What Are Retrieval-Augmented Agents and How They Combine Agentic Reasoning with Dynamic Retrieval
Table of Contents
ELI5
A retrieval-augmented agent is an LLM that decides whether to search, what to search for, and how many times — instead of automatically retrieving once on every query. The agent owns the loop; retrievers become tools it can choose to call.
Most teams discover retrieval-augmented agents the same way: a perfectly ordinary RAG pipeline starts returning confidently wrong answers, and nobody can figure out why. The retriever looks fine. The chunks are on-topic. The embeddings rank the right document first. And the model still produces an answer no one in the room recognises.
The bug is not in the retriever. It is in the assumption that every question deserves the same retrieval strategy.
That assumption is precisely what agentic retrieval drops.
The Pipeline Gets a Veto
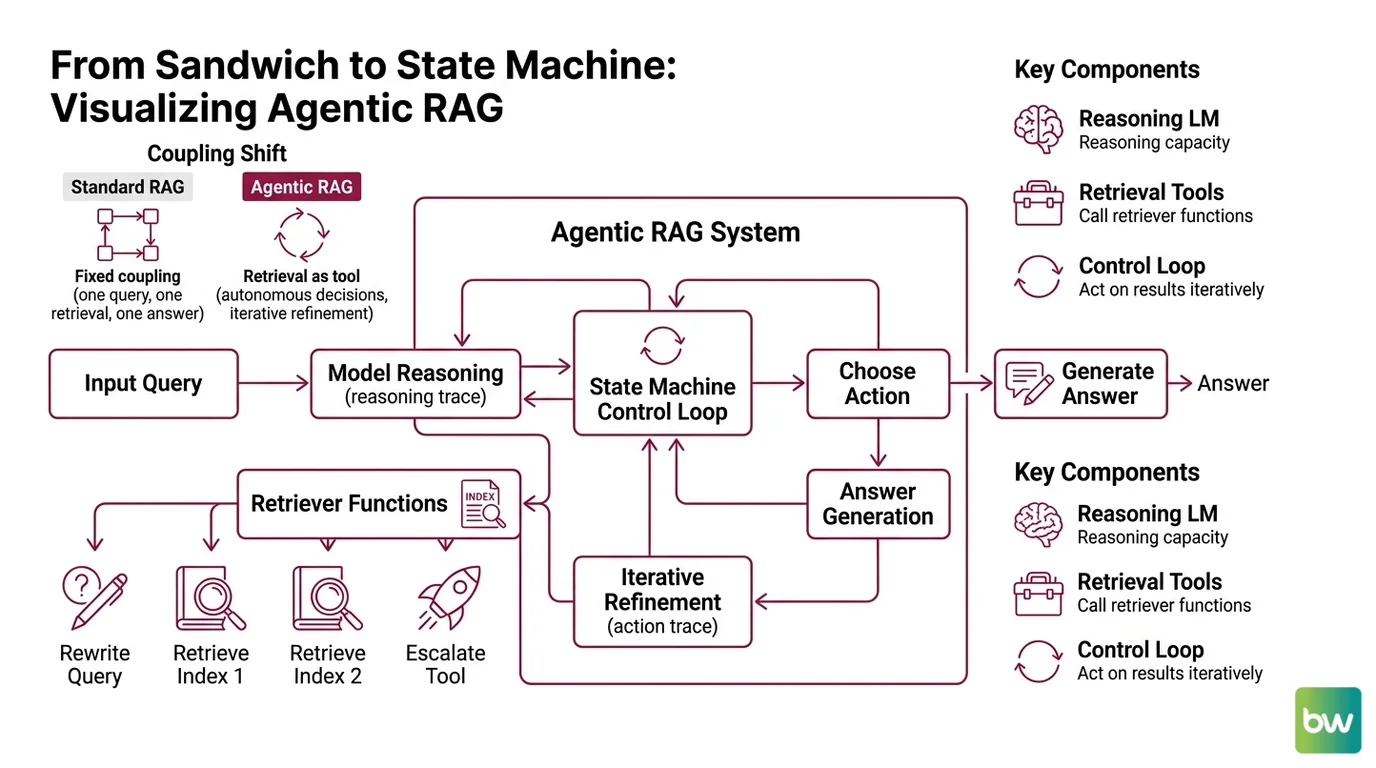
Vanilla RAG is a script with two steps: embed the query, fetch the top-k chunks, hand them to the model. The model never decides whether retrieval was the right move. It just consumes whatever arrives. Agentic retrieval inverts that contract — the model decides first, and the retriever serves on demand.
What are retrieval-augmented agents?
A retrieval-augmented agent is an LLM agent that treats retrievers as tools and makes the retrieval decision itself. The canonical definition (Singh et al., 2025) is precise: agentic RAG “embeds autonomous AI agents into the RAG pipeline so they can dynamically manage retrieval strategies, iteratively refine context, and adapt workflows.”
The shift is small in words and large in geometry. In vanilla RAG, the control flow looks like:
query → embed → retrieve → generate
In an agentic system, it looks like:
query → agent → {retrieve? rewrite? answer directly? call another tool?} → maybe loop
The arrow into the agent is the only mandatory edge. Everything else is conditional.
Not a different retriever. A different controller.
Four agentic design patterns recur across implementations: reflection, planning, tool use, and multi-agent collaboration (Singh et al., 2025). None of them are about better embeddings or fancier reranking. They are all about who decides what happens next.
That distinction matters because a router that picks between three retrievers is already an agentic RAG system. So is a single agent looping over the same retriever until it judges the evidence sufficient. So is a meta-agent dispatching sub-agents across a hundred contracts. The family is broad — and its smallest member is much smaller than most tutorials suggest.
How do retrieval-augmented agents decide when and what to retrieve?
The decision is structurally a two-stage routing problem.
In LangGraph’s reference implementation, stage one is a node called generate_query_or_respond. The LLM has the retriever bound as a tool via .bind_tools(). On each turn it either emits a tool call (meaning: I need to retrieve) or it answers directly (meaning: I don’t). This is the entire mechanism for the retrieve-or-skip choice — no separate classifier, no policy network (LangChain Docs). The model’s tool-calling head is the controller.
Stage two evaluates what came back. A second node, grade_documents, asks the model to return a binary relevance score over the retrieved chunks. If the verdict is “relevant,” the graph routes to generate_answer. If not, it routes to rewrite_question, which produces a new query and re-enters the retrieve loop.
That feedback edge is what separates agentic retrieval from chained retrieval. A chain pipes outputs forward. A graph can route backward. The retriever can be called twice on the same turn, with different queries, because the agent decided the first attempt was insufficient.
This is also where Workflow Orchestration For AI earns its keep. Routing decisions, retries, and grading nodes need a runtime that can hold state across loops, surface intermediate observations, and stop when a criterion is met. The framework is not optional scaffolding; it is the substrate the decision policy runs on.
LlamaIndex’s simplest variant — the router query engine — collapses the same idea into one choice: given several specialised RAG engines (one for Q&A, one for summarisation, one for tabular lookups), pick the right one. This is the smallest possible agentic RAG: one LLM, several retriever-tools, no loop (LlamaIndex Blog). From there, the same pattern scales to a ReAct agent maintaining state across a multi-step query (LlamaIndex Docs), and ultimately to Agentic Document Workflows where a meta-agent coordinates sub-agents that each own smaller document collections.
The progression — router → ReAct → meta-agent — is the same mechanism applied at three timescales. One turn. A handful of turns. A whole workflow.
Components, Not a Canonical Architecture
The literature does not converge on a single 4-box diagram, and that absence is informative. The arXiv survey gives design patterns; framework docs name specific nodes; vendor blogs offer pedagogical decompositions. What they agree on is the role each component plays in the decision loop, not the names of the boxes.
What are the core components of a retrieval-augmented agent system?
One useful decomposition (Weaviate Blog) lists four functional elements:
- LLM with role and task — the reasoning engine, prompted with a system role and a task scope. This executes the decision loop.
- Memory — short-term (the conversation, scratchpad observations) and long-term (vector stores, knowledge graphs, prior session summaries). Short-term keeps the loop coherent; long-term keeps it grounded.
- Planning — reflection and routing. The agent inspects its own intermediate outputs and decides whether to retry, rephrase, or commit.
- Tools — retrievers, web search, calculators, APIs, and Code Execution Agents that run interpreted code on the agent’s behalf. Retrievers are first-class tools here, not a hardcoded pipeline stage.
This is one map of the territory, not the map. The survey treats the same functions as design patterns rather than architectural slots, and the framing matters when you start composing systems — patterns can be reused at different levels of granularity, slots cannot. Treat the four-element list as a teaching aid, not a checklist.
The retriever surface itself is also a design choice. A-RAG proposes hierarchical retrieval interfaces that expose three primitives directly to the agent: keyword search, semantic search, and chunk read (A-RAG paper). The agent picks granularity adaptively — broad keyword first, then semantic ranking, then a targeted chunk-level fetch when a specific passage is needed. The retrieval policy lives in the LLM’s tool-selection behaviour, not in a fixed top-k value baked into the orchestrator.
That is the deeper structural point. Vanilla RAG hardcodes the retrieval policy at design time; agentic RAG defers it until inference.
What the Loop Predicts
Once retrieval is a decision rather than a step, several behaviours follow as predictions rather than surprises.
- If the question is in distribution for pre-training, the agent will often skip retrieval entirely. That is correct behaviour, not a bug. Forcing retrieval on trivial questions injects noise into the prompt and degrades answers.
- If the first retrieval pass returns weak chunks, expect the agent to rewrite and re-retrieve. Latency goes up; correctness usually goes up faster.
- If the agent loops indefinitely, the fault is almost always in the grading prompt, not the retriever. The model needs a stopping criterion sharper than “is this relevant?”
The control-flow inversion also changes evaluation. Retrieval quality can no longer be measured in isolation. Recall@k is still meaningful per call, but the system’s quality emerges from the joint distribution of (decision, retrieval, judgment, answer). That joint distribution is what a finite-horizon partially observable MDP describes — which is exactly how agentic RAG is modelled formally in the systematisation of knowledge (Akhtar et al., 2026).
Rule of thumb: if your failures look like “fetched the wrong thing,” vanilla RAG can probably be fixed with better embeddings; if they look like “shouldn’t have fetched at all” or “should have fetched twice,” you have outgrown vanilla RAG.
When it breaks: agentic loops fail when the grading step is too lenient. The agent declares irrelevant chunks “relevant enough,” the loop terminates, and the answer is confident and wrong. Tight grading prompts plus a small retry cap are the usual fix; both add latency, and neither eliminates the failure mode entirely.
Security & compatibility notes:
- LangChain Serialization Injection (LangGrinch): CVE-2025-68664 affects agentic-RAG code that deserialises prompts or configs. Fix: upgrade
langchain-coreto 1.2.5 orlangchainto 0.3.81, and audit anyload()/loads()callers — the defaults changed (NIST NVD).- Legacy prompt loaders: CVE-2026-34070 — path traversal in
load_prompt()andload_prompt_from_config(). Both are deprecated and scheduled for removal in 2.0.0; migrate to the new prompt-loading API (LangChain Releases).- Tutorial freshness: Agentic-RAG code patterns from 2023–2024 are increasingly stale as the framework era gives way to agent SDKs and MCP. Prefer LangGraph or LlamaIndex Workflows examples dated 2025 or later (LlamaIndex Blog).
The Data Says
The defining move of agentic retrieval is not adding components — it is removing the assumption that retrieval should happen on every query. Once the agent owns the decision, the same loop generalises from a router (one choice) to a ReAct agent (many choices) to a multi-agent workflow (delegated choices). The retriever stops being a pipeline stage and becomes a callable surface.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors