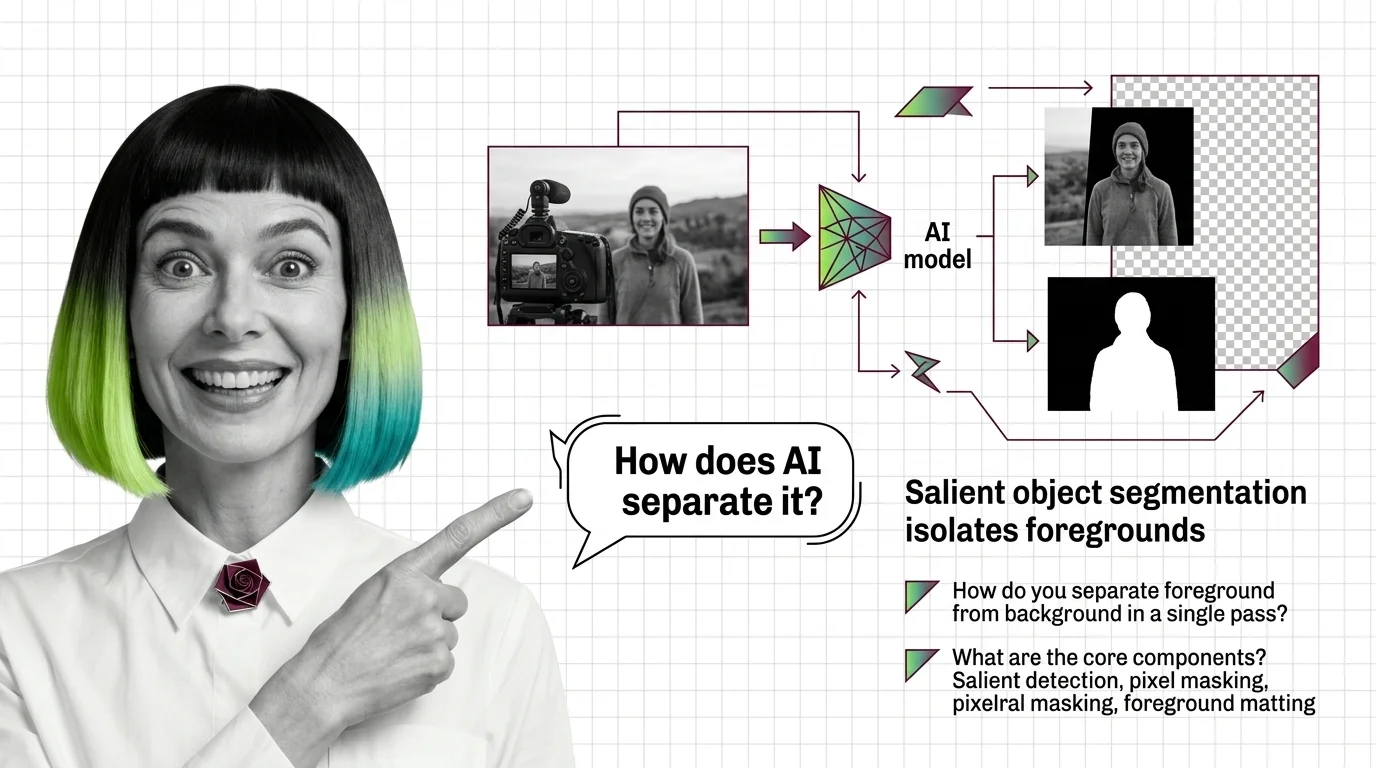
AI background removal is salient object segmentation: a model decides which pixels belong to the subject, then assigns each one an opacity value so soft edges like hair blend cleanly into a new background.
A photograph of a person with curly hair against a busy café window. A perfume bottle with a translucent green cap. A glass of beer. Hand any of these to a one-click background remover and watch what happens at the edges. Some pixels survive the cut; others vanish; a third category — the half-transparent ones — is where every model either earns its keep or quietly fails.
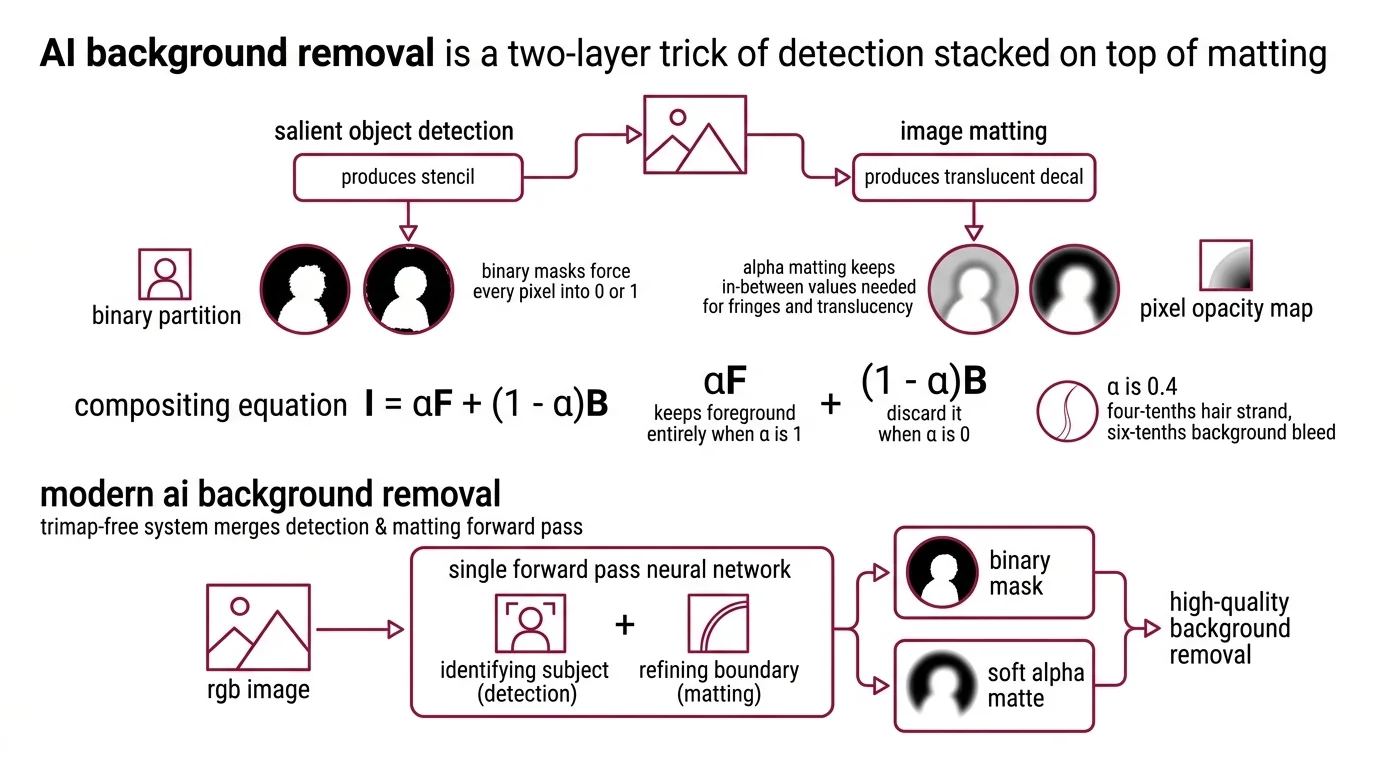
That third category is the entire story. Background removal is not one model. It is two ideas stacked on top of each other.
The Two-Layer Trick: Detection Stacked on Top of Matting
A useful background remover does not answer the question “what is the foreground.” It answers two questions in sequence. First: which region of the image carries the subject? Second: for every pixel, how much of the subject does it actually contain?
The first question is salient object detection — a binary partition between foreground and background. The second is Image Matting, where each pixel gets an opacity value α between 0 and 1. The two are not interchangeable. Detection produces a stencil. Matting produces a translucent decal. You need both for a hair edge or a wine glass to look like it belongs against a new sky.
The compositing equation underneath every modern remover is forty years old and dispiritingly simple: I = αF + (1 − α)B. The pixel you see is α units of foreground plus (1 − α) units of background, mixed (Deep Image Matting paper). When α is 1, you keep the foreground entirely. When α is 0, you discard it. When α is 0.4, you keep four-tenths of a hair strand and let six-tenths of the new background bleed through. Binary masks force every pixel into 0 or 1. Alpha Matting keeps the in-between values that fringes and translucency need.
What is AI background removal?
AI background removal is the use of neural network models to predict which pixels in an image belong to the salient subject and to what degree, producing either a binary mask, a soft alpha matte, or both. “AI” is doing two specific jobs: identifying the subject without being told where to look (detection) and refining the boundary into a smooth opacity map (matting).
Classical pipelines required a Trimap — an artist-drawn region map showing definite foreground, definite background, and the uncertain in-between strip — before the matting algorithm could refine the edges. Modern trimap-free systems merge detection and matting into a single forward pass. You drop in an RGB image and get back an alpha matte. No artist input. No region preprocessing.
That single-pass property is what people mean when they say “AI background removal.” It is the collapse of a two-stage pipeline into one neural function.
How does AI background removal separate foreground from background in a single pass?
The architecture that made single-pass removal practical is the U-Net descendant. U²-Net is the canonical example: a nested U-shape where each block is itself a smaller U, called a Residual U-block. The outer U passes the image through an encoder that compresses spatial resolution while expanding semantic richness, then a decoder that reverses the compression while keeping the semantic information. The inner Us inside each block do the same thing again at a smaller scale. The result is a network that sees both the global shape of the subject and its fine local boundaries inside the same forward pass.
BiRefNet pushed the design further by separating the two jobs into named modules. Per the BiRefNet paper, a Localization Module uses pretrained backbone features to find where the salient object lives globally. A Reconstruction Module then refines the mask using two bilateral references: hierarchical image patches (so the network sees the source pixels at multiple scales) and gradient maps (so it sees where intensity changes — usually edges). The output is a high-resolution mask aligned to actual edge geometry rather than to a coarse bounding region.
What makes the single pass possible is this dual-stream design: one path tells the network what the object is; the other tells it where the object’s boundary actually sits.
The Production Stack: Three Routes That Cover the Field
If you build a background-removal feature today, you almost certainly choose between three families of tooling. They differ less in raw segmentation quality than in licensing, deployment, and how much pixel-level fidelity you need.
What are the core components of an AI background removal system?
Any production system has the same four moving parts: a model checkpoint, a pre-processing pipeline, an inference runtime, and a post-processing step that turns logits into something a designer can drop into Photoshop.
The first family is open source. Rembg is a Python package that wraps fifteen swappable model checkpoints — including U2-Net, BiRefNet variants, BRIA RMBG, and SAM — behind a single CLI and HTTP server (rembg GitHub). You install it, point it at an image, and get an alpha matte back. The cost is that you operate the model yourself: GPU memory, version pinning, dependency hell. The reward is full control and a permissive MIT license.
The second family is commercial weights. BRIA RMBG (RMBG-2.0) is built on the BiRefNet architecture and trained on a manually pixel-labeled dataset. The model outputs a single-channel 8-bit grayscale alpha matte — 256 transparency levels, not just foreground or background, which is why composites against new scenes hold together at hair and translucent edges (RMBG-2.0 model card). The catch: weights are released under CC BY-NC 4.0. Self-hosted commercial use requires a separate agreement with BRIA or routing through their hosted API.
The third family is the hosted service. Remove Bg sells the same capability as a paid API, billing in credits per full-resolution image. You give up control of the model and gain a stable HTTP endpoint someone else operates. For a SaaS that needs background removal in week one, that trade is usually correct.
A fourth route, increasingly relevant, is prompt-driven segmentation. Meta’s Segment Anything line evolved from click-and-box prompts in SAM 2 to short noun-phrase text prompts in its successors — SAM 3, released November 19, 2025, introduced promptable concept segmentation that lets you say “the leftmost dog” and get a mask out (Meta AI Blog). This is not background removal exactly; it is a more general segmenter you can repurpose by prompting for the subject.
These models sit on different points of the latency-accuracy-license curve. They do not replace each other.
Licensing & version notes:
- BRIA RMBG-2.0: Weights are CC BY-NC 4.0. Self-hosted commercial use requires a separate BRIA agreement; the hosted Bria API is the licensed commercial path.
- rembg default model: Ships with
u2net(2020) for backward compatibility. For sharper masks, the project’s current docs recommendbirefnet-generalorbria-rmbgsessions.- SAM versions: SAM 2 (July 2024) remains supported; SAM 3 (November 2025) and SAM 3.1 (March 2026) add text-prompt concept segmentation for new builds.
What the Mask Predicts About Failure
Once you understand the architecture, you can predict where a model will struggle without testing it.
If the subject’s color matches the background, expect bleed at the edges. The salient-object branch relies on contrast cues; uniform brightness gives it nothing to lock onto.
If the subject contains real translucency — glass, smoke, fine hair, fur — expect the alpha matte to compress mid-range opacities toward 0 or 1. Many production checkpoints are trained on data that under-represents semi-transparent regions. The model learns that confident decisions get rewarded and ambiguous ones get punished, so it stops predicting α = 0.4 and starts rounding.
If you feed it an image with multiple plausible subjects — two people of equal prominence, an object held in front of another object — expect inconsistency. Salient object detection is single-subject by default. It picks the most visually salient region and discards the rest, which is exactly what you do not want when “the subject” is “this person plus the umbrella they are holding.”
Rule of thumb: A binary mask is fine for a product on a white seamless. You need an alpha matte the moment hair, glass, fabric, or motion blur touches the boundary.
When it breaks: The dominant failure mode is mid-opacity collapse — the model produces a confident-looking mask everywhere except at fine fringes, where it rounds the alpha values toward 0 or 1 and you get either a halo or a missing strand of hair. No amount of post-processing fully fixes a mask that has lost its in-between values; the information was never predicted.
Why Diffusion Did Not Replace Segmentation
A reasonable question, given the trajectory of generative models: why isn’t this just a Diffusion Models task by now? The answer is that segmentation and generation optimize for different things.
Diffusion models excel at hallucinating plausible content. They are creative by design — at every denoising step, they add detail consistent with their prior. That is exactly the wrong behavior for background removal, where the goal is to preserve the source pixels of the foreground exactly and discard the rest. A segmentation model is asked to be honest about which pixels exist; a diffusion model is asked to invent pixels that should exist.
The role of diffusion in AI Image Editing pipelines is downstream of segmentation. You isolate the subject with a matting model, then a diffusion model regenerates the new background or extends the canvas. The two technologies layer; they do not compete.
The Data Says
AI background removal is a stacked pipeline, not a single model: salient object detection finds the subject, alpha matting refines the boundary into per-pixel opacity, and a single neural forward pass now does both. The mask quality you see in practice is dominated by the alpha branch — by whether the model predicts the in-between values that hair, glass, and fabric edges actually require.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors