What Is a State Space Model and How Selective SSMs Replace Quadratic Attention
ELI5
A state space model processes a sequence by carrying a compressed hidden state forward, updated token by token. Selective SSMs — Mamba and successors — decide per input what to keep or forget, running in linear time instead of quadratic.
Double a transformer’s context window, and its compute cost quadruples. Double it again, and it quadruples again. By the time frontier labs were chasing million-token context, everyone was staring at the same bill — and the math said the only way out was a different kind of model. The escape hatch didn’t come from a cleverer variant of attention. It came from an idea borrowed from linear systems theory, fitted with enough new mechanics to finally train well at scale.
The Idea Attention Was Competing Against
Before selection mechanisms turned SSMs into transformer rivals, the architecture had been sitting in signal processing textbooks for decades. To see why it now works in a language model, you have to see what it is at the level of the recurrence — and why that shape is fundamentally different from attention.
What is a state space model in AI?
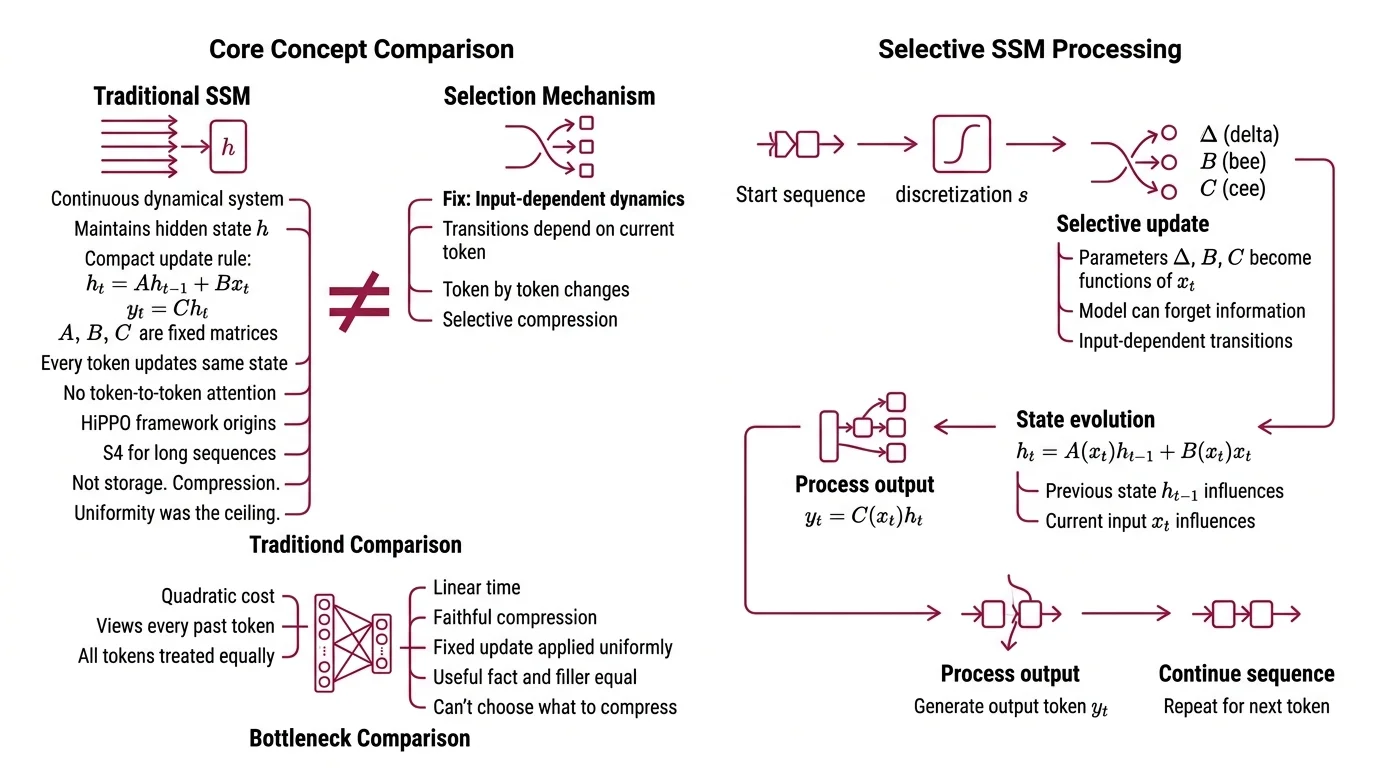
A state space model represents a sequence as a continuous dynamical system discretized onto tokens. Instead of computing pairwise interactions between every token and every other token, it maintains a hidden state h that evolves step by step. The update rule is compact:
h_t = A h_{t-1} + B x_t, and y_t = C h_t.
The matrices A, B, and C govern how the past compresses into the present and how the present projects to the output. Every token updates the same hidden state — no token-to-token attention required.
The formulation isn’t new. It was introduced to deep learning by the HiPPO framework and then made trainable at scale by S4, whose structured-plus-low-rank parameterization of A kept very long sequences computationally tractable (S4 paper).
Not storage. Compression.
The bottleneck in the original S4 line was different from attention’s. Attention can see every past token, at quadratic cost. SSMs could run in linear time, but every token updated the hidden state the same way. They compressed information faithfully — they just couldn’t choose what to compress. A useful fact and a filler token went through the same A, the same B. That uniformity was the ceiling.
When the Input Steers Its Own Dynamics
The fix was simple in retrospect. Make the model’s dynamics depend on what it’s reading. Not fixed transitions applied uniformly — input-dependent transitions, token by token.
How does a selective state space model process sequences in linear time?
In a selective SSM, the parameters that govern how the hidden state evolves — Δ (the discretization step), B (the input projection), and C (the output projection) — become functions of the current input instead of fixed weights, per Gu & Dao (Mamba paper). The model reads each token, computes what portion of that token to let into the state, and modulates how quickly older information fades. The effect is a per-token forget gate and a per-token input gate, baked directly into the recurrence.
That alone wouldn’t be fast. Input-dependent dynamics break the convolutional shortcut that made S4 practical to train. The recurrence becomes genuinely sequential — and sequential is the enemy of GPUs.
Mamba’s second trick is a hardware-aware parallel associative scan. Per Gu & Dao (Mamba paper), it fuses parameter loading, discretization, and the recurrence itself into a single kernel that minimizes traffic between HBM and SRAM, and runs an order of magnitude faster than a naïve scan. The recurrence is still sequential in principle; on the hardware, it’s parallelized along the sequence dimension by exploiting the associativity of the update operator.
The analogy that makes this concrete: a transformer is a committee that re-reads every memo on every decision. An SSM without selection is a rolling briefing that updates the same way on every memo, regardless of content. A selective SSM is a briefing where each incoming memo decides, by its own content, whether to update the state strongly, barely, or not at all.
Same linear-time recurrence. Radically different information flow.
Where the Complexity Gap Comes From
Linear versus quadratic isn’t a tuning difference. It comes from the shape of what each architecture stores.
Why does Mamba scale linearly while transformers scale quadratically?
Self-attention computes a similarity between every pair of positions in the sequence. With sequence length n and hidden size d, you pay O(n² d) in time and O(n²) in activation memory during training. Double n, and both quadruple.
An SSM doesn’t store pairwise interactions. It stores a fixed-size hidden state that every token updates in turn. Scaling is linear in sequence length during both training and inference, with inference throughput reported at roughly five times transformer-equivalent models on the original paper’s benchmarks (Gu & Dao, Mamba paper). That headline five-times figure comes from synthetic and long-range evaluations in 2023–24; real-world end-to-end throughput depends on the hybrid ratio, kernel implementation, and whether mixture-of-experts layers are in play. The number is directional, not a blanket guarantee.
The cost of this efficiency is specific. Attention keeps every past token explicitly accessible to every future decision. An SSM keeps a compressed summary. For a fixed hidden size, longer sequences mean more compression pressure on the same state.
Mamba-3, accepted at ICLR 2026, pushes this trade-off further (Mamba-3 paper). A more expressive discretization and complex-valued state updates reach comparable perplexity to Mamba-2 at roughly half the state size. Denser information per unit of memory — same recurrence shape.
| Self-attention | Unselective SSM (S4) | Selective SSM (Mamba) | |
|---|---|---|---|
| Sequence complexity | O(n²) | O(n log n) via FFT | O(n) via parallel scan |
| Per-token dynamics | Uniform, all pairs | Fixed recurrence | Input-dependent recurrence |
| Explicit token access | Yes (attention weights) | No (compressed state) | No (compressed, selected state) |
| Training parallelism | Full | Convolutional | Associative scan |
What the Hybrids Are Telling You
The interesting question is no longer whether SSMs can match transformers. It is which layers of a transformer you can replace without losing the capabilities that attention uniquely provides.
Every production-scale Long Context Modeling model in 2026 is a Hybrid Architecture. Jamba 1.5, from AI21, runs one attention layer for every seven Mamba layers and inserts Mixture Of Experts blocks every two layers. Nemotron-H, from NVIDIA, replaces roughly 92 percent of self-attention layers with Mamba-2 and reports up to 2.9× long-context speedup on the 47B variant versus comparably sized dense transformers (NVIDIA ADLR, Nemotron-H). Falcon H1 uses a different topology entirely: attention heads and SSM heads running in parallel within each block, their outputs concatenated before projection. The pure-recurrent branch — RWKV and its attention-free Linear Attention cousins — keeps the architecture alive at the smaller end of the scale.
Across the zoo, one number keeps recurring. One attention layer per five to seven SSM layers is the de-facto sweet spot (AI21 Blog, Rise of Hybrid LLMs).
If you know the ratio and the state size, you can predict the failure modes:
- If the model is mostly SSM, expect strong long-context fluency and weak 5-shot in-context learning.
- If the model sits inside that hybrid sweet spot, expect the in-context learning gap to mostly close without sacrificing long-context throughput.
- If the sequence is short, the complexity gap shrinks — quadratic attention is cheap when
nis small.
Rule of thumb: For short sequences with heavy few-shot prompting, dense attention still pays off. For very long contexts, hybridize aggressively or pay the quadratic compute bill.
When it breaks: Pure SSMs compress history into a fixed-size hidden state instead of keeping explicit token access. On 5-shot MMLU and copy-recall benchmarks, they lag transformers — and the NeurIPS 2025 “Achilles’ Heel of Mamba” paper shows this is a structural property of the compression, not a tuning issue (arXiv, SSM long-context characterization). Hybrids substantially close the gap. They do not fully eliminate it.
The Data Says
Among the long-context models running in 2026, the frontier architectures keep most of their compute in a selective SSM and reserve a thin attention budget for the tasks where explicit token access is non-negotiable. That isn’t the end of the transformer — it is the end of the transformer-only era. Selection turned state space models from a theoretical curiosity into the default long-context substrate.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors