What Is Agentic RAG and How LLM Agents Decide What to Retrieve
ELI5
Agentic RAG turns retrieval into a decision, not a step. An LLM agent decides whether to fetch documents, where to look, how to phrase the query, and whether the answer is good enough — looping until it is.
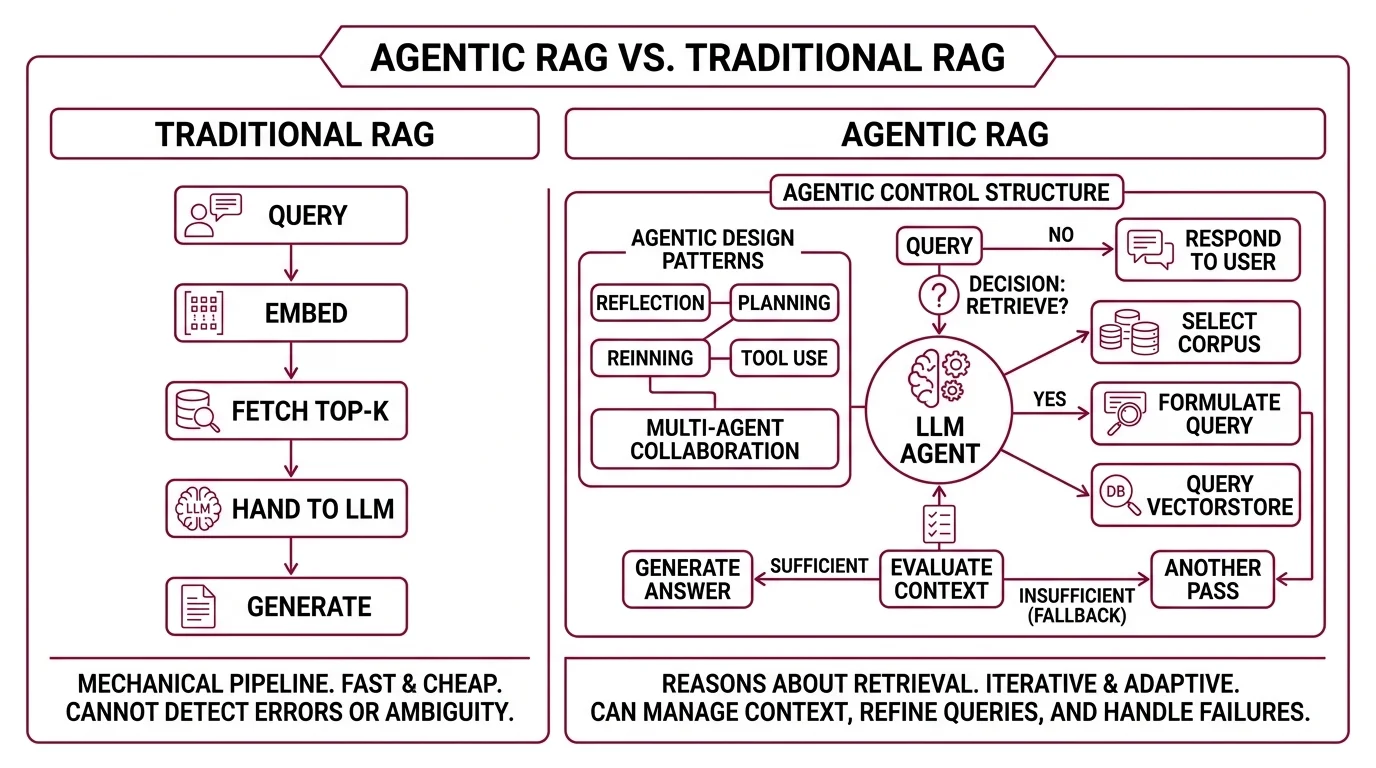
A traditional Retrieval Augmented Generation pipeline answers every question the same way: query, retrieve, generate. The system never asks whether the question even needs retrieval, whether one corpus is enough, or whether the documents that came back are any good. It just generates. That single design choice — to retrieve unconditionally and trust whatever comes back — is the source of more production failures than most teams admit.
When Retrieval Stopped Being a Pipeline Step
The classic RAG architecture is mechanical: embed the query, fetch the top-k chunks, hand them to the LLM, generate. The pipeline runs identically whether the query is a definition, a multi-hop research question, or a greeting that needs no documents at all. Every input gets the same treatment because the pipeline has no way to differentiate.
Agentic RAG breaks that symmetry. It treats retrieval as something to reason about, not just execute.
What is agentic RAG?
Agentic RAG embeds autonomous LLM agents into the retrieval pipeline and uses agentic design patterns — reflection, planning, tool use, multi-agent collaboration — to dynamically manage retrieval and adapt the workflow (arXiv 2501.09136). The agent decides whether to retrieve, which source to query, how to formulate the query, and whether the retrieved context is sufficient or needs another pass (Weaviate Blog).
The LangChain framing is even sharper: “An LLM makes a decision about whether to retrieve context from a vectorstore or respond to the user directly” (LangChain Docs). That single decision is the seed of the whole architecture. Once you let the model choose whether to retrieve, you have to give it the apparatus to make every adjacent decision too — which corpus, which query phrasing, which fallback if the first attempt returns junk.
Not a feature on top of RAG. A different control structure underneath it.
How does agentic RAG work compared to traditional RAG?
Traditional RAG is linear — query, retrieve, generate. It is faster and cheaper, but static; it cannot detect that the wrong documents came back, that the question was ambiguous, or that no retrieval was needed at all (NVIDIA Developer Blog).
Agentic RAG is iterative. The agent “queries, refines, uses RAG as a tool, manages context over time” (NVIDIA Developer Blog). The LangGraph reference implementation makes this concrete: the graph contains five nodes — generate_query_or_respond, retrieve, grade_documents, rewrite_question, generate_answer — and two explicit decision points where the LLM chooses what happens next. First, decide whether to retrieve at all. Second, grade the retrieved documents and either answer or rewrite the question and try again (LangChain Docs).
The behavioral difference is visible in production. A traditional pipeline returns wrong-but-plausible passages and the model hallucinates around them; the user sees fluent, confident, incorrect output. An agentic pipeline notices that the retrieved chunks do not answer the question, rewrites the query — perhaps splitting it, perhaps generalizing it — and retrieves again. The same model, the same vector store, dramatically different output.
This is also where Query Transformation, Hybrid Search, and Reranking stop being optional optimizations. They become the actions an agent can take. An agent without tools is just a chatbot with extra steps; an agent with tools but no grader is a chatbot that retrieves more often. The grader is what closes the loop.
The Components That Make a Retrieval Agent
The components are not arbitrary. They map directly onto the decisions the agent has to make, and removing any one of them collapses the architecture back into a fancier pipeline.
What are the core components of an agentic RAG system?
Weaviate’s reference architecture decomposes the retrieval agent into four parts: an LLM with a defined role and task, memory (short- and long-term), planning (reflection, self-critique, query routing), and tools (calculators, web search, APIs, vector databases) (Weaviate Blog). The pattern that ties them together is the ReAct loop — Thought, Action, Observation, repeated until the task is complete.
Each component exists because removing it breaks a specific decision the agent needs to make:
- LLM with role — without a role and task, the agent has no objective to reason about, and “should I retrieve?” becomes meaningless.
- Memory — without it, the agent cannot remember what it already retrieved or which rewrite it already tried; loops become amnesiac and start repeating themselves.
- Planning — without reflection and self-critique, the agent cannot distinguish a useful document from a near-miss, and
grade_documentsreturns “good” for everything. - Tools — without tools, the agent has nothing to choose between, and routing collapses into a default path.
The minimal pattern is the single-agent router: one agent decides whether to query a vector database, run a web search, or call an external API (Weaviate Blog). The maximal pattern is multi-agent — a master agent coordinates specialized retrieval agents, each owning a different knowledge surface (proprietary data, personal accounts, public web). Singh et al.’s survey formalizes the design space with four taxonomy axes: agent cardinality, control structure, autonomy, and knowledge representation (arXiv 2501.09136).
LlamaIndex takes a different cut at the same problem. Instead of an explicit graph of nodes, it routes queries through
Contextual Retrieval layers: an LLM-based classifier picks which sub-index is relevant, then chooses among retrieval modes — chunk, files_via_metadata, files_via_content — wrapped in LlamaParseCompositeRetriever with CompositeRetrievalMode.ROUTED (LlamaIndex Blog). Different framework, same underlying control structure: the LLM decides what to retrieve before retrieving it.
What This Architecture Predicts About Retrieval Failure
The agent-as-controller pattern makes specific, falsifiable predictions about when retrieval will succeed and where it will quietly fall apart.
- If the query is unambiguous and the relevant documents are dense in the corpus, traditional RAG and agentic RAG produce nearly identical answers — the agent’s decision points don’t change anything because the easy path was already correct.
- If the user’s question is malformed or ambiguous, agentic RAG outperforms by rewriting before retrieving. Traditional RAG bakes the malformation into the embedding and pulls back the wrong region of vector space.
- If the relevant information lives across multiple sources — internal docs plus the live web, for instance — multi-agent routing helps. A single-pipeline RAG cannot reach what the embedding model never indexed.
- If the corpus is small and well-curated, the overhead of agentic decision-making outweighs the benefit. The agent spends tokens choosing between options that don’t meaningfully differ.
Rule of thumb: Add agency where the retrieval decision is non-trivial — multiple sources, ambiguous queries, or context budgets too tight to dump everything into the prompt. Skip it where a single corpus and well-formed queries already work.
When it breaks: Agentic RAG fails when the agent’s grader is miscalibrated. If grade_documents consistently labels poor retrievals as good (or good ones as bad), every downstream loop amplifies the error — the system retrieves more aggressively or rewrites prematurely, and latency, token cost, and hallucination rates all climb together. The architecture only helps as much as the grader is honest.
Compatibility notes (frameworks named in this article, mid-2026):
- LangGraph 2.0 (Feb 2026): Breaking change to
StateGraphinitialization. Use thelangchain migrate langgraphCLI script to migrate older graphs (LangChain Blog).langgraph.prebuilt: Deprecated; functionality has moved tolangchain.agents(LangChain Docs).- LlamaIndex Workflows 2.0: Breaking release alongside removal of Python 3.9 support (PR #20956, March 2026); older Query Pipelines are deprecated in favor of event-driven Workflows (LlamaIndex Changelog).
The Data Says
Agentic RAG is not a new retrieval algorithm. It is a control-structure shift: the LLM stops being the consumer of retrieved context and becomes the controller of retrieval itself. The pattern is reproducible across LangGraph, LlamaIndex, Weaviate, and NVIDIA’s reference stacks — but the mechanism is fragile in exactly one place: the quality of the agent’s self-grading. Get that wrong and every loop makes the system worse rather than better.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors