What Is Agentic Coding and How Plan-Write-Test-Iterate Loops Replace Manual Development

Table of Contents
ELI5
Agentic coding is when an AI plans a change, writes the code, runs your tests, reads the failures, and loops again — using real dev tools inside your actual codebase, not just suggesting in a chat.
Here is the part that should not be possible. Take a single base model — fix the weights, freeze the temperature, leave the training data untouched. Then run it through two different scaffolds on the same benchmark. The scores can swing by fifteen points or more on SWE-Bench Verified, the most-cited test of real-world bug fixing. The model did not get smarter between runs. The system around it did.
That is the gap where agentic coding lives. Most of the interesting behavior is not in the model card.
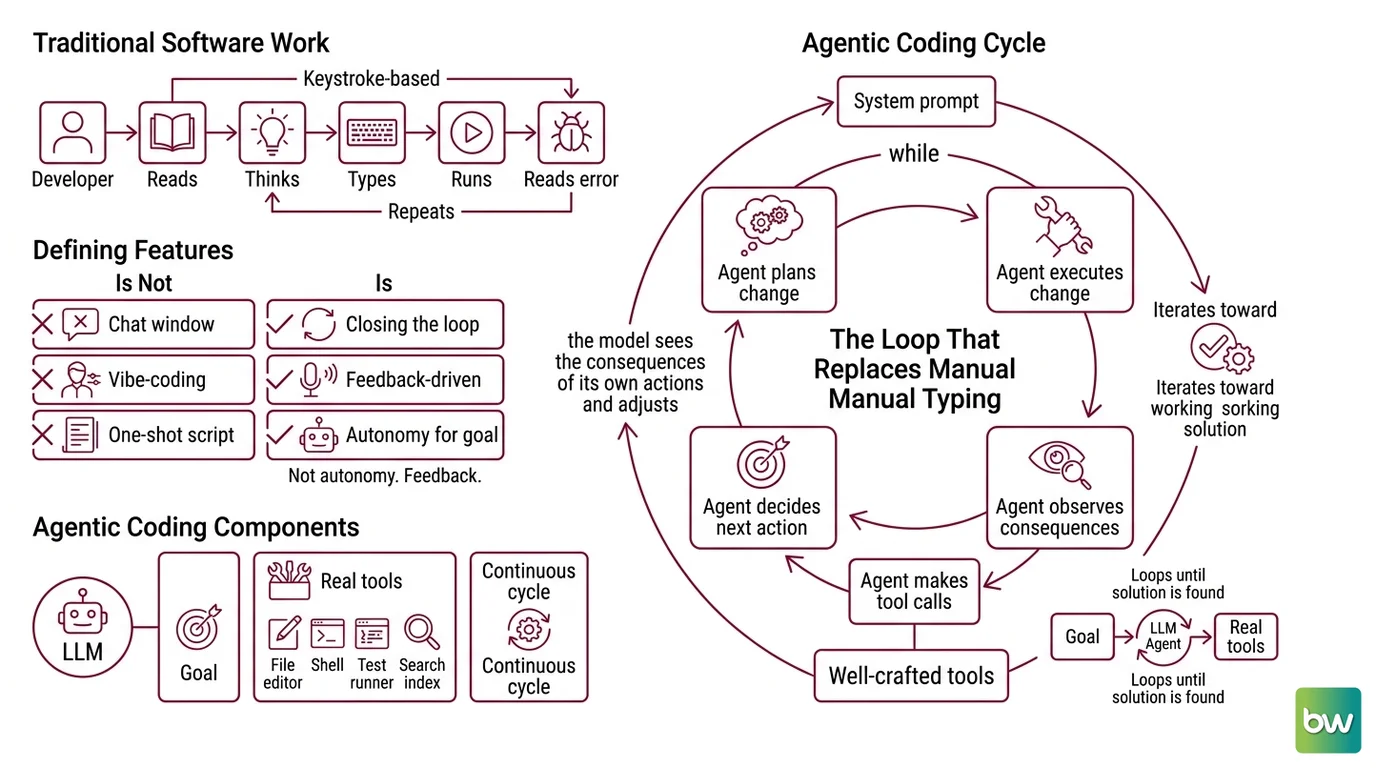
The Loop That Replaces Manual Typing
For thirty years, the unit of software work has been the keystroke. A developer reads, thinks, types, runs, reads the error, repeats. Agentic coding compresses that cycle into a control flow the model runs by itself — slowly at first, then continuously. The interesting question is not whether the AI can write a function. It is what happens when the AI is also the one running it.
What is agentic coding?
Agentic coding is the practice of giving a LLM a goal and a set of real development tools — a file editor, a shell, a test runner, a search index — and letting it iterate toward a working solution. The model does not just complete a line. It plans the change, executes the change, observes what happened, and decides what to do next. The outer envelope is autonomy; the inner content is still ordinary code and ordinary tests.
The simplest formal description of this comes from a Braintrust engineering note that calls it “the canonical agent architecture”: a while loop that makes tool calls, parameterized by a system prompt and a set of well-crafted tools. Claude Code uses it. The
OpenAI Agents SDK uses it. The pattern is now so dominant that frameworks differ mostly in the shape of the tools they hand the model, not in the loop itself.
It is worth saying clearly what agentic coding is not. It is not a chat window with a copy button. It is not Vibe Coding, where a user steers an LLM through a UI without ever reading the diff. And it is not a one-shot script generator. The defining feature is the closing of the loop — the model sees the consequences of its own actions and adjusts.
Not autonomy. Feedback.
How do agentic coding tools like Claude Code and Devin work?
Different products draw the loop with different boundaries, but the underlying machinery rhymes.
Claude Code runs in your terminal — Anthropic ships it as a CLI with VS Code and JetBrains extensions, and it connects to external services through the Model Context Protocol (Claude Code Docs). When you give it a task, it reads the codebase, drafts a plan, edits files, runs the tests, and reacts to the output. It scores 87.6% on SWE-bench Verified on the Claude Opus 4.5 backbone (Awesome Agents leaderboard) — currently the strongest mainstream agentic coder on that benchmark. Pricing runs from Pro at $20/mo to Max 20x at $200/mo for the consumer plans, with API access metered between $0.80 and $75 per million tokens depending on tier (Claude pricing page).
Devin, from Cognition Labs, occupies the opposite end of the spectrum. It positions itself as a delegate-style agent: assign a ticket, walk away, return to a pull request. A Feb 2026 update added parallel sessions and improved context retention, letting one operator run several Devin instances at once. Its SWE-bench Verified number sits at 45.8% unassisted (Awesome Agents leaderboard) — lower than Claude Code, but the comparison is not apples to apples. Claude Code assumes a human in the loop; Devin assumes the human has gone to bed.
OpenAI Codex CLI adds a “goal mode” that runs unsupervised for hours on its GPT-5.5 backbone. Cursor, the AI-native VS Code fork, takes a hybrid path: a local IDE for direct manipulation, plus cloud sub-agents for long-running work.
The differences in the brochure look large. Under the hood, all four products are running the same loop. They differ in three places: the quality of the planning, the breadth of the tools, and how much they let the model do before checking in with a human.
Anatomy of a Coding Agent
Strip the marketing language away and any agentic coding system is built from four working parts and one structural pattern that ties them together. The parts are not new — language models, memory, planning, and tool use have all been studied separately for years. The interesting thing is what happens when they share a control loop. The shape of that loop is what makes a coding agent feel less like an autocomplete and more like a junior engineer who keeps trying until the build is green.
What are the core components of a coding agent architecture?
The Oracle Developers Blog gives the cleanest decomposition: an agent is an LLM plus memory plus planning plus tool use, organized by an agent loop. Each component has a job, and the loop is where they meet.
| Component | Job in a coding agent | What it looks like in practice |
|---|---|---|
| LLM | The reasoner — chooses what to do next | Claude Opus 4.5, GPT-5.5, Gemini 3.x |
| Memory | Keeps task state across turns; recalls past decisions | Conversation context + file-system scratch + repo index |
| Planning | Decomposes a goal into ordered subgoals | “Read failing test → locate function → patch → re-run” |
| Tool use | The hands — calls into real systems | File edit, shell, test runner, git, web fetch, MCP servers |
The loop itself comes from the same Oracle reference and has five stages: Perceive → Reason → Plan → Act → Observe. The model perceives the current state of the world (the open files, the last command output), reasons about what it means, picks the next step, executes it through a tool call, then observes the result and goes back to perceive. The cycle terminates when the model believes the task is done or when a budget — token, time, or step — runs out.
There is a more pragmatic framing that engineering teams have converged on, sometimes called the Plan-Implement-Validate or PIV loop. Tests are not an afterthought; they are the validation step that closes the cycle. A failing test feeds back into the next planning step as a structured grievance — “your patch broke test_authorize_admin” — and the agent’s job is to read that grievance and respond to it. Code-test-fix-repeat.
Tool use is where most production systems live or die. MCP matters here because it standardized how an agent reaches the outside world. It is an open JSON-RPC 2.0 protocol with three primitives — tools, resources, and prompts — that lets an LLM application talk to file systems, databases, browsers, and CI without bespoke glue per integration (MCP specification). It was donated to the Linux Foundation’s Agentic AI Foundation in December 2025; calling it “Anthropic’s protocol” is now a year out of date.
For coding work, the Claude Agent SDK packages this pattern as a library, and the OpenAI Agents SDK provides the analogous primitives for the OpenAI stack. They are different boxes around the same loop.
What the Loop Predicts About Your Workflow
Once the mechanism is clear, several second-order effects follow from it directly. They are predictions, not opinions.
- If the scaffold matters more than the model, you should expect benchmark scores to move when the same provider ships a new prompt or a new tool — not only when they ship a new model. The 15+ point spread on SWE-Bench Verified for one base model in different scaffolds (CodeAnt) is the strongest evidence here. Treat scaffold updates as model updates.
- If the feedback signal is the test suite, an agent in a repo with weak tests will behave roughly like an over-confident new hire. The agent’s “I am done” depends on the loop’s “the tests passed” — no tests means no signal.
- If the tool surface is the bottleneck, then the largest productivity gains come not from a smarter model but from cleaner tools. A reliable codebase index, a fast test runner, and a one-line MCP server for your internal docs often beat a model upgrade.
- If the loop runs autonomously for hours, costs scale with steps, not with prompts. OpenAI Codex CLI’s goal mode is a useful warning here: an unsupervised loop is a budget question first, a capability question second.
Rule of thumb: an agentic coding setup is only as strong as its weakest tool. Upgrade the test runner before you upgrade the model.
When it breaks: the loop has no notion of intent beyond the goal you handed it. A test that passes by accident, a patch that silences an error instead of fixing it, or a brittle integration that the agent decides to delete are all valid moves inside the loop. Agentic coding closes the inner loop of code-test-fix; it does not close the outer loop of was this the right thing to build. That outer loop is still yours.
Why the Scaffold Quietly Eats the Model
There is a deeper consequence sitting underneath the benchmark numbers, and it changes how to think about vendor lock-in.
For a generation of developer tools, “the model” was the product. Choosing a coding assistant meant choosing OpenAI or Anthropic, and the differences in raw capability were the differences that mattered. That framing is fading. When the same base model can swing 15+ points on SWE-Bench Verified depending on the agent harness wrapped around it (CodeAnt), the scaffold has become a first-class engineering artifact. It is not packaging. It is the product.
This explains some otherwise odd shipping patterns. Anthropic ships Claude Code as a separate product line rather than as a feature of the Claude API. Cognition builds Devin almost entirely above its model layer, with the planning and memory architecture treated as core IP. Cursor’s value proposition is largely the editor surface plus the cloud sub-agent layer. In each case the model is rented; the loop is owned.
For anyone planning a serious investment in agentic coding — including AI Code Migration work across large legacy codebases — this is the part to take seriously. Switching the underlying model can be a one-line change. Switching the scaffold is a re-platforming exercise.
Security & compatibility notes (per Microsoft Security Blog and Novee Security, 2026):
- Cursor IDE (CVE-2026-26268): Critical vulnerability — arbitrary code execution via Git hooks when the agent operates on untrusted repositories. Do not point Cursor’s agent at repos you would not run a stranger’s
makein.- Semantic Kernel .NET SDK (CVE-2026-25592, CVE-2026-26030): Prompt-injection paths to unauthorized code execution; fix in 1.71.0+.
- CrewAI: Four CVEs chain Prompt Injection into RCE/SSRF/file reads via Code Interpreter defaults — keep the interpreter sandboxed and never enable it on untrusted input.
The Data Says
Agentic coding is not a smarter chatbot; it is a control loop wrapped around an LLM, in which tools are the senses and tests are the verdict. The visible product — Claude Code, Devin, Codex CLI, Cursor — is overwhelmingly the scaffold, and the scaffold is where benchmark scores actually move. As of 2026, Claude Code on Claude Opus 4.5 leads the production end of the SWE-bench Verified board at 87.6% (Awesome Agents leaderboard), with the Claude Mythos Preview research model showing an upper-bound 93.9% — but the headline number is less important than the geometry of the loop that produced it.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors