What Is AI-Assisted Refactoring and How Agentic Tools Restructure Code Without Breaking It
Table of Contents
ELI5
AI-assisted refactoring is when an agent reshapes existing code — renaming, splitting, moving functions — without changing what the code does. It parses the program into a structural tree, edits the structure, then runs the tests to confirm behavior held.
Until recently, refactoring was a careful manual ritual. You’d rename one function, watch the test suite light up, chase down the call sites your IDE missed, then do it all again in the next file. Now an agent does it across hundreds of files in a single session, sometimes touching languages your team doesn’t even read fluently. The unsettling part is not that this works. It’s that it works so often without the codebase quietly exploding.
That is the anomaly worth looking at. Most people assume these tools are doing something like very fast find-and-replace with a confident tone. They aren’t. The operation happens on a different representation of your code entirely — and once you see which one, the rest of the behavior stops being mysterious.
The Syntax Tree Is Where the Work Actually Happens
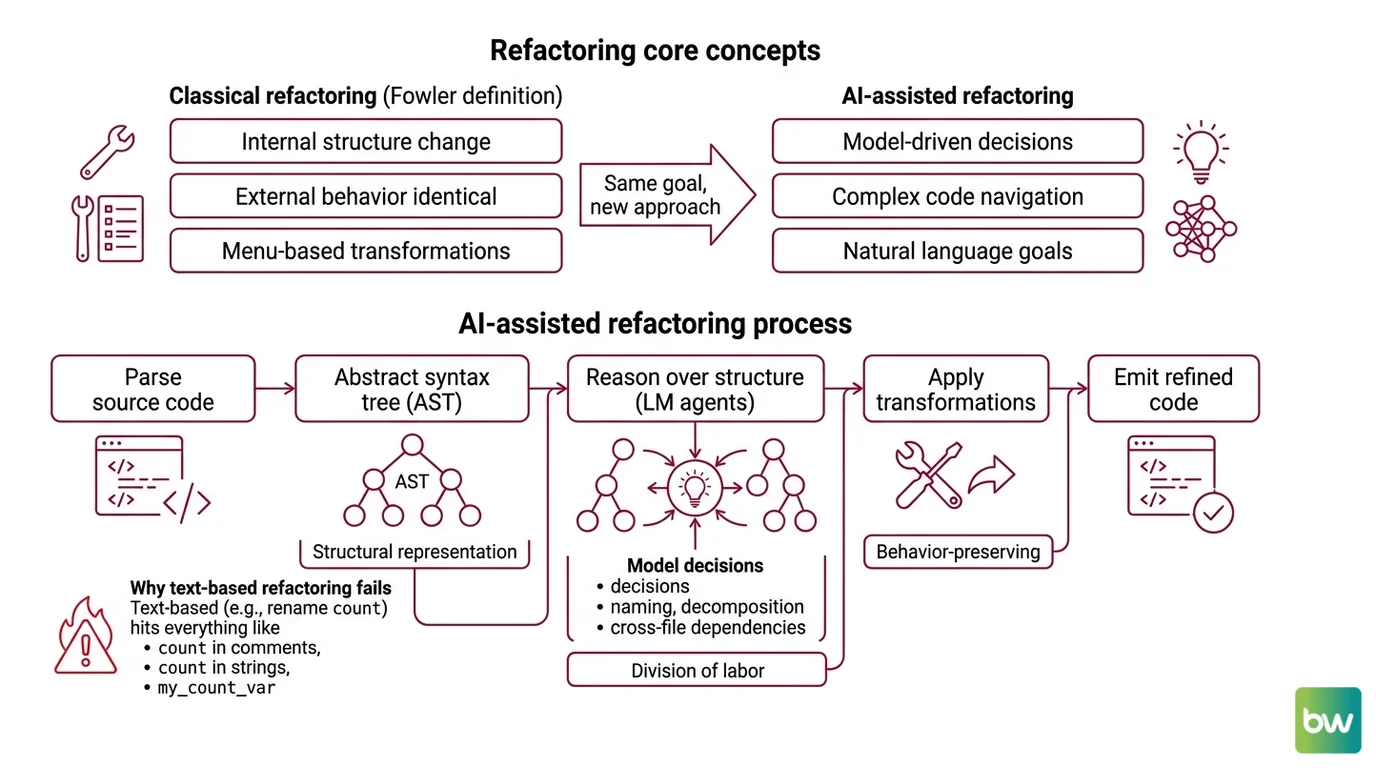
A refactoring tool that operated on raw text would be a disaster. Renaming a variable called count would also touch the word count inside string literals, inside comments, inside method names that happen to contain it. Classical refactoring tools solved this decades ago by working on a structural representation called the Abstract Syntax Tree, or AST. Modern agentic tools inherit that idea — they just wrap a language model around it.
Martin Fowler defined refactoring as a “disciplined technique for restructuring an existing body of code, altering its internal structure without changing its external behavior” — a series of small behavior-preserving transformations (Martin Fowler). That definition is the constraint the entire field is trying to satisfy. Internal structure: free to move. External behavior: must stay identical.
What is AI-assisted refactoring?
AI-assisted refactoring is the use of language-model-driven agents to perform those behavior-preserving transformations across a codebase, with the model handling the decisions that classical IDE refactorings could not — naming, decomposition, design-pattern selection, untangling cross-file dependencies. The mechanism, according to IBM Think, is to parse source into an Abstract Syntax Tree, reason over the structure, apply semantics-preserving transformations, and then emit code (IBM Think).
The phrase “reason over structure” is doing a lot of work in that sentence. It is also where the language model enters the picture. Classical refactoring tools could only apply transformations a human chose from a fixed menu — Extract Method, Rename Symbol, Inline Variable. The agent’s contribution is choosing which transformation to apply, where, and in what order, against a goal stated in natural language. The transformation engine itself is mostly conventional compiler machinery.
Not a glitch in the abstraction. A division of labor.
How does AI-assisted refactoring work across multiple files?
Single-file refactoring is the easy case. A function rename inside one file is local — the agent can see the whole problem at once. Cross-file refactoring is where most tools used to fail, because the model couldn’t fit the whole codebase into its context window, and even if it could, it would drown in irrelevant code.
The fix is a structure called a repository map. Aider builds one using tree-sitter parsers and ranks files by running PageRank over a dependency graph, then trims the result to fit a token budget — about 1,000 tokens by default via the --map-tokens flag (Aider docs). The PageRank step is the interesting part. It treats the codebase as a directed graph where files point at the symbols they import. The files with the most inbound references — your core utilities, your domain models — float to the top. The model sees those even when it doesn’t see the leaves.
Aider’s parsers cover more than 130 languages through tree-sitter grammars and tags.scm query files (Aider blog). Claude Code follows the same shape: it builds a dependency map, identifies call sites, makes coordinated multi-file changes, and runs the test suite before presenting a result (Anthropic). The map is not a search index — it is a compressed model of where the relevant structure lives, so the planner-LLM is reasoning about a few hundred well-chosen lines instead of a few hundred thousand.
This is the conceptual relative of AI Code Completion, but inverted. Completion predicts the next token forward from a cursor. Refactoring projects backward from a target structure and asks which edits would produce it.
Inside the Refactoring Agent
The agent that performs all this is not a single model. It is a small pipeline of components, each doing a job the language model alone would do badly.
What are the core components of an AI refactoring agent?
Combining the descriptions from IBM Think and the Aider documentation, five components recur across current systems:
| Component | Role | Why a Pure LLM Can’t Do It |
|---|---|---|
| AST / tree-sitter parser | Turns source text into a structured tree | LLMs read tokens, not syntax — the parser gives them ground truth about structure |
| Repo map / dependency graph | Compresses the codebase into the few hundred symbols that matter for this task | Context windows can’t hold every file; relevance must be pre-computed |
| Planner-LLM | Decides which transformations to apply and in what order | This is the open-ended reasoning step — what classical refactoring tools left to humans |
| Edit-applier | Translates planner decisions into surgical diffs against the AST | LLMs hallucinate when asked to emit large code blocks verbatim; a separate applier reduces this |
| Test/verification loop | Runs the existing test suite to confirm external behavior held | The mathematical guarantee of “behavior-preserving” is what the tests provide post hoc |
Aider made the planner/applier split explicit. According to the Aider docs, a high-level reasoning model proposes the change, and a separate “coding” model applies surgical diffs — a two-step pattern that keeps hallucination rates low on complex refactors (Aider docs). The reasoning model is allowed to be expensive and slow. The applier is cheap and constrained to small, mechanical edits.
The test-loop is what closes the contract. A refactor that passes the existing test suite is, operationally, behavior-preserving with respect to whatever those tests actually cover — which is exactly the same guarantee a careful human gets, no more and no less. The relationship to AI Test Generation is direct: tools that can also generate missing tests before refactoring extend the verifiable surface area, which extends the safe refactoring radius.
A configuration file at the repo root — CLAUDE.md for Claude Code or .cursorrules for Cursor — gives the agent persistent memory about project conventions, preferred patterns, and rules it should not violate (Anthropic; Cursor docs). It is the agent’s project README, written for an agent rather than a new hire.
What This Predicts About How the Tools Behave
Once you see the architecture, several observed behaviors stop being surprising and become predictable.
- If the test suite is thin, the safe refactoring radius shrinks. The verification loop can only confirm what the tests assert. This is why teams with strong coverage report dramatically smoother experiences than teams with sparse coverage.
- If the dependency graph is tangled, the repo map degrades. PageRank assumes there are central files. In a codebase where every file imports everything, the ranking flattens and the planner-LLM loses its guidance.
- If you ask for a transformation the planner cannot decompose into local AST operations — “make this monolith microservices” — the agent will either refuse, hallucinate a plan that does not survive the test loop, or produce something syntactically plausible but semantically wrong.
The SWE-Refactor benchmark, introduced in February 2026, formalized this. It contains 1,099 developer-written, behavior-preserving refactorings mined from 18 Java projects — 922 atomic single-step changes and 177 compound multi-step ones (SWE-Refactor paper). Evaluated against it, DeepSeek-V3 reached 41.58 percent and GPT-4o-mini reached 39.85 percent, with larger general-purpose models outperforming open-source code-specialized ones (SWE-Refactor paper). Even the strongest current systems succeed on fewer than half of professional-grade refactorings when tested rigorously.
That gap matters for how you use these tools. On SWE-bench Verified — the broader software-engineering benchmark — Claude Code reports 80.8 percent (Anthropic). The two numbers are not contradictory. SWE-bench Verified measures end-to-end issue resolution across many task types. SWE-Refactor isolates the specific challenge of behavior-preserving repository-level refactoring, where ground truth is unforgiving. The harder benchmark exposes the harder problem.
Rule of thumb: trust the agent for refactors that classical IDE tools could have done if a human had pointed at every site — renames, extractions, signature changes, mechanical migrations. Treat anything that requires inventing new abstractions as drafting, not refactoring, and review the diff the way you’d review a junior PR — which is to say, with AI Code Review habits, not blind acceptance.
When it breaks: the agent’s plan is only as good as its repo map and its tests. In codebases with circular imports, dynamic dispatch, or reflection-heavy patterns, the dependency graph misses real call sites; in codebases without tests, the verification loop cannot detect when behavior silently drifted.
The Deeper Shift
Classical refactoring assumed a human planner and a mechanical applier. Modern IDE tools made the applier safer by adding AST-level transformations. Agentic tools invert the assumption: the applier is now the conservative, deterministic part, and the planner is the open-ended language model.
That inversion is what makes cross-file work tractable, and it is also what makes the failure modes new. A bad classical-tool refactor failed loudly — a syntax error, a compile failure. A bad agentic refactor can pass syntax checks, pass type checks, and still introduce subtle semantic drift that only a careful human or a thorough test suite catches. This is the same boundary that defines AI-Assisted Debugging: the agent can find what its model of the system predicts, and is structurally blind to what its model omits.
The Data Says
AI-assisted refactoring works because it grafts language-model reasoning onto the same AST-and-dependency-graph machinery that classical refactoring tools have used for decades. The agent does not edit text — it plans transformations over structure, then verifies behavior with the existing test suite. The size of the safe radius is set by the quality of two artifacts the model does not produce: the dependency graph and the test coverage.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors