What Is a Vision Transformer and How Image Patches Replaced Convolutions in Computer Vision
ELI5
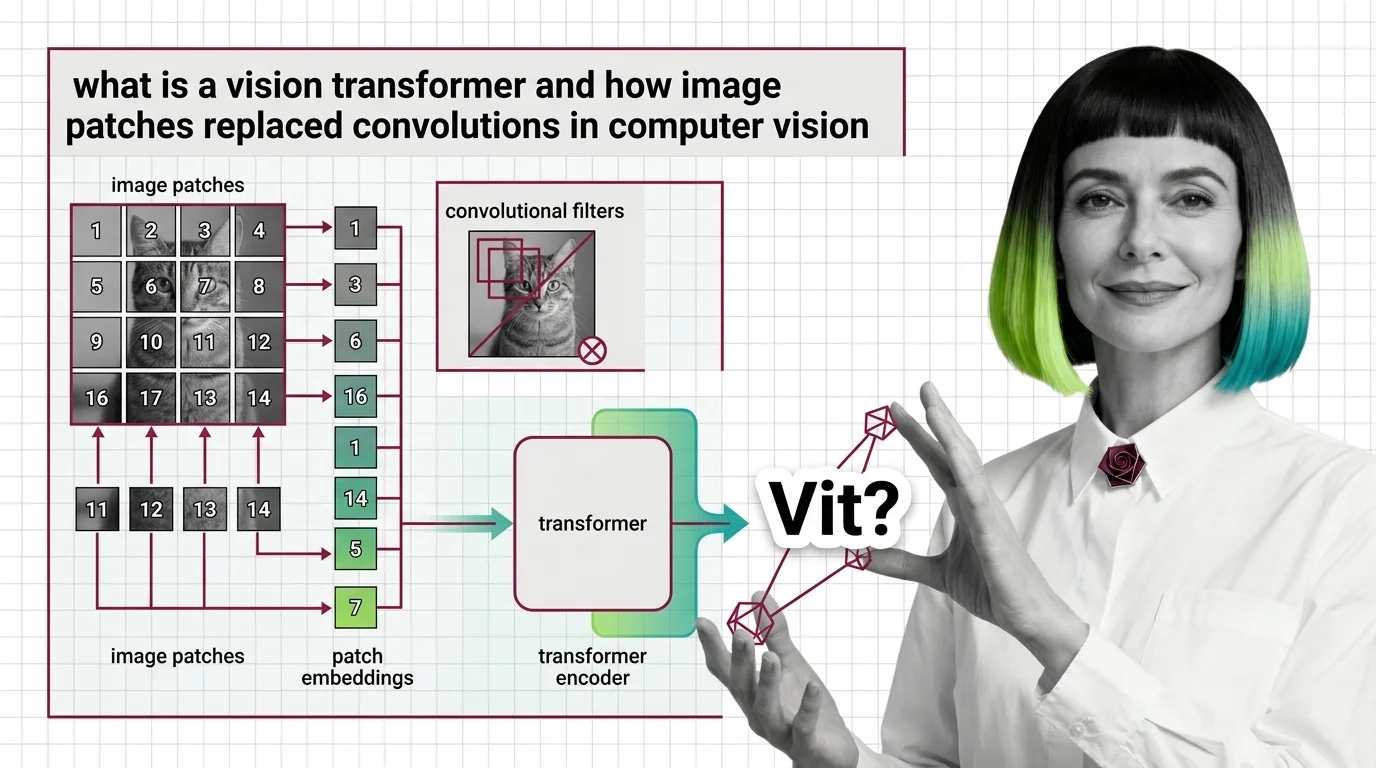
A Vision Transformer cuts an image into small square patches, treats each patch as a word, and feeds the sequence into the same Transformer architecture that reads sentences — letting attention replace convolution as the mechanism for seeing.
For a decade, every production image model rested on the same assumption — that seeing requires sliding a small filter across a pixel grid, stacking the outputs into a hierarchy of features, and trusting that nearby pixels carry related meaning. Then in 2020 a team at Google cut the image into 196 little squares, lined them up like a sentence, and ran them through a language-model encoder with no convolutions at all. The result matched the best CNNs on ImageNet. The architectural commitment that had defined computer vision since AlexNet was suddenly optional — and the question worth asking was why the network still worked when you deleted its most treasured assumption.
How 16x16 Patches Turned an Image Into a Sentence
Think of a ViT as a reader that was handed a photograph instead of a paragraph and refused to adapt its reading technique. It splits the image into a grid of non-overlapping squares, looks at each square as if it were a word, and asks the same question it asks of text tokens: which other squares should I pay attention to right now?
That transposition — from spatial grid to ordered sequence — is the entire architectural move. Everything else is standard Transformer encoder machinery.
What is a Vision Transformer (ViT)?
A Vision Transformer is an image encoder that applies the Transformer architecture directly to sequences of image patches, without convolutions. The foundational paper, “An Image is Worth 16x16 Words,” introduced the design in late 2020 and established that a pure Transformer could match or exceed state-of-the-art CNNs on ImageNet, CIFAR-100, and the VTAB benchmark suite — provided it was pre-trained on enough data (Dosovitskiy et al.).
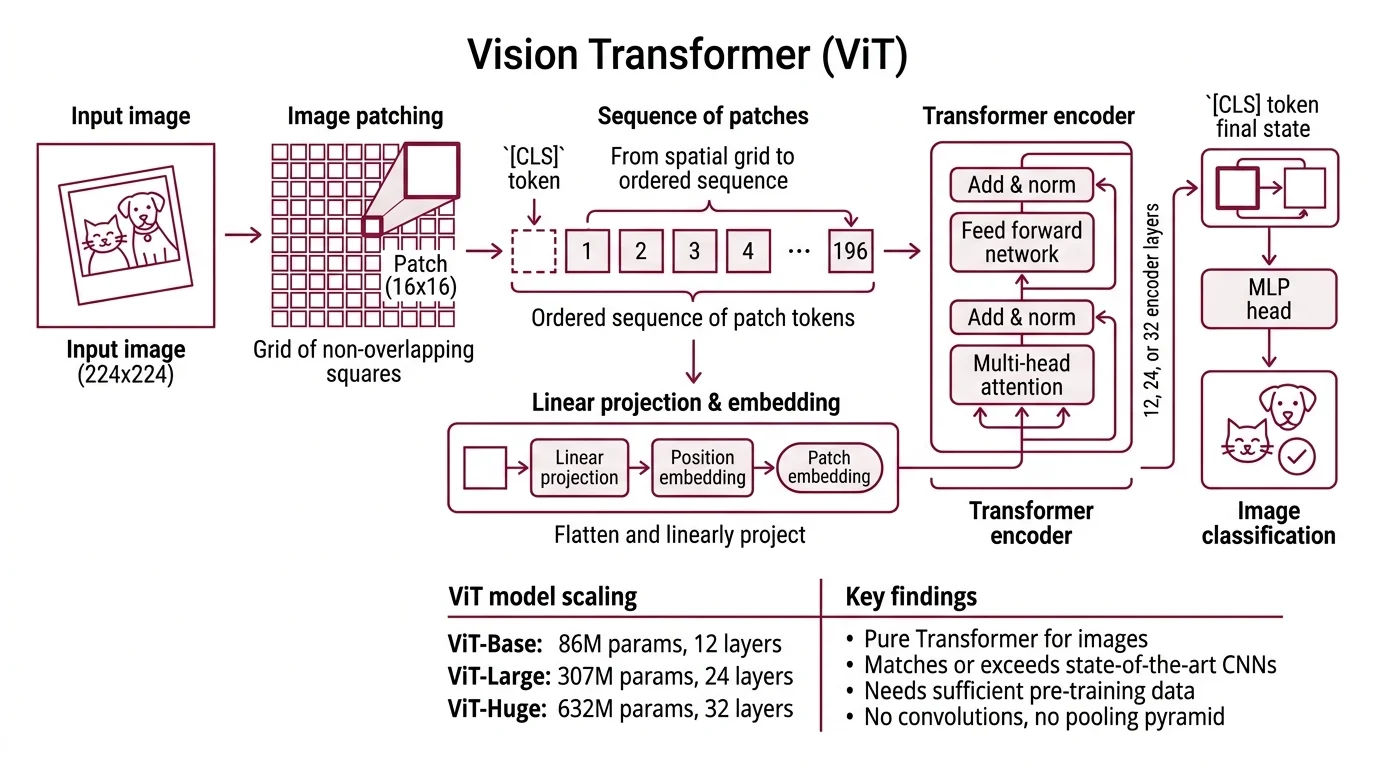
The name is almost literal. For a 224x224 input image with 16x16 patches, the model produces a 14x14 grid of non-overlapping squares — 196 patch tokens in total, to which an extra learnable [CLS] token is prepended, whose final hidden state serves as the image’s classification representation (Dosovitskiy et al.). Each patch is flattened and passed through a single linear projection to produce its embedding. A learnable 1D absolute position embedding is added, preserving the only spatial information the model will ever see. From that point forward, the architecture no longer knows it is looking at an image.
The canonical sizes follow the same scaling conventions as language transformers: ViT-Base around 86 million parameters across 12 encoder layers, ViT-Large around 307 million across 24 layers, and ViT-Huge around 632 million across 32 layers (Dosovitskiy et al.). There is no pooling pyramid, no receptive field that grows with depth, no hard-coded sense of locality. Just a stack of self-attention blocks, end to end.
How does a Vision Transformer process an image end to end?
The pipeline has five stages, and each one is a single function you could describe in a paragraph.
The image is divided into a grid of fixed-size patches — typically 16x16 pixels for a 224x224 input. Each patch is flattened into a vector of raw pixel values, then projected through a learnable linear layer into a fixed-dimensional embedding. This projection is mathematically equivalent to a convolution with the patch size as both kernel and stride, which is why some implementations compute it with a single Conv2d call rather than reshape-and-matmul. A special [CLS] token embedding is prepended to the sequence, and the aggregated 197-token input is ready for the encoder.
Position embeddings are added element-wise. These embeddings are 1D learnable parameters in standard ViT, not 2D and not sinusoidal — the model learns where each patch sits in the 14x14 grid as an abstract index, not as a coordinate (Dosovitskiy et al.). This is the only signal about spatial arrangement the Transformer will ever receive.
The resulting sequence passes through L identical Transformer encoder blocks. Each block applies layer normalization, multi-head self-attention across all 197 tokens, a residual connection, another layer norm, and a feed-forward MLP. After the final block, the hidden state of the [CLS] token is routed to a classification head; the patch token outputs are used for dense-prediction tasks like segmentation or detection.
Note what is missing from this list. No pooling. No receptive-field expansion. No explicit locality assumption. The network has no structural reason to believe that pixels in patch 42 are related to pixels in patch 43 rather than patch 157 — it has to discover neighborhood from data.
Why Self-Attention Needs No Locality
The move from convolution to attention is not a minor substitution. It is a trade — a weaker architectural prior in exchange for a more flexible computational mechanism. Understanding what ViT gave up is the only way to understand what it gained.
How is a Vision Transformer different from a CNN?
Convolutional networks encode two structural commitments directly in their architecture: locality — a pixel’s meaning depends on its neighbors — and translation equivariance — a cat shifted ten pixels right is still a cat. These are examples of Inductive Bias: assumptions baked into the model that shrink the space of functions it can learn, so less data is needed to find a good one.
ViT discards both. There is no sliding kernel that enforces locality, and position embeddings are learned per index rather than shared across translations. The consequence is precise and was documented in the original paper: a pure ViT trained only on ImageNet-1K underperforms a comparable CNN, because without the CNN’s priors the model has to learn locality from scratch (Dosovitskiy et al.). Pre-train the same architecture on a much larger dataset — the original paper used JFT-300M — and it matches or beats the CNN at a fraction of the compute. The CNN’s inductive bias is a subsidy the network collects when data is scarce. ViT declines the subsidy and pays full price, which is only rational if the data budget is large.
Two consequences follow.
The early layers of a ViT can, in principle, attend globally. A CNN at layer one only sees a 3x3 or 7x7 window; a ViT at layer one sees the entire image. This is why ViT features often look more semantically coherent in deep probes — the architecture does not force a local-first decomposition.
The cost is quadratic. Standard global self-attention computes an N-by-N attention matrix across all patch tokens, so compute scales as O(N^2) in the number of patches (Liu et al. (Swin)). Doubling the image resolution quadruples the patch count, which sixteenfolds the attention cost. That scaling wall is what drove the next wave of architectures.
How does self-attention work on image patches instead of words?
Mechanically, the operation is identical to self-attention over text tokens. The model projects each patch embedding into three vectors — query, key, and value — and computes, for every pair of patches i and j, an attention weight proportional to the dot product of patch i’s query with patch j’s key. Those weights are normalized across j with a softmax, and each patch’s output is the weighted sum of all patches’ value vectors.
What changes is the interpretation, not the math. In language, the attention weight from the word “bank” to the word “river” reflects a learned semantic dependency. In vision, the attention weight from a patch of sky to a patch of cloud reflects a learned spatial dependency — one the model was never told to look for. Multi-head attention lets different heads specialize: visualization studies of trained ViTs show that some heads attend locally at early layers, behaving like convolutions, while other heads attend globally from layer one, which a CNN architecturally cannot do (Dosovitskiy et al.).
The softmax normalization matters. Attention weights sum to one across the sequence, so every patch’s representation is a convex combination of all other patches’ values. Information can flow from any patch to any other in a single layer — a property that convolutional networks only achieve after a stack of downsampling operations has shrunk the spatial grid enough for the receptive field to cover it.
Not a better feature detector. A different contract about where information can travel.
What the Absence of Inductive Bias Predicts
Once you accept that ViT trades architectural priors for raw capacity, a set of practical predictions falls out of the geometry. Each one maps a design choice to an expected failure mode.
- If you train a pure ViT on a mid-sized dataset without heavy augmentation, expect it to lose to a well-tuned CNN. The inductive-bias deficit shows up as poor sample efficiency.
- If you double the image resolution while keeping patch size fixed, expect the attention cost to grow roughly as the fourth power of the linear resolution. Variants that restrict attention to local windows — most prominently the Swin Transformer, which uses shifted local-window attention and achieves linear complexity in image size along with 87.3% top-1 on ImageNet-1K and 58.7 box AP on COCO — exist specifically to break this wall (Liu et al. (Swin)).
- If you want ViT-level performance without hundreds of millions of labeled images, reach for Self Supervised Learning. A Masked Autoencoder masks roughly 75% of the patches, lets the encoder see only the visible ones, and trains a lightweight decoder to reconstruct the missing pixels; the ViT-Huge variant reaches 87.8% top-1 on ImageNet-1K using only ImageNet data, no extra labels (He et al. (MAE)).
- If you need frozen features that transfer to segmentation, depth estimation, or retrieval without fine-tuning, current practice reaches for self-supervised ViTs in the DINOv2 line, trained on 142 million curated images to produce general-purpose representations (DINOv2 Paper).
Rule of thumb: Use a CNN when data is limited and inference latency matters more than transferability. Use a ViT when pre-training scale is available and the downstream task needs representations that can be repurposed. The choice is less about accuracy and more about what kind of prior you want the network to start with.
When it breaks: ViTs fail loudly when trained from scratch on small datasets — they need either a lot of data or heavy regularization to outperform CNNs at matched parameter budgets. Global self-attention also scales quadratically in token count, so high-resolution images, dense prediction tasks, and long video clips all hit a compute wall that pure ViT cannot climb without architectural modifications.
The Encoders Quietly Powering Every Multimodal Model
The most consequential thing about ViT is not that it beat CNNs on ImageNet. It is that it gave vision a tokenizer the rest of the AI stack could plug into. When an image is a sequence of embeddings, it composes cleanly with text embeddings, audio embeddings, and learned modality tokens. Every major multimodal model released since 2023 — flagships from OpenAI, Anthropic, and Google — relies on a ViT-style encoder somewhere in its image pipeline, even when the public architecture details are thin.
The current field of vision-language encoders splits cleanly. As of April 2026, SigLIP 2 from Google DeepMind leads adoption with a family spanning ViT-B (about 86M params), L (about 303M), So400m (about 400M), and g (about 1B), a naflex dynamic-resolution variant, coverage across 109 languages, and Apache 2.0 weights (SigLIP 2 Paper). The original CLIP Model from OpenAI remains the canonical baseline and is still widely deployed, though new multimodal work increasingly defaults to SigLIP 2 for zero-shot classification and dense-prediction metrics. For self-supervised frozen features, DINOv2 remains the workhorse in production pipelines even though Meta has since released DINOv3 as its flagship self-supervised ViT, trained on 1.7B unlabeled images at 7B parameters according to Meta’s announcement (Meta AI Blog).
One more context point matters for architectural decisions. ViT was the event that demonstrated Transformers could replace domain-specific architectures in vision, but the Transformer monoculture it produced is not total. Alternatives now compete at the long-sequence and long-context end — hierarchical local-attention variants, State Space Model designs like Mamba-family models for sequence efficiency, and Mixture Of Experts approaches for parameter efficiency at scale. ViT opened the door. What walks through it next is still being decided.
The Data Says
A Vision Transformer is not a better convolutional network. It is an explicit refusal of two architectural commitments — locality and translation equivariance — in exchange for a uniform sequence-based computation that scales with data rather than with hand-engineered priors. The performance crossover with CNNs is a function of pre-training volume, not of raw capability, and the broader adoption of ViT as the universal image tokenizer is what made current multimodal models composable at all. The patches were not the point. The sequence was.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors