Agent Planning and Reasoning: ReAct, Plan-and-Execute, Reflexion
Table of Contents
ELI5
Agent planning and reasoning is the loop that lets a Large Language Model decompose a goal, pick a tool, observe the result, and revise. It is token generation conditioned on prior actions — not human deliberation.
You hand a Large Language Model a goal — “book a flight under three hundred dollars and email me the itinerary” — and watch it compose a chain of tool calls that mostly works. It feels like the model is thinking through the task, the way a careful colleague would. That feeling is the most important misconception in the field, because the moment you treat the agent as a planner with intent, you stop noticing the places where the loop is silently drifting away from your goal. The mechanism is far less mysterious, and far more brittle, than it looks.
The Loop Behind the Curtain
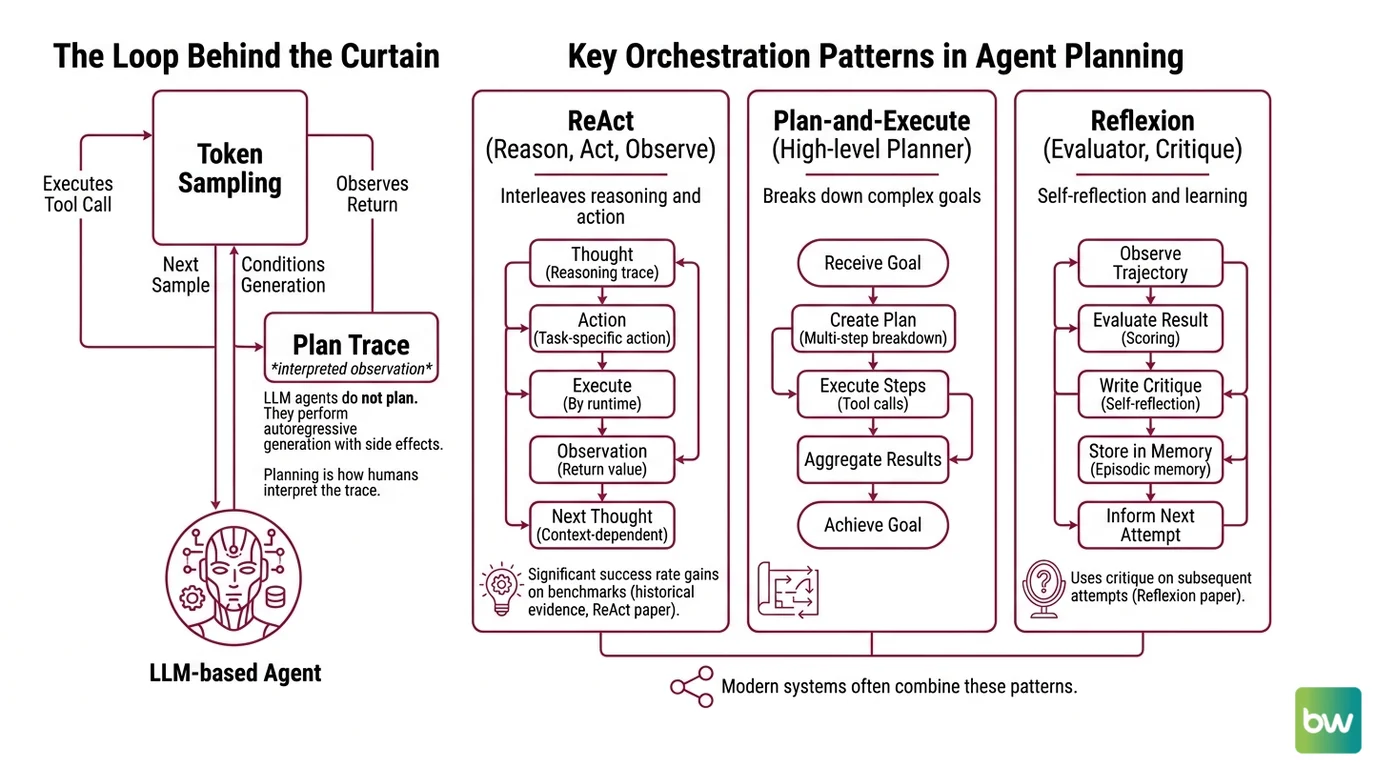
Before any specific framework, there is a structural fact: an LLM-based agent does not plan. It samples tokens, executes whichever tokens parse as a tool call, observes the return value, and conditions the next sample on everything that came before. Planning is what we call the trace. The runtime is doing autoregressive generation with side effects.
What is agent planning and reasoning in AI?
Agent planning and reasoning is the family of prompting and orchestration patterns that turn a single LLM call into a multi-step problem solver — by routing the model’s output through tool invocations, observations, and conditional re-prompting. Three patterns dominate the literature: ReAct, Plan-and-Execute, and Reflexion. They are complementary, not competing, and modern systems usually combine them.
ReAct, introduced by Shunyu Yao and collaborators in October 2022 (ReAct paper), interleaves reasoning traces and task-specific actions in a single generation stream. The model emits a thought, then an action; the runtime executes it; the resulting observation is appended to the context; the model emits the next thought. The original implementation produced absolute success-rate gains of around thirty-four points on the ALFWorld household-task benchmark and ten points on WebShop — using only one or two in-context examples (ReAct paper). Those numbers are historical: they were measured against GPT-3 and PaLM-class models, and modern frontier systems clear those benchmarks at much higher absolute scores. Cite them as evidence that interleaving reasoning with action helps, not as current state of the art.
Reflexion, introduced by Noah Shinn and collaborators at NeurIPS 2023 (Reflexion paper), is a different beast. It does not replace the action loop — it watches it. After a trajectory finishes, an Evaluator scores the result, and a Self-Reflection module writes a short verbal critique into episodic memory. On the next attempt, that critique becomes part of the prompt. The system updates through language, not gradients.
Plan-and-Execute, popularised by the LangChain team, separates the two jobs. A Planner — usually a stronger model — produces an explicit multi-step plan up front. Executors then march through the plan, each invoking tools for one sub-task, often using cheaper models (LangChain Blog).
The geometry of the three patterns differs, but the substrate is identical: each one is a way of feeding the next sampled token a richer prefix.
How do AI agents decompose goals into subtasks and execute plans?
Decomposition is not a separate cognitive faculty bolted onto the model. It is what happens when you prompt for it.
In ReAct, decomposition emerges implicitly. The thought-action-observation pattern gives the model permission to write down sub-goals as part of its reasoning trace, but no part of the architecture forces the plan to stay coherent end-to-end. The trajectory can — and frequently does — wander mid-stream, gravitate toward a tool that has worked before, or stall in a “thought loop” where the trace reasons about reasoning without ever emitting an action.
Plan-and-Execute makes decomposition explicit. The Planner is asked, in one shot, to output the full sequence of sub-tasks before any tool runs. The architecture promises three benefits, according to the framework’s authors: lower cost (sub-tasks can be routed to smaller models), lower latency (fewer round-trips through the expensive planning model), and higher quality from forcing upfront thinking (LangChain Blog). Those are architectural claims based on framework analysis; no peer-reviewed head-to-head benchmark comparing Plan-and-Execute against ReAct on identical tasks is cited.
Reflexion handles the failure mode neither of the others addresses: what happens when the plan was wrong. After a trajectory completes and the Evaluator scores it, the Self-Reflection module writes something like “I searched for the product before checking the cart filters, which selected the wrong category — next time, filter first.” That sentence is stored in episodic memory and concatenated into the prompt for the next trial. Across the original benchmark suites, Reflexion reported absolute gains of roughly twenty-two points on decision-making tasks (after twelve iterations), twenty points on reasoning, and up to eleven points on Python programming (Reflexion paper).
Three patterns. Three different ways of arranging tokens in the context window so that the next sampled action is more likely to be the right one.
Bayesian conditioning, dressed in different costumes.
The Anatomy of an Agent
A working agent is not a single neural network — it is a small operating system in which the LLM is one process among several. Understanding its parts is the only way to debug what fails.
What are the core components of an agent planning system?
A 2024 survey by Huang and colleagues organises the entire field around five recurring components (Huang et al. 2024 survey):
| Component | What it does | Where you see it |
|---|---|---|
| Task Decomposition | Splits the goal into ordered sub-tasks | Planner in Plan-and-Execute; emergent in ReAct thoughts |
| Plan / Multi-Plan Selection | Generates and ranks candidate plans | Tree-of-Thoughts, ensemble planners |
| External Module / Planner | Delegates to a non-LLM solver (search, classical planner, code) | Tool-use layer in any framework |
| Reflection | Critiques outcomes and rewrites strategy | Reflexion’s Self-Reflection step |
| Memory | Persists state across turns and trials | Episodic memory in Reflexion; scratchpad in ReAct |
The Reflexion paper’s own decomposition is sharper because it isolates the loop’s three roles: an Actor that generates text and tool calls, an Evaluator that scores the trajectory against task-specific criteria, and a Self-Reflection module that turns numeric scores into natural-language guidance for the next attempt (Reflexion paper). Strip any one of these out and the system collapses back into a single-shot prompt.
The Agent Memory Systems layer is where most production failures hide. Short-term memory — the context window — fades. Episodic memory must be summarised to fit. Semantic memory drifts as new embeddings are added. When you read about a Multi Agent Systems setup that “remembers across sessions,” what is really happening is a careful dance of compaction, retrieval, and re-injection. None of it is free.
The Actor itself is interchangeable. Most production agents today are built on LangGraph, which reached version 1.0 in October 2025 and committed to no breaking changes until 2.0 (LangChain Changelog). The canonical ReAct implementation is exposed as create_react_agent. There are, however, two compatibility notes developers hit immediately.
Compatibility notes for new agent code:
- LangChain
AgentExecutor/initialize_agent: deprecated since LangChain 0.2; receives only critical fixes. Build new agents on LangGraph instead.langgraph.prebuilt: deprecated in LangGraph 1.0; functionality has moved tolangchain.agents. Thecreate_react_agentsymbol is still callable fromlanggraph.prebuiltas a re-export, but new imports should targetlangchain.agents(LangChain Docs).langchain.experimental.plan_and_execute: lives in theexperimentalnamespace; LangGraph templates are the recommended modern path for new Plan-and-Execute systems.
What Goes Wrong, Geometrically
The three patterns predict their own failure modes. If you understand the geometry, the failures stop feeling random.
- If you run a pure ReAct loop on a goal that requires many steps, expect the model to lose the plan thread mid-trajectory. The thought stream is conditioned on a context window that grows linearly with each tool call; relevant early constraints get diluted by recent observations.
- If you run Plan-and-Execute and the Planner is wrong about the world, every Executor will faithfully execute the wrong plan. The architecture has no in-flight correction primitive — that is what Reflexion was designed to add.
- If you run Reflexion without a strong Evaluator, the Self-Reflection step writes plausible-sounding critiques that are not actually grounded in the failure. Reflection without ground truth is a more articulate hallucination.
Rule of thumb: ReAct gives you reactivity, Plan-and-Execute gives you cost control, Reflexion gives you learning across attempts. Production systems usually need all three, layered.
When it breaks: The dominant production failure is silent context drift — the agent is technically still in the loop, but the goal stated several minutes ago has been overwritten by a stack of observations, and no Evaluator is watching for that specific failure. Without explicit goal re-anchoring or a Reflexion-style critic, the system completes a coherent trajectory toward the wrong destination.
Why It All Still Works
There is a second-order observation that is easy to miss. None of these patterns teach the model anything new. ReAct’s interleaved trace, Plan-and-Execute’s upfront decomposition, Reflexion’s verbal critiques — every one of them lives entirely inside the prompt. The weights are frozen. What is changing is which region of the model’s existing capability surface gets sampled.
That is the same mechanism that makes few-shot prompting work, scaled up to multi-step interaction. The agent’s apparent intelligence is the emergent shape of conditional probability, sculpted by the tokens you put in front of it.
Not autonomy. Conditioning.
The Data Says
Across the three foundational papers, the pattern is consistent: structured prompting beats unstructured prompting, and layered structured prompting beats any single layer alone. ReAct’s original gains were measured against models that no current frontier system would lose to, but the architectural insight survives. The interesting frontier is no longer which pattern wins — it is how to combine all three without paying the latency tax of three round-trips per sub-task.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors