Agent Evaluation: How Trajectory Analysis Measures AI Agents

Table of Contents
ELI5
Agent evaluation measures whether an AI agent reaches the right answer through the right path. Trajectory analysis grades the sequence of tool calls — not just the final output — so silent reasoning failures stop hiding behind correct results.
An agent answers a customer’s refund question correctly, then quietly burns fourteen tool calls to get there. A second agent answers wrong — but for an interesting reason: it queried the right database, retrieved the right rows, then misread one timestamp. If you grade only the final reply, both look identical to the rest of your evals: one pass, one fail. The path is invisible. That invisibility is the problem trajectory analysis was built to solve.
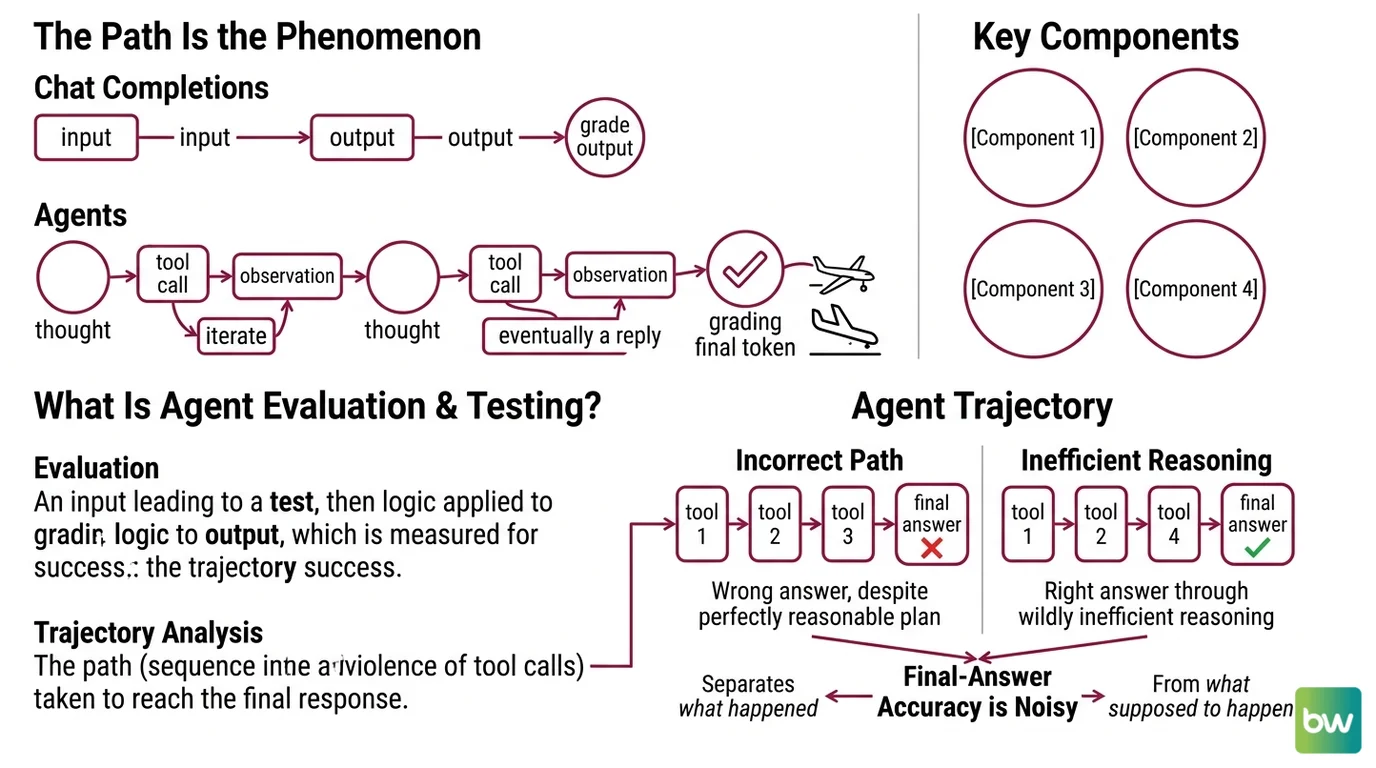
The Path Is the Phenomenon
Most evaluation frameworks were built for chat completions. Input in, output out, grade the output. Agents broke that contract. An agent does not produce one response — it produces a sequence: a thought, a tool call, an observation, another thought, another tool call, eventually a reply. Grading only the final token is like reviewing a flight by checking whether the plane landed.
Not an outcome. A trajectory.
What is agent evaluation and testing?
The Anthropic engineering team defines an evaluation as “a test for an AI system: give an AI an input, then apply grading logic to its output to measure success” (Anthropic Engineering). For an agent, “output” is a moving target. There is the final response, but there is also everything that happened before it — and the everything is where most failures live.
Google’s documentation defines an agent trajectory as “the path (sequence of tool calls) the agent took to reach the final response” (Google Cloud Docs). Trajectory analysis treats that path as a first-class object. You compare what the agent did against what it should have done — at the level of which tools were called, in what order, with what arguments — independent of whether the final answer happens to be correct.
The distinction matters because correctness is a noisy signal. An agent can produce a right answer through wildly inefficient reasoning. It can produce a wrong answer despite executing a perfectly reasonable plan. It can succeed by accident on Monday and fail by accident on Tuesday with the same prompt. Final-answer accuracy is a noisy single number that tells you very little about why your agent behaves the way it does.
Trajectory analysis separates the question of what happened from the question of what was supposed to happen. That separation is where engineering leverage hides.
What are the components of an agent evaluation framework?
Anthropic decomposes the discipline into a small set of moving parts: a Task (the input scenario), a Trial (one execution of the task), a Grader (the function that decides pass or fail), a Transcript (the complete record of the trial), and an Outcome (the graded result). The framework also distinguishes the agent harness — which runs the agent — from the evaluation harness, which runs the grading (Anthropic Engineering).
Read those names carefully. The Transcript is doing heavier work than it looks. Anthropic defines it as “the complete record of a trial, including outputs, tool calls, reasoning, intermediate results, and any other interactions” (Anthropic Engineering). That is the substrate trajectory analysis grades against. Without a faithful transcript, there is no path to evaluate — only an outcome.
The Grader is where mechanism choice happens. Three families dominate production today:
- Computation-based graders check the trajectory against a reference path with deterministic logic. Google’s Vertex AI ships six such metrics:
trajectory_exact_match,trajectory_in_order_match,trajectory_any_order_match,trajectory_precision,trajectory_recall, andtrajectory_single_tool_use(Google Cloud Docs). Precision asks what fraction of the agent’s tool calls appear in the reference. Recall asks what fraction of the essential reference tools the agent actually used. Both range from 0 to 1. - LLM-as-judge graders use a separate model to score trajectories against rubrics — useful when the “right” path is not a single canonical sequence but a family of acceptable ones.
- Human graders stay in the loop for ambiguous tasks and for calibrating the automated graders themselves.
The LangChain open-source library AgentEvals exposes a complementary axis. Its trajectory evaluators come in match modes — Strict, Unordered, Subset, Superset — that let you encode how strictly order and completeness matter (LangChain’s GitHub repository). Strict requires the exact sequence. Unordered allows reordering. Subset accepts partial coverage. Superset tolerates extra steps.
Pick a mode and you have implicitly stated your theory of what counts as correct behavior. That is a more honest engineering decision than picking a single accuracy threshold.
Anthropic’s practical advice on where to start: 20-50 tasks drawn from real failures (Anthropic Engineering). Not synthetic edge cases. Not benchmark suites. Failures the agent actually produced in the wild. The eval set is meant to model the distribution of problems the agent will see — not to flatter it.
How the Trajectory Gets Graded
A working evaluation pipeline is mostly plumbing. The interesting part lives upstream of the graders: you need a faithful, queryable record of every tool call the agent made, in production and in test, with enough structure that a grader can compare it to a reference.
How does agent evaluation work in production?
In a production system, the loop has three layers stacked on top of each other.
The bottom layer is telemetry. Every step the agent takes — model call, tool invocation, tool result, retry — is emitted as a span in a structured trace. The industry has been converging on OpenTelemetry as the trace standard, with frameworks like Pydantic AI, smolagents, and Strands Agents emitting OTEL spans natively (Braintrust). The shape of a span — a parent-child tree of timed operations — maps cleanly onto an agent trajectory. That alignment is not accidental; it is why OTEL won.
The middle layer is dataset and grader infrastructure. Traces from production get curated into evaluation datasets: real user inputs, the agent’s actual trajectory, and either a reference trajectory or a rubric the grader uses. LangSmith’s multi-turn evaluation scores three things at once — semantic intent, semantic outcomes, and the agent trajectory itself, including tool calls and decisions (LangChain Blog). Each layer answers a different question. Did the agent understand what the user wanted? Did it produce the right effect in the world? And did it get there by an acceptable path?
The top layer is regression. Once trajectories are graded, you can detect when a prompt change, a model swap, or a new tool integration silently degrades the path even though final-answer accuracy looks fine. This is where trajectory metrics earn their cost. They surface the failure mode before users notice it.
A small note on metrics that are easy to ignore. Google’s default agent metrics include latency (seconds to respond) and a failure boolean — 1 for an error, 0 for a valid response (Google Cloud Docs). Neither metric is glamorous. Both are where most production incidents start. A trajectory that grows from four tool calls to nine is not just slower; it is leaking margin every time it runs.
What the Trajectory Predicts
Once the path is graded, several useful predictions become tractable.
- If trajectory recall drops while final-answer accuracy stays flat, expect the agent to be silently skipping verification steps. The right answer is happening for the wrong reasons, and the wrong reasons will surface the moment the input distribution shifts.
- If trajectory precision falls, the agent is calling tools it does not need. Latency rises before quality does. Cost rises before either.
- If
trajectory_any_order_matchsucceeds buttrajectory_in_order_matchfails, the agent has the right plan but the wrong sequencing — a sign the prompt under-specifies dependencies between steps. - If an LLM-as-judge grader and a computation-based grader disagree systematically, the reference trajectory itself is probably wrong. Update the reference, not the agent.
Rule of thumb: grade the path before you grade the answer; the answer is downstream of everything the path determines.
When it breaks: trajectory analysis assumes the reference is a meaningful target. For tasks with many valid paths — open-ended research, creative work, multi-agent collaboration — strict trajectory matching produces noise that punishes legitimate variation. Use LLM-as-judge graders or rubric-based scoring for those domains, and reserve strict trajectory metrics for tasks with a small number of correct procedures.
The Data Says
As of 2026, 57% of organizations report agents in production and 32% cite quality as their top barrier to bringing agents into production — more than the next concern, latency at 20% (LangChain State of Agent Engineering). The same 2026 survey reports a related gap: roughly 89% of teams have implemented observability, while only 52% have implemented evaluations. Telemetry is being collected. The path is being recorded. Most teams have not yet built the grader.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors