What Are Code Execution Agents and How Sandboxed Interpreters Let LLMs Run Their Own Code

Table of Contents
ELI5
A code execution agent is an LLM that solves tasks by writing and running its own code — usually Python — inside a sandboxed container, instead of emitting structured JSON to call external tools.
The standard mental model says an agent picks a tool from a menu, fills in JSON arguments, and waits for the result. Logical. Clean. Auditable.
Then the benchmark numbers came in, and the same agents — when allowed to write Python instead — started winning by margins that should not exist if both approaches were equivalent.
Something underneath was different.
When the Agent Writes Python, the Action Space Changes Shape
A JSON tool call is a closed form. Pick one of N tools. Fill the schema. Submit.
A line of Python is something else entirely: it can branch, loop, compose function calls, hold intermediate state in variables, catch errors, transform data structures, and decide what to do next — all inside a single action.
That structural asymmetry is the whole story.
On the paper’s benchmarks (API-Bank and a curated tool-use suite called M³ToolEval), CodeAct agents reached up to 20% higher task success rates than equivalent JSON-action agents across 17 LLMs evaluated, the CodeAct paper. They also got there in about 30% fewer interaction steps — fewer round-trips between the model and the runtime.
The mechanism is composition. The LLM is no longer choosing actions from a flat menu; it is programming. Python’s syntax already encodes things JSON has to fake: conditionals, iteration, variable binding, exception handling. An agent writing code can express “fetch all repos, filter the public ones, summarize the top three by stars” in a few lines. An agent emitting JSON has to plan that across multiple turns.
Not a clever prompt trick. A shift in the action space.
The Mechanism: Code as the Programming Language for Action
Three things make code-as-action work: a model trained to emit valid Python, a sandboxed runtime that can execute it without endangering the host, and a feedback channel that returns stdout, stderr, and tracebacks to the model’s next inference pass.
Together they form a loop the model can iterate inside — write, run, read the output, revise.
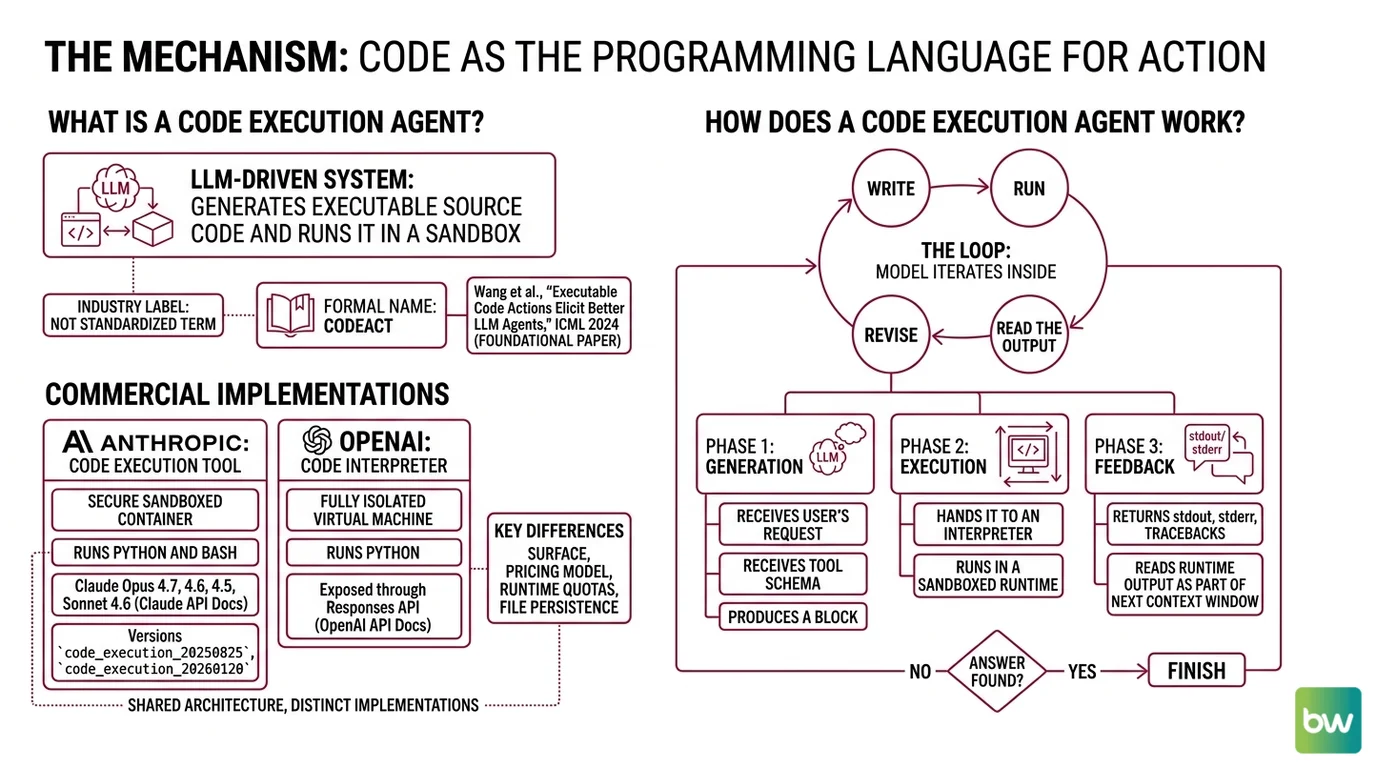
What is a code execution agent?
A code execution agent is an LLM-driven system whose primary mode of acting on the world is to generate executable source code and run it in a sandbox. The model receives a goal, drafts code, hands it to an interpreter, and reads the runtime’s output as part of its next context window.
The term is not yet standardized in academic literature — it’s an industry label rather than a formal taxonomy. The closest formal name is CodeAct, from Wang et al., “Executable Code Actions Elicit Better LLM Agents,” published at ICML 2024 and cited as the foundational paper for code-as-action agents, the CodeAct paper.
Two concrete commercial implementations sit on either side of the same idea. Anthropic’s code execution tool runs Python and Bash inside a secure sandboxed container and is available on Claude Opus 4.7, Opus 4.6, Sonnet 4.6, and Opus 4.5 (Claude API Docs). The current tool versions are code_execution_20250825 and code_execution_20260120. OpenAI’s Code Interpreter runs Python inside a fully isolated virtual machine, exposed through the Responses API (OpenAI API Docs).
Both share the same architecture. They differ in surface, pricing model, and runtime quotas — and in how they handle file persistence, which becomes the operationally interesting part later.
How does a code execution agent work?
The loop has three phases, repeated until the model decides it has the answer.
It begins with generation. The model receives the user’s request plus the tool schema for code execution. It produces, as part of its output, a block of code — wrapped in a tool-use envelope the runtime can parse out.
Then comes execution. The runtime extracts the code, sends it to a sandboxed interpreter, and waits for completion. The sandbox is the safety boundary: it bounds CPU, memory, network reach, and filesystem access. It also bounds time — OpenAI’s containers expire after 20 minutes of inactivity, at which point any in-container data is discarded (OpenAI API Docs).
The last phase is observation. The interpreter returns standard output, standard error, and any structured artifacts the runtime supports — files written, images rendered, dataframes serialized. The model reads these as new context tokens on its next inference pass.
The interesting part is that third phase. A failed JSON tool call returns an error code; a failed Python script returns a traceback. Tracebacks contain the line number, exception type, and often enough state to suggest a fix. The model uses them the way a human would: read the trace, edit the line, run again.
That repair signal is doing more work than it looks like it is.
The Stack: What Sits Between the LLM and Your Filesystem
Two layers separate the model from the machine. The first is the agent framework, which decides when to call the interpreter and how to thread results into the next prompt. The second is the sandbox, which decides what the interpreter is actually allowed to do.
Confusing the two is the most common architectural mistake in this space. Every commercial stack keeps them distinct.
What are the components of a code execution agent stack?
Four pieces, each replaceable.
The model. Any LLM trained to emit syntactically valid code in the target language. Frontier models do this well in Python; the long tail is rougher. Practical stacks pin to a small set of known-good models, because the failure mode of a weaker model isn’t “bad reasoning” — it’s “syntax error on line 7.”
The agent framework. The orchestration layer that wraps the model, manages the tool schema, parses code blocks out of model output, dispatches them to the runtime, and folds results back into context. Code execution sits inside the broader pattern of
Workflow Orchestration For AI, but with a much tighter inner feedback loop. HuggingFace’s smolagents is the canonical open-source reference: it exposes two agent types — CodeAgent, which writes Python directly, and ToolCallingAgent, which uses the JSON pattern (smolagents Docs).
The sandbox runtime. This is where the code actually executes. Production stacks rarely run agent code in their own process. Instead they delegate to a hardened isolation layer. smolagents supports several interchangeable sandbox backends: Modal, Blaxel, E2B, and Docker. E2B uses Firecracker microVMs — the same lightweight virtualization technology AWS Lambda uses — to give each session its own isolated Linux VM. Per E2B’s own documentation, cold starts run under 200 ms in the same region as the client, and sessions can persist up to 24 hours.
The host shell. Claude Code is a useful counterexample to the remote-sandbox pattern: instead of running agent-generated code inside a remote container, it runs it on the developer’s local machine, then constrains what that code is allowed to touch. The isolation layer uses Linux bubblewrap and macOS seatbelt to bound filesystem and network access at the OS level (Claude Code Docs). Internal usage at Anthropic showed an 84% reduction in permission prompts after the sandbox launched (Anthropic Engineering Blog) — the agent does more without asking, because the OS is what says no.
Each layer has its own threat model. The model can be misled by prompt injection. The framework can be tricked into running code it shouldn’t. The sandbox can leak host resources if misconfigured. Production systems assume all three will fail and design accordingly.
What the Architecture Predicts
If the action space is the thing that matters, then certain behaviors should follow without anyone having to design them in.
- If a task requires composing several tools, expect code-action agents to finish in fewer turns than JSON-action agents — that’s the step-reduction effect, reproducible across model families on the CodeAct benchmarks.
- If a task requires complex data manipulation (pandas, numpy, plotting), expect code agents to massively outperform — they’re operating in the language those libraries were designed for.
- If a task is a single, well-defined API call, the gap collapses or reverses. JSON tool-calling is fine, sometimes better, when there is nothing to compose.
- If you swap a frontier model for a smaller one, expect the code-action advantage to shrink. Smaller models write worse Python, and the sandbox punishes syntax errors faster than the framework punishes malformed JSON.
Rule of thumb: Use code-as-action when the task is compositional and the model is strong enough to write reliable Python on the first try. Use JSON tool-calling when the action is atomic and the cost of a bad call is high.
When it breaks: Code execution agents trade safety for expressivity. A model that can write any Python can also write Python that exfiltrates secrets, deletes files, or pivots to network resources — and prompt injection turns user-controlled text into potential attacker code. Without a sandbox you trust, code execution agents are an exploit surface, not a productivity feature.
Security & compatibility notes:
- OpenAI Assistants API deprecation: The Assistants API surface for Code Interpreter sunsets on August 26, 2026. After that date,
/v1/assistants,/v1/threads, and/v1/runswill return errors. Migrate Code Interpreter integrations to the Responses API and Conversations API (OpenAI Deprecations page).- LangChain Core “LangGrinch” (CVSS 9.3): CVE-2025-68664 — a serialization injection in
dumps()/dumpd()lets prompt-controlled fields execute arbitrary code. Patch LangChain Core before exposing any LangChain agent with code execution to untrusted input (The Hacker News).- Prompt-injection → RCE patterns: Microsoft Security (May 7, 2026) demonstrated remote code execution via prompt injection across multiple agent frameworks, including Semantic Kernel. Treat any non-sandboxed code execution path as an untrusted execution surface (Microsoft Security Blog).
A Quieter Consequence
The reason CodeAct works is not really about Python. It’s about giving the model an action representation that matches the structure of the problems it’s being asked to solve.
JSON tool calls assume the world decomposes into discrete labeled functions. Real tasks rarely do. They branch, accumulate state, depend on the result of the previous step. A function-calling protocol forces the model to flatten that into a sequence of stateless calls; a programming language lets the state stay where it belongs — in variables, in scope, in the runtime.
This is the same reason functional programmers like monads and imperative programmers like for-loops: the right representation of the problem makes the solution obvious. The wrong representation makes it nearly impossible.
The sandbox is just the price of admission.
The Data Says
Code-as-action agents reach up to 20% higher task success and use about 30% fewer steps than JSON tool-calling agents on the CodeAct benchmarks — but the mechanism is composition, not Python itself. The expressive jump is the gain. The sandbox is the constraint that lets a team take that gain without losing their filesystem in the process.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors