What Are Code LLMs and How CodeLlama, DeepSeek Coder, and StarCoder Understand Source Code
ELI5
A code LLM is a large language model trained mostly on source code instead of prose. Same transformer machinery as a chatbot — but a diet of billions of code tokens teaches it the syntax, structure, and patterns of programming languages.
Give a general-purpose chatbot a half-finished function and ask it to fill the gap, and it often returns something that reads like code and refuses to compile. Hand the same fragment to a code LLM and it closes the missing lines — sometimes from both directions at once, the top and the bottom converging toward the middle. Same underlying transformer. Strikingly different behavior. The interesting question is not which one is smarter. It is what changed.
The Same Machinery, a Different Diet
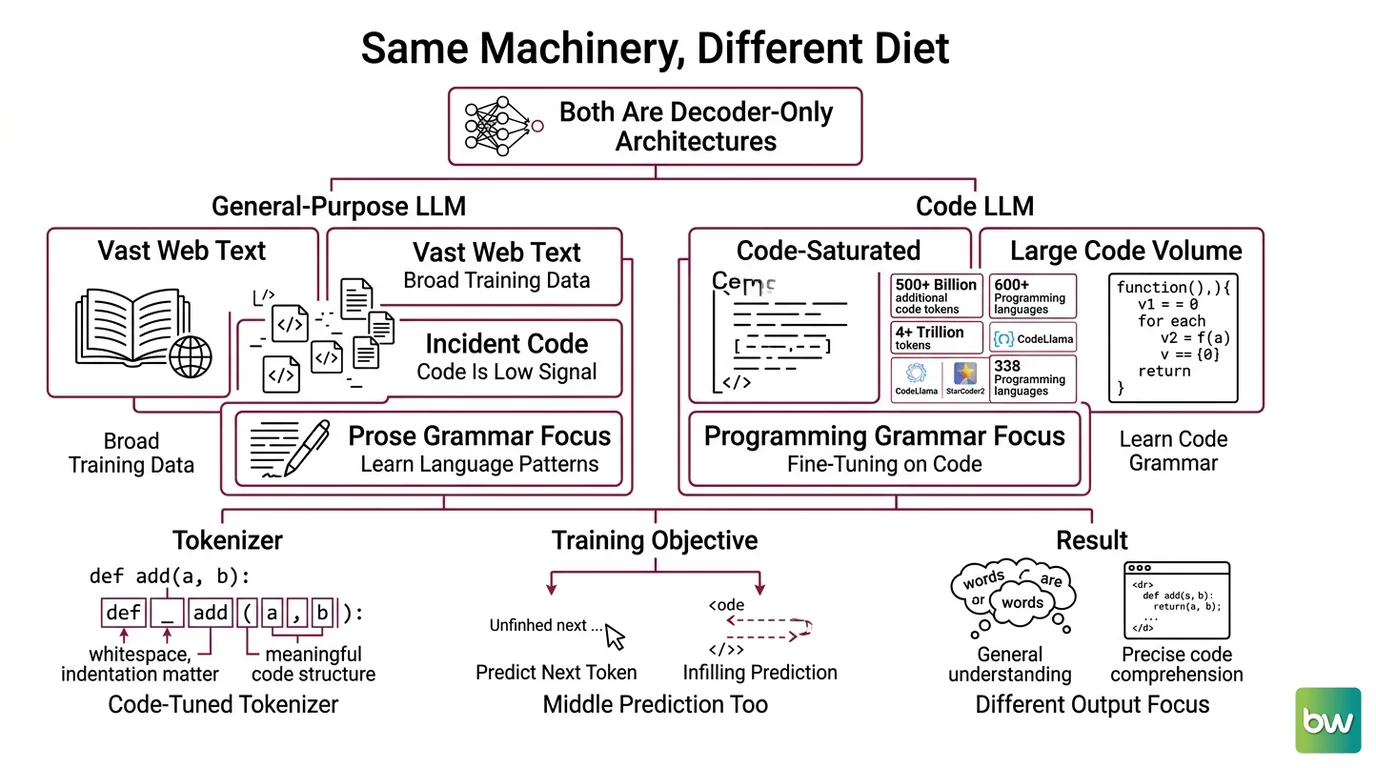
A code LLM is not a new species of neural network. Under the hood it is the same Decoder Only Architecture that powers a conversational model: stacked attention layers predicting one token at a time. What separates the two is not the wiring. It is what flows through the network during training, and how the model is taught to read what flows in.
What are code LLMs and how are they different from general-purpose LLMs?
A general-purpose LLM learns from a broad sweep of web text, with source code present only incidentally. A code LLM inverts the ratio. It is trained — or fine-tuned — until code dominates the signal. Code Llama, for example, is a Fine Tuning of Llama 2 on more than 500 billion additional code tokens (Code Llama paper). StarCoder2-15B was trained on over 600 programming languages and more than 4 trillion tokens (Hugging Face Blog). DeepSeek Coder V2 widened its language coverage to 338 programming languages, up from 86 in its prior generation (DeepSeek-Coder-V2 paper).
That shift in diet produces three concrete differences from a chat model:
- The corpus is code-saturated, so the statistical patterns the model absorbs are the grammar of programming languages, not the grammar of essays.
- The tokenizer is tuned for code — whitespace, indentation, and bracket structure carry meaning, so the way text is split into tokens matters more than it does for prose.
- The training objective is different. Chat models only ever predict what comes next. Code models also learn to predict what belongs in the middle.
Not a different brain. A different diet.
How do code LLMs like CodeLlama and DeepSeek Coder understand and generate code?
Start with how the model sees a file. Source code is split into tokens by a Subword Tokenization scheme, the same family of techniques a chat model uses — but here runs of spaces, newlines, and common identifiers get their own efficient encodings, because a tokenizer that wastes tokens on indentation cannot fit much of a function into its window.
The base mechanism is Next Token Prediction. The model reads a prefix and assigns a probability distribution over the token most likely to follow, then samples one, appends it, and repeats. This left-to-right Autoregressive Generation is exactly how a chatbot produces a sentence. It is why a code model can continue a function you have already started.
What it does not do is parse your code into an Abstract Syntax Tree, type-check it, or run it. It assigns probability to the next token conditioned on everything visible in context. It has learned the statistical shape of valid code so thoroughly that the most probable continuation is usually a syntactically correct one.
Not parsing. Prediction.
The second mechanism is what makes a code model feel different from a chatbot: Fill-in-the-Middle, or FIM. During training, a document is split into a prefix, a middle, and a suffix, and the model learns to predict the middle given both ends. Code Llama’s 7B and 13B variants were trained with this infilling objective alongside ordinary autoregressive prediction (Hugging Face Blog), and StarCoder2 used Fill-in-the-Middle on the The Stack v2 dataset (Hugging Face Blog). This is the mechanical reason a code model can complete a missing line inside an existing function, not just append to the end — it learned to condition on what comes after the cursor, not only what comes before.
Context length governs how much of your project the model can hold at once. Code Llama was trained at a 16K-token window and, through RoPE position scaling, extrapolates stably to sequences as long as 100K tokens (Hugging Face Blog) — an extrapolation ceiling, not its trained length. DeepSeek Coder V2 extends its window to 128K tokens, scaled up from 16K using YaRN (DeepSeek’s GitHub repository). The longer the stable window, the more surrounding code the model can condition on, and conditioning is where most of the apparent intelligence lives.
Anatomy: The Parts That Make a Code Model
Strip a code LLM down and the same handful of components appears every time, regardless of which lab built it. Understanding the parts is the difference between treating the model as a black box and predicting how it will behave.
What are the main components of a code LLM?
Five pieces do the work:
- A code-aware tokenizer that converts raw source into tokens without squandering them on whitespace.
- A Transformer Architecture decoder stack — the attention and feedforward layers that do the actual prediction.
- An efficiency mechanism for serving large models affordably. StarCoder2 uses Grouped Query Attention with a 4,096-token sliding-window attention pattern inside its 16,384-token context (Hugging Face Blog). DeepSeek Coder V2 takes a different route: it is a Mixture Of Experts model with 16B and 236B total parameters, of which only 2.4B and 21B are active per token (DeepSeek-Coder-V2 paper) — large capacity, modest cost per inference step.
- A long-context strategy — Positional Encoding schemes such as RoPE scaling or YaRN that let the trained window stretch further at inference time.
- A training objective that pairs next-token prediction with Fill-in-the-Middle, and a curated code corpus to learn from — the open StarCoder line draws on datasets assembled by the BigCode project, an open-scientific collaboration for responsible code-model development (StarCoder paper).
The three models below are foundational, open-weight examples of the category rather than current performance leaders, but they show the design space clearly.
| Model | Sizes | Stable context | Notable trait |
|---|---|---|---|
| Code Llama | 7B, 13B, 34B; 70B (Jan 2024) | 16K trained, ~100K extrapolated | Fine-tune of Llama 2; FIM on 7B/13B |
| DeepSeek Coder V2 | 16B, 236B total (2.4B / 21B active) | 128K (via YaRN) | Mixture-of-Experts; 338 languages |
| StarCoder2 | 3B, 7B, 15B | 16,384 (sliding window 4,096) | FIM on The Stack v2; BigCode |
What should I learn before understanding code LLMs?
If you want the mechanism to click, build the foundation in this order. First, how any language model works: subword tokenization, the attention mechanism, and next-token prediction. Second, the transformer architecture itself, and specifically the decoder-only variant that nearly all code models use. Third, the distinction between Pre Training on a broad corpus and the fine-tuning step that specializes a base model for code. Fourth, the idea of a Context Window as a finite working memory.
Once those are solid, the code-specific layer is small: the Fill-in-the-Middle objective and the quirks of tokenizing source code. Everything distinctive about a code LLM is a specialization of machinery you already understand from general models.
What the Architecture Predicts
Knowing the mechanism turns guesswork into expectation. Because the model conditions on what it can see and predicts the statistically likely token, its failure modes are not random — they follow from the design.
- If your prompt omits the surrounding code, expect weaker completions. The model conditions only on what is in context; a lonely function signature gives it little to work with.
- If you ask for a language thinly represented in training, expect output that looks plausible and is more often wrong. Coverage in the corpus correlates with reliability.
- If you push past the trained window and lean on extrapolation, expect quality to drift as the sequence grows, because attention over very long contexts dilutes.
Rule of thumb: feed the model the surrounding code, not just the signature — context is the lever you actually control.
When it breaks: the model has no execution feedback. It predicts tokens that look correct; it cannot run the code, check types, or test edge cases. Confident, well-formatted output can still be logically wrong or quietly insecure, and the model gives no signal to distinguish the two.
The Data Says
A code LLM is a general transformer pointed at a narrow target: trained on a code-saturated corpus, tokenized for source, and taught to predict both the next token and the missing middle. Its competence is reproducible and its limits are predictable — it models the shape of correct code without ever verifying that any given output runs.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors