What Are Benchmark Datasets and How GLUE, MMLU, and SWE-bench Measure LLM Performance
Table of Contents
ELI5
A benchmark dataset is a fixed set of tasks with known-correct answers and a scoring rule. Run a model against it and you get one comparable number — the basis for every “state-of-the-art” claim you have ever read.
A benchmark is supposed to be a fixed ruler. The most influential ones in AI have a stranger habit: they die. GLUE arrived in 2018 as a serious challenge for language models and was effectively solved within a year. SWE-bench landed in 2023 with the best available model resolving under two percent of its tasks; less than three years later, the top reported scores brush ninety-five percent. The ruler keeps shrinking against the thing it measures. That decay is not a defect — it is the clearest evidence of what a benchmark dataset really is.
The Frozen Contract Behind Every Score
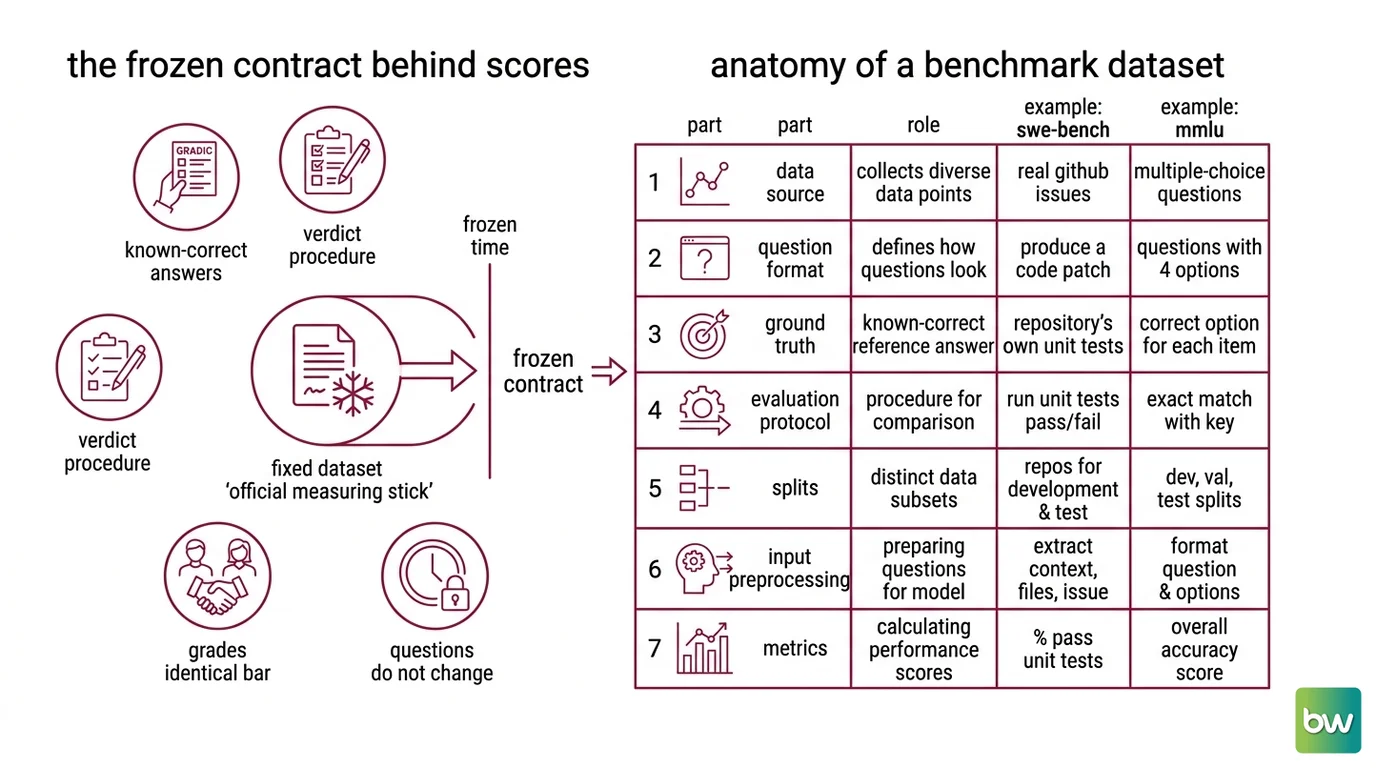
Every leaderboard, every “beats the last model on…” headline, every model card traces back to the same object: a dataset someone froze in time and declared the official measuring stick. To understand why scores behave the way they do, start with what that act of freezing commits you to.
What are benchmark datasets in AI?
A benchmark dataset is a fixed collection of task instances, each paired with a known-correct answer and a rule for deciding whether a model’s output matches it. The fixedness is the whole point. Once published, the questions and answers do not change, so two models tested a year apart are graded against the identical bar.
Three datasets show how wide that idea stretches. GLUE — the General Language Understanding Evaluation, introduced by Wang et al. (2018) — bundled nine natural-language tasks, from sentiment classification to sentence-pair similarity, behind a single aggregate score. MMLU Benchmark, from Hendrycks et al. (2020), asks 15,908 multiple-choice questions with four options each, spread across 57 subjects from elementary mathematics to professional law. SWE Bench, from Jimenez et al. (2023), hands a LLM 2,294 real GitHub issues and asks it to produce a patch that makes the repository’s own unit tests pass.
Three different surfaces — classification, recall, and working code — but the same skeleton underneath. Each one pins down a question, a Ground Truth answer, and a verdict procedure.
Not a test you grade by feel. A frozen agreement about what counts as correct.
Anatomy of a Yardstick
A benchmark only produces a comparable number because every part of it is specified in advance. Strip one away and the comparison stops being fair. Here is what the machine is made of.
What are the parts of an LLM benchmark dataset?
A working LLM benchmark has seven moving parts:
| Part | Role | Example (SWE-bench / MMLU) |
|---|---|---|
| Task instances | The inputs the model must handle | A GitHub issue / a multiple-choice question |
| Gold answers | The reference the output is checked against | The merged human patch / the correct option |
| Data splits | Separate train, dev, and held-out test items | Held-out test issues / held-out test questions |
| Scoring harness | The code that grades an output | Unit-test runner / exact-match check |
| Evaluation metric | The number the harness emits | Percent of issues resolved / accuracy |
| Leaderboard | The public ranking of results | SWE-bench Verified board / MMLU table |
| Diagnostic set | Optional probes for specific weaknesses | GLUE’s hand-built diagnostic suite |
The Train Test Split matters more than it looks. The held-out test items are the ones a model must never have seen during training; they are what makes the score a claim about generalization rather than recall.
How do benchmark datasets evaluate and compare language models?
Evaluation is the moment the harness turns outputs into a verdict, and the method depends entirely on what “correct” means for the task. MMLU uses exact-match scoring: the model picks A, B, C, or D, the Evaluation Harness compares it to the gold letter, and accuracy is the fraction it gets right. No interpretation, no partial credit.
SWE-bench cannot work that way, because there is no single correct patch. Instead it grades by execution: the model’s code is applied to the repository and the real unit tests run. A task counts as resolved only if the previously failing tests now pass (FAIL_TO_PASS) and the previously passing tests still pass (PASS_TO_PASS). The metric is the percent of issues resolved.
Both then collapse to a single comparable number and publish it on a leaderboard. That collapse is what makes benchmarks so persuasive — and so easy to misread. The number compares two models only on the exact distribution the dataset froze, nothing beyond it.
How Difficulty Gets Manufactured
A benchmark is only as honest as its construction. If the questions are easy to game or the answers are sloppy, the score measures the wrong thing. The three datasets reveal three escalating strategies for manufacturing trustworthy difficulty.
How are AI benchmark datasets constructed?
GLUE took the cheapest path: aggregate existing, human-annotated language tasks into one suite, and pair it with a hand-built diagnostic set, per Wang et al. (2018). MMLU went further, with questions hand-collected from real exams — practice tests, undergraduate courses, professional licensing material — so that answering well demands subject knowledge rather than pattern-matching.
SWE-bench shows the most defensive design. Jimenez et al. (2023) built it through a three-stage pipeline: scrape issue-and-pull-request pairs from twelve popular Python repositories, filter for tasks whose attributes look well-formed, then keep only the ones that survive an execution filter — the patch must actually exercise the test suite. The result is a benchmark made of real issues, not invented ones, which is exactly why the best model at release resolved only 1.96 percent of them.
That defensiveness still has gaps, and the fix points to the next frontier. Human curation followed: OpenAI’s SWE-bench Verified released a subset of 500 tasks, each reviewed by three software engineers and filtered down from 1,699 candidates to remove under-specified problems and over-strict tests. Construction is also drifting toward Synthetic Data Generation, where models help generate or mutate candidate items — useful for scale, risky for trust, because a benchmark partly written by the systems it grades is harder to keep honest.
Why Good Benchmarks Self-Destruct
Now the opening anomaly resolves. A benchmark dies because models climb it — and because a frozen target invites two specific failure modes. The first is honest saturation: once frontier models meet or beat the human baseline, the dataset can no longer tell the best systems apart. GLUE hit that wall fast and was superseded by the harder eight-task SuperGLUE (Wang et al., 2019); MMLU largely saturated at the frontier and spawned MMLU-Pro (MMLU-Pro paper, 2024), which adds tougher items and expands each question to ten answer options. Even SWE-bench Verified is fading as a frontier signal — OpenAI now states it no longer measures frontier coding capability, since top scores are saturating.
Treat a benchmark as active understanding rather than a trophy, and it starts making predictions:
- If a benchmark’s top score approaches the human baseline, expect it to lose discriminating power and be replaced within a year or two.
- If a model’s score jumps without a matching jump in real-world capability, suspect the test distribution leaked into training.
- If scores are vendor-reported on a saturating benchmark, expect the rankings to be noisy and to move week to week.
That last point is live right now. As of mid-2026, the best publicly reported SWE-bench Verified scores cluster near ninety-five percent against an average around 63 percent across the dozens of models tracked (LLM-Stats) — but those figures are largely self-reported and volatile, so read them as a snapshot, not a standing.
The second failure mode is the dangerous one. Benchmark Contamination happens when held-out test items leak into pretraining data, usually because the benchmark is public and the open web is the training set. Data Leakage of this kind inflates the score without improving the underlying ability.
Rule of thumb: A benchmark number is only meaningful paired with its date and some evidence that the test set stayed out of training.
When it breaks: When held-out items leak into the training corpus, the benchmark stops measuring generalization and starts measuring Memorization — the score climbs while real capability does not, and you only notice when the model fails on inputs the leaderboard never covered.
The Data Says
A benchmark dataset is not a verdict on intelligence; it is a frozen, scored contract about one narrow distribution of tasks. GLUE, MMLU, and SWE-bench each tightened that contract — from aggregated labels to expert questions to executable tests — and each is being outrun as models saturate it. The durable skill is not trusting the number; it is asking what the dataset froze, and whether the model ever got an early look.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors