What Is a Neural Network and How It Learns to Generate Language

Table of Contents
ELI5
A neural network is a chain of simple math functions that adjusts millions of numbers through repeated error correction until its word predictions match real language patterns.
Ask a large language model to finish a sentence, and it will produce something that reads like thought. Coherent grammar, plausible facts, occasionally a turn of phrase that surprises even its developers. The engine behind that output is not a knowledge base, not a search engine wearing a personality, and not a compressed copy of the internet. It is arithmetic — millions of multiply-and-add operations, organized into layers, repeated until the numbers stop being wrong quite so often.
The strange part is not that this works. The strange part is how little each individual piece of the system knows about language.
The Scaffold That Learns to Predict
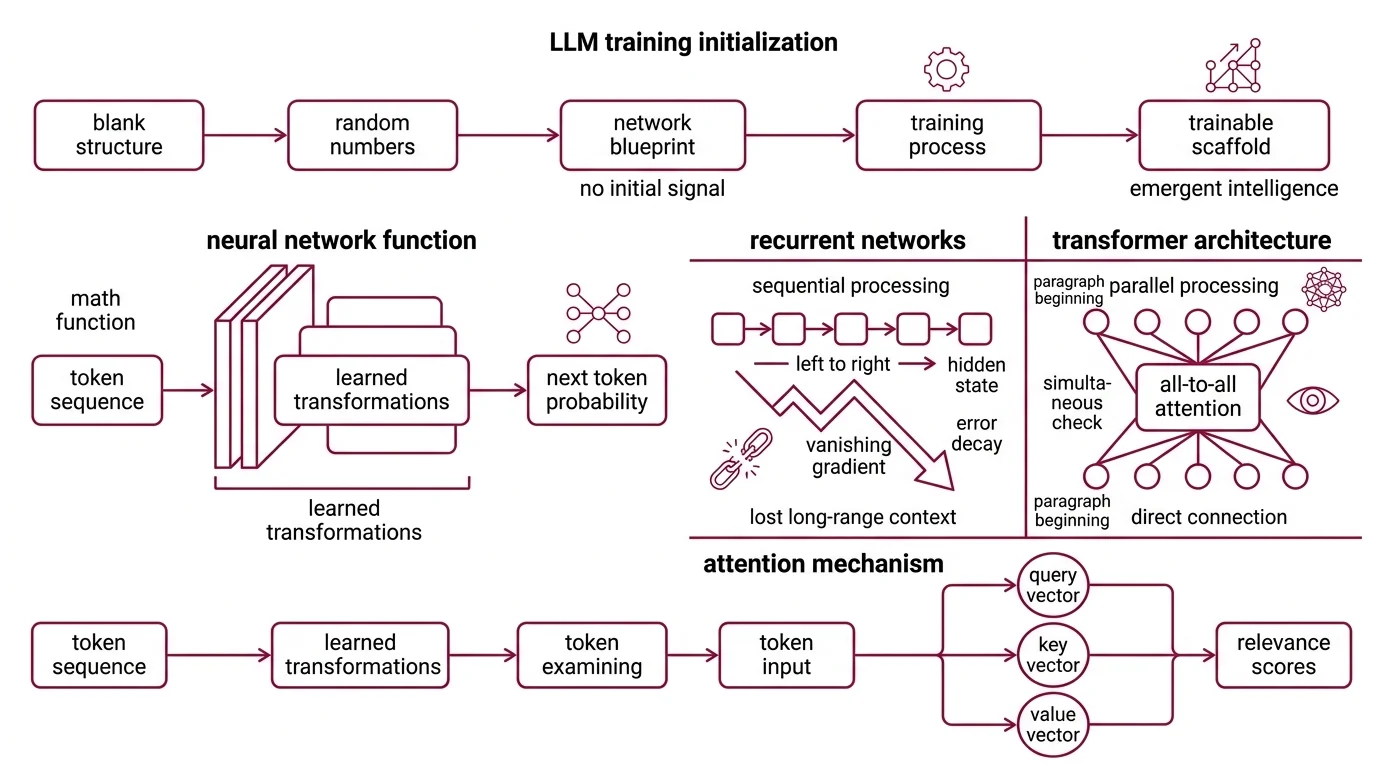
Every neural network starts as a blank structure — numbers assigned at random, connections wired but carrying no signal worth reading. The design of that structure determines what kinds of patterns the network can eventually capture, but at initialization, it is agnostic. Whatever intelligence eventually emerges comes from training, not from the blueprint.
What is a neural network in the context of large language models?
A neural network is a mathematical function that maps an input to an output through a series of learned transformations. In large language models, the input is a sequence of tokens — word fragments encoded as numerical vectors — and the output is a probability distribution over what token should come next.
The architecture that dominates modern LLMs is the transformer, introduced by Vaswani et al. in 2017 (arXiv). That paper, “Attention Is All You Need,” has accumulated over 173,000 citations as of 2025 — a measure less of novelty than of the specific bottleneck it removed.
Before transformers, recurrent neural networks processed text sequentially: one token at a time, left to right, dragging context forward through a compressed hidden state. This worked, until it didn’t. The Vanishing Gradient problem meant that error signals from early tokens decayed exponentially as they traveled backward through layers — by the time the network finished a long paragraph, the beginning had dissolved into numerical noise.
Transformers replaced this serial processing with attention. Instead of reading tokens one by one, attention lets every token in a sequence examine every other token simultaneously, computing relevance scores through learned parameters. The word “it” in sentence twelve can directly attend to “the patient” in sentence one, without that connection having to survive a chain of intermediate compressions.
The mechanism computes three vectors for each token — a query, a key, and a value — through separate weight matrices. The query asks “what am I looking for?”; the key answers “what do I contain?”; the dot product between them produces the attention score. High scores mean high relevance, and the corresponding value vectors flow into the output representation. This is the geometry underneath every large language model: learned similarity comparisons, running in parallel across the entire input.
Not sequence memory. Direct access.
But attention produces relevance weights, not words. The architecture that converts those weights into actual predictions is built from layers, weights, and biases — the structural substrate of every neural network.
What are layers, weights, and biases in a neural network?
Think of a neural network as a series of filters stacked vertically. Raw input enters at the bottom; a prediction exits at the top. Each filter — each layer — receives the output of the layer below, transforms it, and passes the result upward. The transformation is governed by two sets of numbers: weights and biases.
Weights are multipliers. Every connection between neurons in adjacent layers carries a weight that amplifies, dampens, or inverts the signal traveling through it. A weight of 2.3 says “this input feature matters.” A weight of 0.01 says “nearly ignore this.” A weight of −1.7 says “this pushes the output in the opposite direction.” The collective pattern of weights across the entire network encodes everything the model has learned.
Biases are offsets. After multiplying inputs by weights and summing, each neuron adds a bias — a fixed shift that lets the network model patterns that don’t pass through the mathematical origin. Without biases, every learned relationship would be geometrically constrained in ways that exclude most interesting structure in language.
After the weighted sum and bias, the result passes through an Activation Function. This is the nonlinear ingredient — the thing that prevents a hundred stacked layers from collapsing into a single linear equation. Activation functions introduce curves, thresholds, and decision boundaries into the mapping, giving the network the geometric complexity it needs to distinguish “bank” as a financial institution from “bank” as a riverbed.
A modern large language model stacks dozens of transformer layers — each containing attention mechanisms and feed-forward sub-layers — with billions of weights collectively shaping predictions. GPT-5.4 and Gemini 3.1 Pro Preview, among the frontier models as of April 2026, are transformer architectures scaled to dimensions that McCulloch and Pitts, who proposed the first mathematical neuron model in 1943, could not have anticipated.
Scale turns simple arithmetic into emergent behavior.
How Error Becomes Education
A neural network with random weights is a noise generator. Its first attempt at predicting the next token in a sentence is, statistically, no better than rolling dice across a vocabulary of tens of thousands of entries. The distance between that guess and the correct answer — measured precisely, propagated backward through every layer, used to adjust every weight by a calculated fraction — is the entire learning mechanism.
How does a neural network learn to predict the next word in a sentence?
The process has three stages, repeated across the full training corpus.
First, the forward pass. The network reads a sequence of tokens and produces a probability distribution over the entire vocabulary — a list of numbers indicating how likely each candidate next token is. Early in training, this distribution is nearly uniform: every word roughly equally probable, which is another way of saying the network has no opinion.
Next, loss computation. The predicted distribution is compared against the actual next token using Cross Entropy Loss, which quantifies how far the prediction sits from the correct answer. A confident correct prediction gives a loss near zero. A confident wrong prediction gives a large loss — the penalty scales with misplaced certainty.
Then, backpropagation. The loss becomes a teaching signal. Through the chain rule of calculus, the algorithm computes the gradient of the loss with respect to every weight in the network — a number that says “this weight contributed this much to the error, and adjusting it in this direction would reduce it.” Rumelhart, Hinton, and Williams formalized this procedure in 1986 (Nature), giving the field a general-purpose method for training networks with multiple layers.
The gradients feed into an optimizer that decides how much to adjust each weight. The Adam Optimizer, introduced by Kingma and Ba in 2014 (arXiv), adapts the step size per parameter. Parameters with consistently large gradients receive smaller, more cautious updates; parameters with sparse, infrequent gradients receive larger ones. This adaptive behavior is why Adam became the default for training language models — the loss surface of a network with billions of parameters is wildly uneven, and a fixed learning rate either overshoots in some regions or crawls uselessly in others.
Consider the scale of this process: each training step computes a gradient for every parameter in the model — a directional signal derived from potentially thousands of tokens in a single batch. Each individual weight adjustment is microscopic, often on the order of one ten-thousandth of the weight’s current value. But across billions of training steps, these incremental nudges accumulate into a weight configuration that captures the statistical skeleton of an entire language.
The network doesn’t know what a verb is. It has no concept of grammar as a category. But its weights encode statistical regularities that, observed from outside, produce behavior indistinguishable from grammatical competence.
Not comprehension. Compression.
What the Gradient Reveals — and What It Hides
The forward-pass, loss, backpropagation loop is the same whether the network has a thousand parameters or a trillion. The architecture determines capacity — what kinds of patterns the network can represent. The data determines content — what patterns exist to be captured. The learning algorithm itself is invariant to both.
This invariance produces a useful prediction: increase model size, dataset size, and compute proportionally, and prediction quality improves along a power-law curve. The relationship has held empirically across architectures, tasks, and scales. Whether it holds indefinitely remains an open question — the trend is strong, but extrapolation is a bet, not a proof.
A more practical prediction: the data sets the ceiling, not the architecture. No optimizer can extract patterns absent from the training corpus. If your dataset contains contradictory claims — and any large web-scraped corpus does — the network will learn to assign high probability to mutually exclusive statements depending on surrounding context. This is not a bug in the architecture. It is the architecture working correctly on data that contains those contradictions.
This is why training data quality is not a footnote in language model research — it is the central variable. Filter the data and the model’s behavior shifts. Add a domain-specific corpus and competence in that domain improves disproportionately. The weights are downstream of the data; always have been.
If the loss plateaus during training but the model still makes errors relevant to your application, the diagnosis is almost never “add more layers.” It is “examine the data distribution” or “reconsider the evaluation metric.” Debugging a neural network means debugging statistics, not logic.
Rule of thumb: When a language model generates fluent, confident nonsense, the network learned the surface pattern of language without the constraint that would make the content accurate. The training signal taught it to sound right — not to be right.
When it breaks: Neural networks fail without raising exceptions. Unlike a compiler that halts on invalid input, a network with undertrained layers or contaminated training data produces output that reads fluently and sounds confident — but is wrong. The vanishing gradient problem can prevent deep layers from updating their weights meaningfully, creating dead weight inside the architecture. And memorization of training examples — rather than generalization from them — can make a model perform well on benchmarks while collapsing on inputs it has never encountered.
What should you learn before studying neural networks for LLMs?
Three branches of mathematics carry most of the weight.
Linear algebra — matrix multiplication, vector spaces, dot products. Every forward pass is a matrix-vector multiplication. If the operation “multiply a weight matrix by an input vector to produce an output vector” remains opaque, the rest of neural network theory will be notation without intuition.
Calculus — specifically, the chain rule and partial derivatives. Backpropagation is the chain rule applied recursively across a computational graph. The intuition matters more than the formal proof: each weight receives a gradient, and that gradient is a direction.
Probability — conditional distributions, expectation, cross-entropy. Language modeling is conditional probability estimation: P(next token | all preceding tokens). Every training step minimizes how wrong that estimate is. Cross-entropy is how “wrong” gets measured.
For implementation, PyTorch is the dominant framework. The current release is 2.11.0, released March 2026 (PyTorch GitHub). The official “Deep Learning with PyTorch: A 60 Minute Blitz” tutorial (PyTorch Docs) is the most direct entry point for building your first network. Google’s Machine Learning Crash Course (Google Developers) covers neural network fundamentals without requiring commitment to a specific framework.
Compatibility note:
- PyTorch TorchScript: Deprecated as of PyTorch 2.10. Older tutorials referencing TorchScript for model export should use
torch.exportinstead.- PyTorch Anaconda channel: The official Anaconda channel is deprecated. Install via pip or conda-forge.
The Data Says
Neural networks are arithmetic engines that learn statistical structure through repetition and error correction. The mechanism — forward pass, loss computation, backpropagation, weight update — has not changed in principle since 1986. What changed is scale: more layers, more weights, more data, more compute. Every large language model in production — from GPT-5.4 to Claude Opus 4.6 to Llama 4 Scout — runs this same loop on hardware that lets the numbers converge faster and on datasets large enough to capture the statistical structure of human language. Understanding this loop is not background context. It is the foundation.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors