Agent Cost Optimization: Routing, Caching, and Token Budgets for LLMs
Table of Contents
ELI5
Agent cost optimization is the practice of routing requests to the cheapest model that can answer them, caching repeated computation, and capping how many loops an agent is allowed to spin before someone reads the invoice.
A reasoning agent loops forty-two times to answer a question that needed three. Each iteration carries the full conversation back through a frontier model, repeats the same retrieval context across hundreds of identical turns, and lets an unbounded while loop graduate quietly into a budget event. Most teams reach for a better prompt. The bill arrived for a structural reason, and the structure sits two layers below the prompt itself.
What the Invoice Is Actually Charging You For
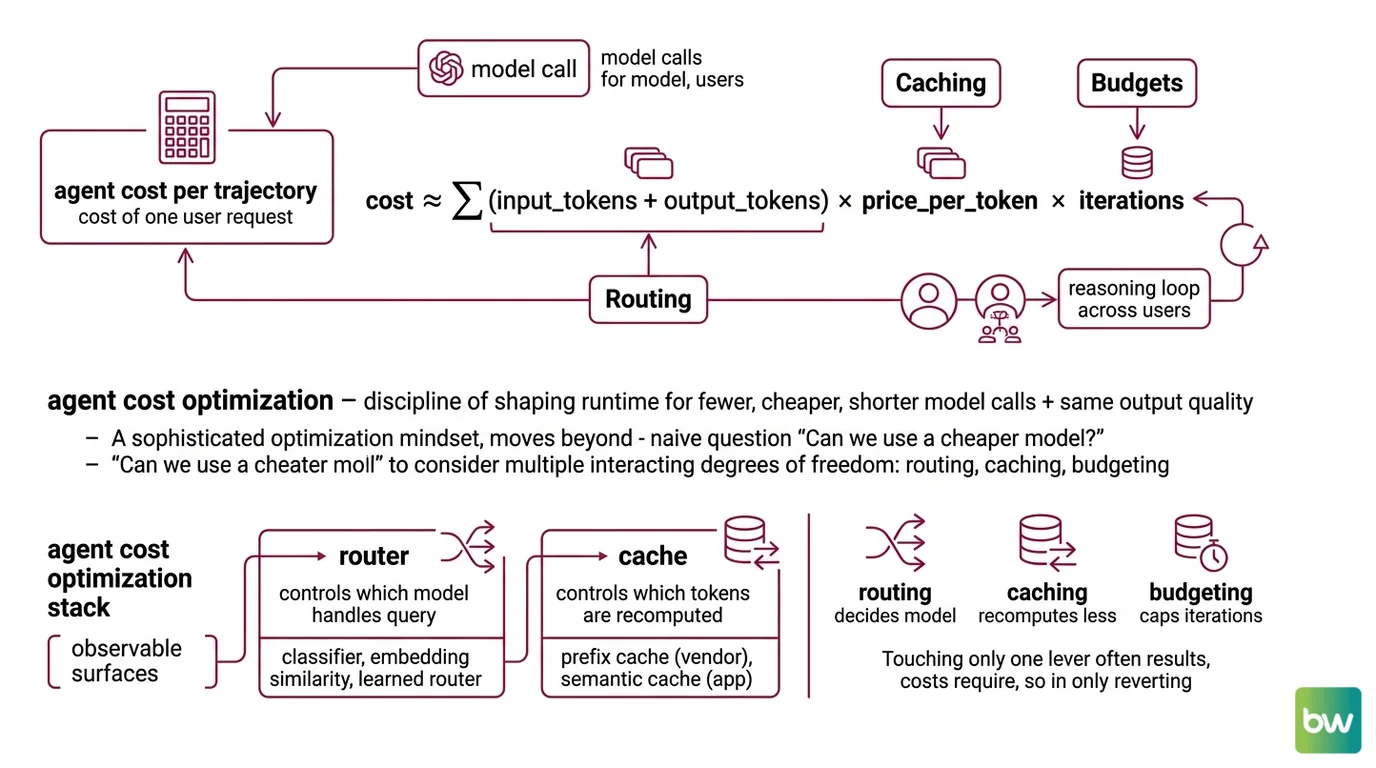
Agent cost is not a per-call problem. It is a per-trajectory problem — the cost of one user request equals the cost of every model call the agent makes inside its reasoning loop, multiplied across users, multiplied by the price per token of whichever model handled each call. Three independent variables; three places the math can drift.
What is agent cost optimization in LLM systems?
Agent cost optimization is the discipline of shaping an agent’s runtime so that fewer, cheaper, and shorter model calls deliver the same quality of output. It treats every token as a probabilistic event whose price is set the moment the agent decides which model to call, how much context to send, and whether it has the authority to call again.
The framing matters. A naive optimization mindset asks: “Can we use a cheaper model?” That question has one degree of freedom. Cost optimization in the LLM-agent setting has at least three, and they interact.
Routing decides which model picks up the request. Caching decides whether the model has to recompute attention over context it already saw. Budgeting decides whether the agent gets to ask again at all. Each lever attacks a different term of the same cost equation:
cost ≈ Σ(input_tokens + output_tokens) × price_per_token × iterations
Routing changes price_per_token. Caching reduces the effective input_tokens the system pays for. Budgets cap iterations. Touching only one of the three almost always reverts inside a week of production traffic.
What are the core components of an agent cost optimization stack?
A working cost stack has four observable surfaces and one invisible one.
| Layer | What it controls | Typical surface |
|---|---|---|
| Router | which model handles which query | classifier, embedding similarity, learned router |
| Cache | which tokens are recomputed | prefix cache (vendor) + semantic cache (app) |
| Budget | when the loop stops | max_iterations, recursion_limit, max_budget_per_session |
| Observer | what each call actually cost | per-trace token + dollar attribution |
| Evaluator | whether savings degraded quality | regression suite on a held-out set |
The observer and evaluator are the parts teams underbuild. Agent Observability attributes spend to a specific trace, tool call, or user; Agent Evaluation And Testing confirms that a cheaper routing decision did not silently break the task. Without those two, every routing change is a bet without a scoreboard.
Notice that none of these layers is a prompt. The prompt is the payload; the stack is the runtime that decides what to do with it.
Three Levers Stacked on a Single Probability Distribution
The structural insight is that all three levers operate on the same object — the conditional probability distribution the model samples from when it generates the next token. They just attack it from different sides.
How does agent cost optimization work across routing, caching, and token reduction?
Routing changes which distribution gets sampled in the first place.
Not every request requires a frontier model. A query that maps cleanly to training-data patterns can be served by a smaller model whose probability distribution is more than adequate for the task; only the hard tail of queries truly needs the strongest available model. The 2024 RouteLLM paper formalised this trade-off and published the numbers most teams now quote: on the MT Bench benchmark, a learned router cut cost by more than 85% versus a GPT-4-only baseline while retaining roughly 95% of GPT-4 quality (RouteLLM paper). The same router reduced cost by about 45% on MMLU and about 35% on GSM8K — a useful reminder that routing gains depend heavily on benchmark composition. Production gains will track the mix of easy and hard queries the system actually sees, not the benchmark.
Two design choices decide whether routing helps in practice. First, the router itself has a cost — embedding the query, scoring it, deciding. If the average query is cheap, the router’s overhead can eat the savings. Second, mis-routing is a quality regression that does not announce itself; without an evaluation harness running on the production distribution, the team discovers the regression through user complaints.
Caching reduces the input the system pays to recompute.
There are two cache families, and they behave differently. Prefix caching is implemented inside the model API: the vendor stores the key-value activations for a prompt prefix already sent, then serves the next request that starts with the same prefix at a discount. As of May 2026, Anthropic charges 0.1× the base input price on a cache read — a 90% discount — and 1.25× the base price to write a 5-minute cache entry, 2× for a 1-hour entry, with a minimum cacheable prefix of 1,024–4,096 tokens depending on the model and a ceiling of four cache breakpoints per request (Anthropic Docs). OpenAI applies a 50% automatic discount on cached input tokens once a prompt clears the 1,024-token threshold, with time-to-first-token improvements of up to 80% on long prompts (OpenAI Docs).
Prefix caching only works when the prefix is bitwise identical. That is why agent system prompts, retrieval context, and tool schemas — anything stable across turns — belong at the front of the message list, and anything per-turn belongs at the back. Reorder once and the cache evaporates.
Semantic caching is the other family. Instead of matching tokens exactly, a semantic cache embeds the request and serves a stored response when the new query is sufficiently close in vector space. Measured on real workloads, semantic caching has reduced API calls by up to 68.8%, with hit rates between 61.6% and 68.8% across query categories (GPT Semantic Cache paper) — workload-specific numbers, not universal. Workload diversity matters: a Redis analysis found that roughly 31% of LLM queries in their production data exhibited enough semantic similarity to be candidates for reuse (Redis Blog). The rest are unique enough that caching offers no upside.
Semantic caching trades exactness for breadth. That trade has a failure mode: two semantically similar queries can have meaningfully different correct answers, and the cache cannot tell. Agent Guardrails on cache-hit responses — confidence thresholds, downstream validators — is what separates a working semantic cache from a silent answer-substitution bug.
Budgets stop the iteration count from drifting.
An agent loop is, mechanically, a while loop wrapped around a model call. Without a cap, the only thing keeping it bounded is the model’s own decision to emit a stop token. Two things break that assumption: a tool error that loops the agent through a retry, and a planning step that decides one more step would help. Production stacks bound both. LangGraph’s recursion_limit defaults to 25 graph steps and raises a GraphRecursionError when exceeded (LangChain Docs); the equivalent FinOps surface in agent frameworks like LiteLLM exposes a max_iterations setting alongside a max_budget_per_session dollar cap, both enforced before the next model call dispatches (LiteLLM Docs).
The budget layer is also where Human In The Loop For Agents fits. When an agent hits its iteration or dollar ceiling, escalation to a human is cheaper than letting the loop continue gambling. Agent Error Handling And Recovery sits next to it: a clean failure that returns control beats a silent retry that doubles the bill.
Not pricing. Architecture.
What the Stack Predicts in Production
The structure makes predictions. Knowing one of the three levers is enough to guess the failure mode of a team that skipped it.
- If routing is implemented without observability, expect quality regressions that nobody can attribute to a specific change.
- If prefix caching is implemented without prompt discipline, expect a cache hit rate that drifts toward zero as ordering changes accumulate.
- If semantic caching is implemented without guardrails, expect a small fraction of confidently wrong answers that the team only finds through user reports.
- If iteration budgets are tightened without evaluation, expect a quiet drop in task completion that shows up first in the hardest test cases.
These are not independent failure modes. They share a root: a savings change moved through the system without a measurement loop attached.
Rule of thumb: Add the observer and evaluator before adding the router. A quantity that is not measured per-trace cannot be optimised, and savings cannot be trusted until a regression suite says quality survived.
When it breaks: The most common failure of an agent cost stack is not a wrong setting — it is divergent state. The cache contents, the router’s training distribution, and the budget thresholds drift independently from the model versions they were tuned against, and a vendor model update silently shifts which queries are “easy” enough to route to the cheap tier. Without a scheduled re-tuning cadence, the stack converges quietly toward either over-spending (defensive routing) or under-quality (stale routing).
The Data Says
The defensible numbers — Anthropic’s 0.1× cache reads, OpenAI’s 50% cached-input discount, RouteLLM’s >85% MT Bench reduction at roughly 95% quality, semantic caching’s up to 68.8% API-call reduction in the GPTCache study — agree on a single shape. Most agent token spend is recomputation of context the system already has, asked of a model that is stronger than the query needs, inside a loop that did not need to spin that many times. The stack works because each lever attacks a different one of those three sources, and observability decides whether the savings stick.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors