What Are RAG Guardrails and How Grounding Stops Hallucinations

Table of Contents
ELI5
RAG guardrails are runtime checks that verify a generated answer is supported by the documents your retriever pulled. Grounding is the property they enforce: every claim in the output should trace back to a retrieved chunk, not to the model’s memory.
A retrieval pipeline pulls five clean documents — no jailbreaks, no poisoned payloads, just ordinary search results. The model generates an answer. The Guardrails approve it. The answer is wrong anyway. Recent work shows that benign retrieved context flips guardrail judgments in a meaningful fraction of cases — the guardrail isn’t broken, but its assumptions about the world it operates in are. That gap between “looks supported” and “is supported” is the entire subject of this article.
The Two Layers Hiding Behind a Single Word
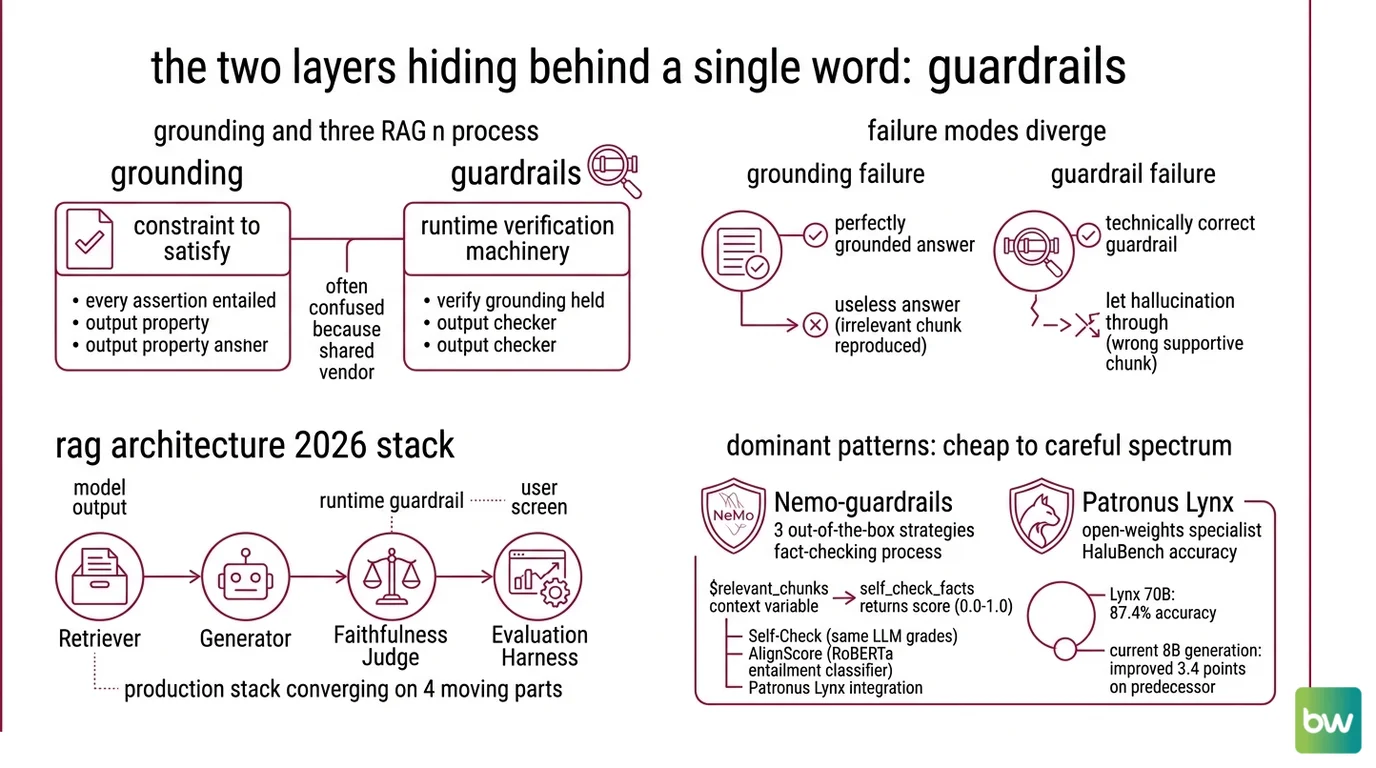
In most architecture diagrams, “guardrails” is one box bolted onto a RAG pipeline. The reality is two distinct mechanisms doing very different statistical work, often confused because they share the same vendor.
Grounding is the constraint we want the model to satisfy: every assertion in the response should be entailed by the retrieved context. Guardrails are the runtime machinery that tries to verify whether grounding actually held. One is a property of the output; the other is a checker.
This distinction matters because the failure modes diverge. A model can be perfectly grounded and still produce a useless answer (it faithfully reproduced an irrelevant chunk). A guardrail can be technically correct and still let a hallucination through (the chunk it scored looked supportive but wasn’t the one the model actually used).
What are RAG guardrails and grounding in 2026?
In 2026, the production stack has converged on roughly four moving parts: a retriever, a generator, a faithfulness judge, and an evaluation harness. The faithfulness judge is what most teams now call “the guardrail,” and it lives at runtime — between the model’s output and the user’s screen.
The dominant patterns sit on a spectrum from cheap to careful.
Nemo Guardrails ships three out-of-the-box fact-checking strategies: a Self-Check method that asks the same LLM to grade its own answer, AlignScore (a RoBERTa-based entailment classifier), and a Patronus Lynx integration. The framework feeds the retrieved evidence into the check via a $relevant_chunks context variable, and self_check_facts returns a numeric score between 0.0 and 1.0, per NVIDIA NeMo Docs.
Patronus Lynx is the open-weights specialist. The Lynx 70B model reaches roughly 87.4% accuracy on HaluBench, and the current 8B generation improves on its predecessor by 3.4 points on the same benchmark, according to Patronus Blog. The asymmetry matters: small enough to run inline as a guardrail, accurate enough that the latency cost has a defensible payoff.
For evaluation rather than runtime enforcement, the TruLens RAG Triad has become the de-facto vocabulary: Context Relevance, Groundedness, and Answer Relevance, three independent measurements of three independent failure modes (TruLens Docs).
Not a single technique. A small ecosystem of cooperating judges.
How does grounding work in retrieval-augmented generation systems?
Grounding works by reframing generation as constrained completion against a local evidence corpus, rather than free generation against the model’s prior. The mechanics are surprisingly geometric.
Step one: the retriever — typically a hybrid of dense embeddings and Sparse Retrieval — pulls a handful of chunks the system believes are relevant to the query. Step two: those chunks are concatenated into the prompt as context. Step three: the model generates a response conditioned on both the query and the retrieved evidence. Step four: a guardrail decomposes the response into atomic claims and asks, for each one, whether the retrieved chunks entail it.
That last step is where the actual work happens. TruLens groundedness, for example, breaks the response into atomic claims and independently checks each claim against the retrieved context (TruLens Docs). Patronus Lynx does something architecturally similar — train a small model whose only job is to read (claim, evidence) pairs and return supported or unsupported.
The conceptual analogy is closed-book versus open-book exams. Without grounding, the model is taking a closed-book exam and confidently filling in plausible answers from memory. With grounding, the model is supposed to be taking an open-book exam — and a guardrail is the proctor checking that every cited fact actually appears in the textbook in front of it.
Of course, even open-book exams have cheaters. The proctor matters.
Why the Same Math Both Helps and Hurts
The probability story underneath grounding is simple, and reveals why guardrails sometimes succeed and sometimes betray you.
A language model samples tokens from a conditional probability distribution shaped by everything in its context window. Adding retrieved chunks doesn’t insert “facts” — it shifts the geometry of that distribution so that tokens consistent with the retrieved text become more likely than tokens drawn from the model’s general prior. This is why grounding works at all: you are not teaching the model anything; you are reweighting what it would say anyway.
But the same mechanism is what makes guardrails fragile. A retrieved chunk that is benign in isolation can shift the distribution in ways that interact with the model’s training. Recent research finds that benign retrieved documents flip both input and output guardrail judgments at non-trivial rates — guardrails calibrated on clean prompts are not robust to RAG-style contexts (arxiv 2510.05310). The guardrail wasn’t fooled. The guardrail’s notion of “normal input” silently changed when retrieval was added to the loop.
This is why the field has moved toward decomposed atomic-claim checking rather than holistic grading. A whole-response check rides the same probability tide as the response itself; an atomic-claim check has a smaller surface for the tide to shift.
What FaithJudge changed in evaluation
The Vectara hallucination leaderboard, long the public yardstick for grounding quality, evolved its methodology in 2026 to incorporate FaithJudge — a few-shot LLM-as-a-judge with human annotations — instead of relying on HHEM as the sole judge (Vectara Blog). The shift acknowledges a structural problem: a single classifier judge becomes a single point of failure, and its blind spots become the field’s blind spots.
RAG Evaluation now treats faithfulness as something that requires multiple judges with different inductive biases, calibrated against a small core of human-labeled examples. Treat any single number — yours, theirs, anyone’s — as a noisy estimate, not a verdict.
What the Geometry Predicts
The mechanism makes some uncomfortable predictions, and they show up in production exactly where you’d expect.
- If the retriever surfaces a chunk that mentions the query topic but doesn’t answer it, expect the model to answer anyway, weaving the chunk’s surface vocabulary into a confident-sounding fabrication. This is “topic-shaped grounding”: the geometry shifted, but not toward truth.
- If your guardrail and your generator share an architecture family, expect correlated failure. Self-Check methods inherit the generator’s blind spots; an LLM-as-judge of the same lineage will rate its sibling’s mistakes as plausible. NVIDIA NeMo Docs lists Self-Check alongside AlignScore and Lynx for exactly this reason — diversity of judges is part of the defense.
- If you only check the final answer and not intermediate retrieval, expect a class of failure where the retriever was wrong but the generator was loyal. The output is grounded — in the wrong document. The TruLens triad separates Context Relevance from Groundedness for precisely this reason.
Rule of thumb: Pair a fast judge inline with a slow specialist downstream — diversity beats precision.
When it breaks: Guardrails calibrated on isolated prompts degrade once retrieved context enters the loop, and a guardrail can never catch a hallucination that was retrieved rather than generated — if the source document is wrong, faithful grounding will faithfully reproduce its mistake.
Security & compatibility notes:
- Guardrail robustness under RAG context: Research shows benign retrieved documents flip input/output guardrail decisions at material rates. Mitigation: layer atomic-claim checking on top of holistic guardrails; do not rely on a guardrail tuned on retrieval-free prompts.
- RAG context as exfiltration vector: EchoLeak (Microsoft 365 Copilot) and CVE-2026-22200 (osTicket via PHP filter chains, weaponized through agentic RAG tools) show that retrieved content itself is now a live attack surface. Mitigation: defend the retrieval index with the same rigor as user input; guardrails alone are insufficient (Cato Networks).
- AlignScore baseline age: AlignScore in NeMo Guardrails is supported out-of-the-box but the underlying RoBERTa model is older than the rest of the stack. Treat it as a fast classical baseline, not a frontier judge.
A Newer Direction Worth Watching
Most guardrails today operate as black-box judges over text. A 2026 line of research takes a different angle: read the model’s own internal activations to detect when its generation is drifting away from the retrieved evidence. The technique uses sparse autoencoders to surface interpretable features inside the model and flags faithfulness failures by inspecting them rather than scoring outputs (arxiv 2512.08892).
The interesting part isn’t the accuracy number. It’s the architectural shift. A guardrail that watches the model’s internal state, rather than its tokens, lives at a different layer of the stack — closer to the cause than to the symptom. Whether this generalizes is still an open empirical question. The direction it points is the right one.
Faithfulness-aware decoding, self-reflection, and inline verification — current research consolidates around mechanisms that intervene during generation rather than after it (arxiv 2506.00054). The post-hoc judge is becoming the floor, not the ceiling.
The Data Says
Grounding is not a feature you bolt on; it is a probability-shaping discipline that requires layered judges, decomposed claim checking, and explicit acknowledgment that the retriever’s truthfulness is now part of your security model. As of 2026, the strongest production stacks pair an inline fast judge with a slow specialist (Lynx, FaithJudge), defend the index itself, and treat any single faithfulness number as a noisy estimate rather than a verdict.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors