What Is Active Learning and How Models Pick the Most Informative Samples to Label

ELI5
Active learning lets a model choose which examples it learns from. Instead of labeling everything, you label only the samples the model finds most confusing — reaching the same accuracy with a fraction of the human effort.
Train a text classifier on every labeled document you can afford, and you reach a certain accuracy. Train it on a carefully chosen few hundred instead of tens of thousands, and you can land in nearly the same place. The labels you skipped did not contain missing information; they were redundant. Most of a training set, it turns out, confirms what the model already believes.
That observation breaks a mental model almost everyone carries into machine learning: that more labeled data is always better, and that the path to a stronger model runs through a bigger annotation budget. The relationship is real, but it is not linear. Examples are not equally informative. A few sit on the knife’s edge of the model’s uncertainty and reshape its decision boundary; the rest fall comfortably inside territory the model has already mapped. Active learning is the discipline of telling those two groups apart — and only paying to label the first.
The Asymmetry Hidden in Every Unlabeled Pool
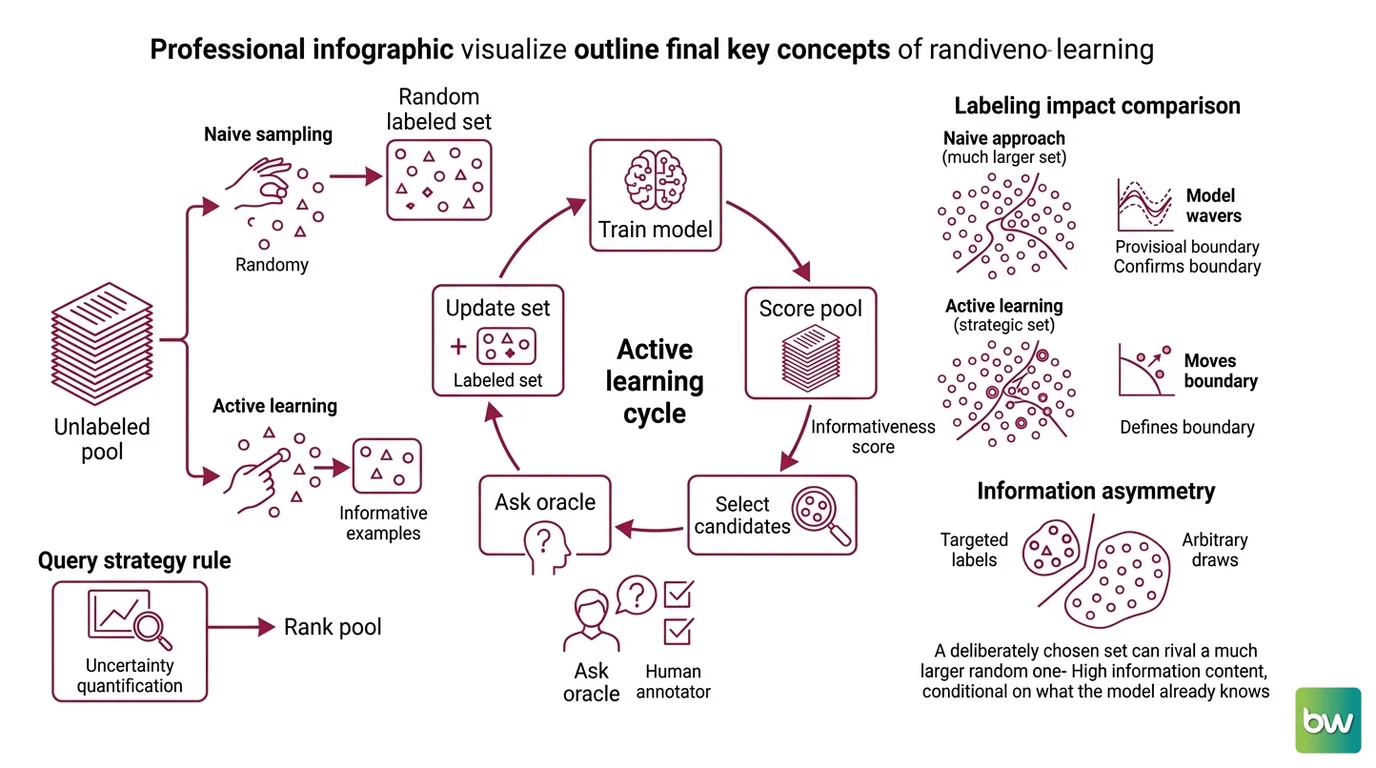
Start with where the information actually lives. In a typical supervised setup, you have a large pile of unlabeled examples and a budget that covers labeling only a slice of it. The naive move is to sample that slice at random. Active learning makes a different bet: that the model itself knows where its own ignorance lies, and can point you toward the examples worth a human’s time.
What is active learning in machine learning?
Active learning is a machine learning paradigm in which the model reaches a target accuracy using far fewer labeled examples by querying the most informative unlabeled samples and asking an oracle — usually a human annotator — to label just those, a framing laid out in Settles’ Active Learning Literature Survey. The loop is iterative: train on a small labeled set, score the unlabeled pool for informativeness, send the top candidates to the oracle, fold the new labels back in, and repeat.
The word that does the heavy lifting is informative. A model partway through training holds a provisional decision boundary — its current best guess at where one class ends and another begins. Examples far from that boundary are easy; the model is confident and almost certainly right, so a label confirms nothing. Examples near the boundary are where the model wavers, and a label there can move the boundary itself. The Query Strategy is the rule that quantifies this and ranks the pool accordingly.
This is why the Training Data Quality of a small, deliberately chosen set can rival that of a much larger random one. The information content of a label is conditional on what the model already knows — and a strategically selected example carries far more of it than an arbitrary draw. Most labels confirm the boundary; a few define it.
How does active learning reduce labeling costs by querying only useful samples?
The cost reduction follows directly from the asymmetry. If informativeness is concentrated in a small fraction of the pool, then spending Data Labeling And Annotation effort uniformly across all examples wastes most of the budget on redundancy. Querying only the useful samples redirects that spend toward the labels that actually change the model.
The historical anchor for this claim is sharp. On a newswire text-categorization task, uncertainty sampling cut the amount of manually labeled training data needed to reach a given accuracy by as much as 500-fold compared to random selection, a result reported by Lewis and Gale in 1994. That figure belongs to that specific experiment — it is not a universal guarantee, and the gain you see depends heavily on the task, the data distribution, and the model class. But the mechanism it demonstrates generalizes: when redundancy dominates a pool, skipping it is where the savings live.
There is a feedback structure here worth naming. Because each batch of new labels is chosen after the previous batch has been folded in, the model’s notion of “informative” updates as it learns. Early queries probe the coarse shape of the problem; later queries refine the fine print near the boundary. The process is closer to a Human In The Loop dialogue than to a one-shot data dump — the model asks sharper questions as its understanding sharpens.
The Three Ways a Model Can Ask
Not every active learning setup gives the model the same kind of access to data. The survey literature distinguishes three query scenarios, and the differences are not cosmetic — they determine what kinds of questions the model is even allowed to pose.
The first is membership query synthesis, where the model generates its own example to be labeled rather than picking one from existing data. Powerful in principle, it can produce inputs that are meaningless to a human oracle — a synthesized “document” that is not really a document. The second is stream-based selective sampling, where unlabeled examples arrive one at a time and the model decides, for each, whether to query it or discard it. The third, and by far the most common in practice, is Pool Based Sampling: a small labeled pool, a large static unlabeled pool, a hypothesis set, and an oracle, with the model scoring the entire pool and selecting the best candidates each round. These three scenarios are catalogued in Settles’ survey, and most real annotation projects live in the pool-based world because that is where the data actually sits.
What are the main query strategies used in active learning?
Within the pool-based setting, the open question is how to score informativeness. Several families of query strategy have been developed, and they disagree about what “informative” should mean.
| Strategy family | Core idea | Origin |
|---|---|---|
| Uncertainty sampling | Query the instances the current model is least certain about | Lewis & Gale 1994 |
| Query-by-committee | Train several models, query where they most disagree | Seung et al. 1992 |
| Expected model change | Query the instance that would most change the model if labeled | Settles survey |
| Expected error reduction | Query to minimize the model’s expected future error | Settles survey |
| Density-weighted / diversity | Favor instances representative of dense regions, not just uncertain outliers | Settles survey |
The most widely used family is uncertainty sampling, introduced by Lewis and Gale in 1994. It queries the instances the current model is least confident about, and it comes in several flavors: least-confidence (the example whose top prediction is weakest), margin sampling (the smallest gap between the top two predicted classes), and entropy-based sampling (the most spread-out probability distribution across all classes). Each formalizes “the model is unsure” slightly differently, and entropy generalizes most cleanly to many-class problems.
A different intuition drives Query By Committee, introduced by Seung, Opper, and Sompolinsky in 1992. Instead of asking one model how unsure it is, you train a committee of models on the same labeled data and query the example on which they most disagree. Disagreement among equally valid hypotheses marks the regions of the input space where more data would actually resolve something — a complementary signal to raw uncertainty.
Uncertainty sampling, despite being the oldest of these, has aged well. On modern tabular benchmarks it remains a strong, simple, and efficient baseline for most pool-based problems, a finding affirmed by recent expanded-benchmark work. The more elaborate strategies — expected model change, expected error reduction — can win on specific problems, but they pay for it in compute, since each often requires simulating the effect of a candidate label before committing to it.
What the Asymmetry Predicts
Once you see informativeness as concentrated rather than uniform, several practical consequences follow. They turn the mechanism from a description into a set of expectations you can test against your own pipeline.
- If your unlabeled pool is highly redundant — many near-duplicate examples — expect active learning to deliver its largest savings, because random sampling wastes most of its budget on copies. (Running Data Deduplication first sharpens the gain.)
- If you query purely by uncertainty, expect the model to sometimes chase outliers — strange, unrepresentative examples it is unsure about for the wrong reasons. Diversity Sampling and density weighting exist precisely to counter this, pulling queries back toward regions that represent the bulk of the data.
- If you start from an empty or tiny labeled set, expect the first few rounds to be unreliable: the model’s sense of “informative” is only as good as its current boundary, and early on that boundary is barely formed. This is the Cold Start Problem, and it is why active learning usually begins with a small random seed set before the querying loop takes over.
The same logic now extends well beyond classical classifiers. Modal Active Learning applies these query strategies to multimodal and large-model data curation, where the unlabeled pool is enormous and labeling is expensive — exactly the conditions under which selecting the informative slice pays off most. It also composes with other data-centric techniques: Data Augmentation multiplies the value of each hard-won label by generating variants of it.
Rule of thumb: reach for active learning when unlabeled data is cheap and abundant but labeling it is the binding constraint — that is the regime where querying beats random sampling.
When it breaks: active learning does not always outperform random sampling. On some datasets and model classes it underperforms, because the query strategy introduces sampling bias — the labeled set drifts toward the model’s current blind spots and stops representing the true data distribution, which can mislead training rather than sharpen it. Combined with the cold-start problem, this means a poorly seeded or naively uncertain loop can quietly do worse than the boring baseline it was meant to beat.
The Data Says
Active learning works because the information in a label is conditional, not absolute — a few examples near the decision boundary reshape the model while the rest merely confirm it. Identify and label only that informative minority, and you can approach full-dataset accuracy at a fraction of the annotation cost. The savings are real but conditional: they depend on the task, the redundancy of the pool, and a query strategy that avoids chasing its own blind spots.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors