Agent Error Handling: How Agents Recover From Tool and LLM Failures

Table of Contents
ELI5
Agent error handling is the set of detection, retry, and recovery patterns that keep an autonomous LLM loop from collapsing when a tool returns garbage, the model emits invalid JSON, or a single bad step poisons everything downstream.
Watch a production agent fail and you will notice something strange. It almost never crashes the way a normal service crashes. Instead, it keeps going — confidently, fluently, sometimes for a dozen more steps — while quietly building a tower of conclusions on top of a single corrupted tool response. The trace looks clean. The output looks competent. The answer is wrong.
That is the anomaly worth following. Traditional error handling assumes failures are loud; agentic systems fail softly, and the recovery problem becomes interesting precisely because of that.
The Discipline Behind Catching Agent Failures Before They Cascade
Classical software treats an error as an exception object that bubbles up to a try/except block. Agentic software cannot rely on that model alone, because the most expensive failures are not exceptions at all — they are valid-looking outputs from a probabilistic system that has drifted off-course. So the discipline is broader than retries and timeouts. It is the design of an entire loop that can notice it is wrong, decide what to do about it, and keep enough state to recover without starting from scratch.
What is agent error handling and recovery?
Agent error handling and recovery is the layered set of mechanisms that detect, contain, and reverse failures across an autonomous LLM-driven workflow — covering tool exceptions, malformed model outputs, semantically wrong (but syntactically valid) responses, policy violations, and timeouts. Recovery in this context means more than re-running a step. It means feeding the failure back into the model as new context, switching to an alternative path, rolling state back to a checkpoint, or stopping the loop with a clean, observable error rather than a hallucinated answer.
The shift in framing is important: the agent loop, not the agent step, is the unit of correctness. A single tool call can succeed or fail. The loop is what has to terminate trustworthy. Guardrails, retries, and checkpoints are the moving parts that produce that property.
A recent qualitative analysis of more than 900 agent traces identified four recurring archetypes of agent failure — premature action without grounding, over-helpfulness under uncertainty, susceptibility to context pollution, and fragile execution under cognitive load such as malformed tool calls and inconsistent recovery (arXiv 2512.07497). Each archetype demands a different recovery primitive. Treating them as one undifferentiated bucket of “errors” is the first mistake most teams make.
Where Failures Enter the Loop and How Recovery Closes It
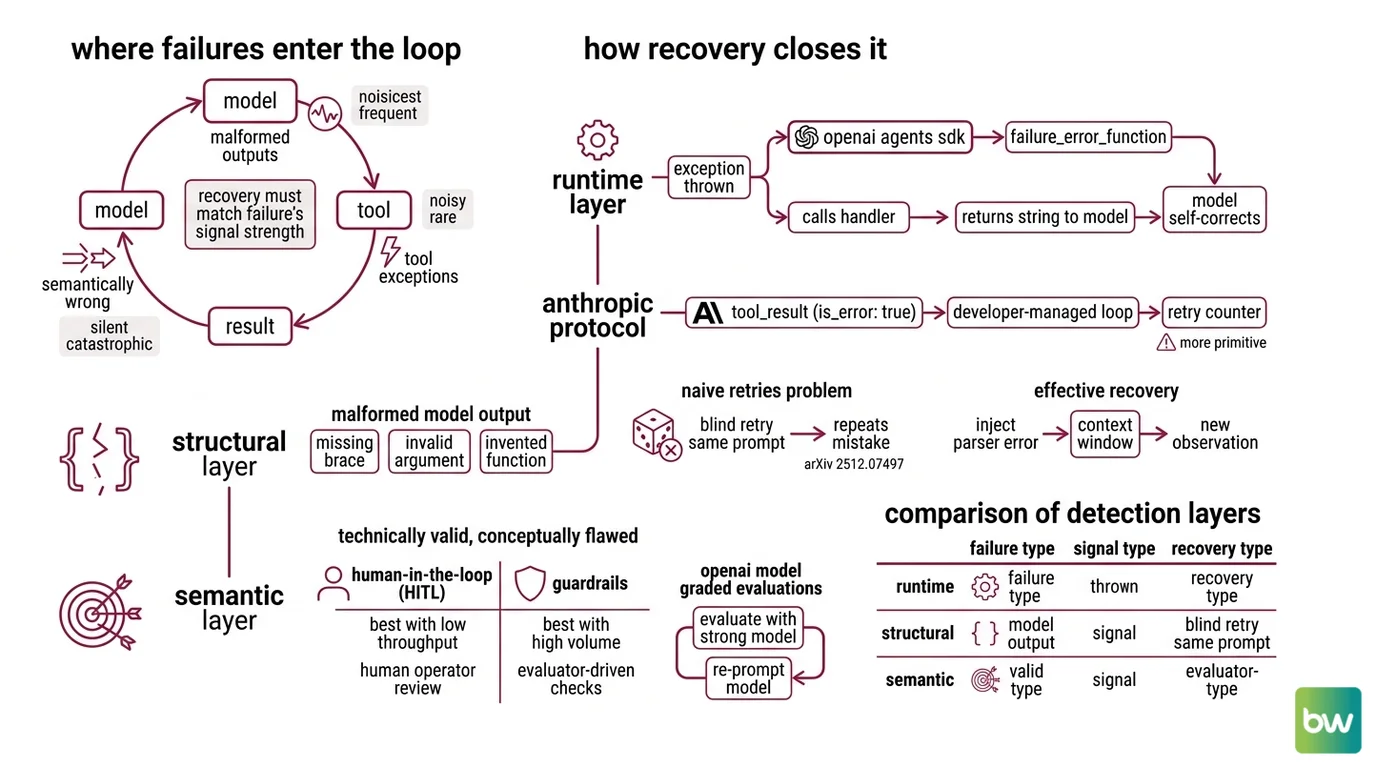
An agent loop is just a feedback system: model → tool → result → model. Failures can be injected at any of those edges, and each entry point has its own physics. Tool exceptions are noisy and rare. Malformed outputs are noisier and more frequent. Semantically wrong outputs are silent and catastrophic. The recovery mechanism must match the failure’s signal strength, not its severity.
How do AI agents detect and recover from tool failures and malformed LLM outputs?
Detection happens at three layers, in this order: the runtime, the structural validator, and the semantic guardrail.
At the runtime layer, the agent SDK catches an exception thrown by the tool function itself — a network error, a 5xx response, a Python ValueError. The OpenAI Agents SDK formalizes this with failure_error_function: when a tool raises, the SDK intercepts the exception and calls this handler, whose return string is then fed back to the model as the tool output, so the LLM can self-correct or pick a different path (OpenAI Agents SDK Docs). Anthropic’s tool-use protocol does something similar but more primitive — the developer returns a tool_result block with is_error: true, and by default only the exception message is passed back to Claude; the agentic loop, including any retry counter, remains the developer’s responsibility (Anthropic Docs).
At the structural layer, the failure is malformed output from the model itself. The LLM emits JSON with a missing brace, an argument that does not exist on the tool schema, or a function name it invented. This is where naive retries hurt more than they help: when the model produces invalid JSON, it often repeats the same mistake or tries arbitrary different escapings rather than truly correcting the structure (arXiv 2512.07497). A blind retry with the same prompt re-rolls the same dice. Effective recovery here injects the parser error back into the context window as a new observation, so the next token distribution is conditioned on the failure rather than blind to it.
At the semantic layer — the most dangerous — the tool returns 200 OK and the payload is nonsense. A search tool hallucinates a citation; an API returns a stale value; a sub-agent answers confidently about a customer who does not exist. Standard error tracking misses this entirely because nothing raised (Fast.io). Catching it requires semantic validators: schemas with business-rule checks, cross-referencing against authoritative sources, or
Agent Guardrails that classify the output before it is committed to memory.
The recovery primitives compose into a small but expressive vocabulary. Retry with backoff handles transient runtime noise. Reflective retry — re-prompting the model with the structured error as new context — handles malformed output. Alternative path selection handles persistent tool failure. Tripwire-and-halt handles policy violations. State rollback to a checkpoint handles cascading semantic failure. The art is matching each primitive to the failure signature, not stacking all of them on every step.
Not a retry. A re-conditioning. Every recovery edits the next-step distribution — and that perspective explains why “just retry the call” so often produces the same wrong answer with a different timestamp.
The Five Layers of an Error-Aware Agent Stack
A useful way to think about the system is as a stack of progressively narrower filters. Each layer catches what the layer below it cannot see. The most reliable agent systems do not optimize any single layer; they make sure no failure mode is invisible to all of them.
What are the main components of an agent error handling system?
Five components show up across nearly every production agent architecture, regardless of vendor:
| Component | Catches | Example primitive |
|---|---|---|
| Input guardrails | Prompt injection, policy-violating user inputs | InputGuardrailTripwireTriggered in OpenAI Agents SDK |
| Tool-call validators | Malformed JSON, hallucinated tool names, bad arguments | Schema validation before dispatch; failure_error_function on raise |
| Retry & timeout policies | Transient network failures, slow nodes | LangGraph RetryPolicy on a node; NodeTimeoutError on time exceedance |
| Output guardrails | Hallucinated answers, leaked PII, semantically wrong results | OutputGuardrailTripwireTriggered; custom semantic validators |
| State checkpointing | Cascading failures, expensive re-runs | LangGraph checkpointer; Temporal-style durable execution |
LangGraph exposes the retry layer as RetryPolicy attached when adding a node — by default it retries any exception except OSError and, for HTTP libraries, only on 5xx responses; when retries are exhausted the failure is final and surfaced clearly (LangChain Reference). Timeouts surface as NodeTimeoutError, a subclass of Python’s built-in TimeoutError, and are only retried if the node’s policy includes that exception type (LangChain Docs). OpenAI’s SDK layers guardrails on top of tool calls with three explicit decisions — allow, reject_content, and raise_exception — the last of which throws ToolGuardrailTripwireTriggered and halts the run (OpenAI Agents SDK Docs).
State checkpointing is the layer most teams underbuild. Long-horizon agent failures rarely die at the failing step; they die in the next three steps that were built on top of it. Recent work on the taxonomy of agent failures shows that a single root-cause failure cascades into successive errors, compounding degradation, and this propagation is a critical bottleneck for long-horizon agents (“Where LLM Agents Fail”, arXiv 2509.25370). Checkpointing — persisting memory and context after major actions so a re-run can resume from the latest known-good state — is what prevents the cascade from consuming the entire trajectory (Temporal Docs).
The recent SHIELDA framework formalizes this view further: an exception classifier feeds a handling-pattern registry, which routes failures to local handling, flow control, or state recovery; the published version covers 36 exception types across 12 agent artifacts (SHIELDA paper, arXiv 2508.07935). Each layer compresses one source of uncertainty — and the loop is only as resilient as the least-covered uncertainty in the stack.
Compatibility notes (LangGraph, as of May 2026):
- Pydantic ValidationError gap (Issue #6027): Node
RetryPolicydoes not retry on PydanticValidationError. Do not rely onRetryPolicyto recover from schema-validation failures — add an explicit reflective retry around the validating node.langgraph-prebuilt1.0.2 breaking change (Issue #6363): Shipped without proper version constraints. Pin the dependency when describing setup to avoid silent breakage.
What the Recovery Stack Predicts About Real Agent Behavior
The mechanism gives the reader something stronger than vocabulary — it gives predictions. Once you see the loop as a sampling process conditioned on prior observations, several common failure patterns stop being mysterious.
- If your agent retries malformed JSON without injecting the parser error into the next prompt, you should observe the same syntactic mistake repeating across attempts — the model has no signal that it was wrong.
- If your tool layer returns
200 OKfor empty or hallucinated payloads, you should observe confident downstream reasoning that compounds across steps — the loop has no negative signal at all. - If you check Agent Evaluation And Testing scores only on final outputs, you should observe high “task complete” rates with low actual correctness — the loop terminated, but in the wrong state.
- If you rely on retries without checkpoints, you should observe long-horizon tasks degrading non-linearly in cost — every recovery re-runs the entire upstream trajectory.
These are not edge cases. They are the default behaviors of an unguarded agent loop, and they explain why teams shipping their first production agent often report that their evals look great while their users complain.
Rule of thumb: match the recovery primitive to the failure signature. Transient and structural failures want retries with new context; semantic failures want validators; cascading failures want checkpoints; policy failures want tripwires that halt the loop.
When it breaks: the most common failure mode of an error-handling stack is layered redundancy without semantic validation — the agent retries cleanly, times out cleanly, checkpoints cleanly, and still emits a confidently wrong answer because nothing in the stack ever asked whether the tool’s 200 OK was actually correct. Resilience without semantic checks is theater.
The Hidden Cost of Over-Helpful Recovery
One subtler consequence of the recovery view: not every failure should be recovered. The same 900-trace analysis flagged “over-helpfulness under uncertainty” as a recurring archetype — agents that fabricate progress rather than escalating to a human (arXiv 2512.07497). A retry policy without an escalation condition encodes a hidden assumption that any answer is better than no answer. For high-stakes workflows, that assumption is the failure mode. Escalation to
Human In The Loop For Agents is itself a recovery primitive; the loop terminates with a clean handoff rather than a confident lie. Anthropic does not document an automatic retry counter for is_error: true tool results — the loop is the developer’s responsibility, including the decision to stop (Anthropic Docs).
The Data Says
Across the recent literature, the recurring finding is that agent failures cascade rather than fault — a single root-cause error propagates into a chain of confident, downstream mistakes (“Where LLM Agents Fail”, arXiv 2509.25370). The implication for builders is uncomfortable but useful: optimizing any single layer (better retries, better prompts, better tools) yields diminishing returns. The compounding factor is coverage of the failure surface, observed continuously through Agent Observability, not the depth of any individual mitigation.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors