Agent Memory Systems: How LLMs Get Persistent Recall Across Sessions
Table of Contents
ELI5
Agent memory systems are storage layers wrapped around an LLM. They extract facts from a conversation, save them outside the prompt, and inject the relevant ones back so the agent remembers what you told it last week.
A useful way to feel the problem: open a chat with any base model, tell it your name, your stack, and three things you hate. Close the tab. Open a new one tomorrow. It is a stranger again.
This is not a bug. The transformer is doing exactly what it was built to do — predict the next token from the current context window, and nothing else. Statelessness is the default condition. Every illusion of memory in a production agent is something a developer bolted on top of that condition. The interesting question is not whether agents can remember. It is what kind of memory you actually built without realizing it.
Why Stateless Models Needed an External Substrate
A vanilla LLM has no place to put a fact. The weights are frozen at training time, and the only writable surface is the prompt. Once the conversation falls off the edge of the context window, it is gone — not forgotten, never recorded.
Early agent stacks tried to bluff their way around this. Buffer memory dumps the entire chat history into the next prompt until the window overflows. Summary memory compresses older turns into a paragraph. Both work briefly. Both collapse the moment the agent has to reason across sessions, weeks, or thousands of users.
Not a memory system. A delay tactic.
The shift that defines the current generation is treating memory as an external substrate the agent reads from and writes to deliberately, rather than something the context window happens to contain. The Packer et al. paper introducing MemGPT framed this explicitly: an LLM behaves like a CPU, the context window is RAM, and a tiered memory hierarchy provides the equivalent of disk (arXiv 2310.08560). The framework that grew out of that paper is now called Letta — the original “MemGPT” name now refers to the design pattern and the research, not an actively maintained product (Letta Blog).
What are agent memory systems in AI?
An agent memory system is the layer between an LLM and durable storage that decides three things on every turn: what is worth remembering, where to put it, and which fragments to surface back into the prompt next time.
Concretely, that means a memory system is responsible for:
- Extraction. Reading raw conversation, tool calls, and documents to identify candidate facts, preferences, events, and relationships.
- Consolidation. Deduplicating, merging contradictory updates, and deciding when a new fact supersedes an old one.
- Storage. Writing those facts into a backend — vector index, graph, key-value store, file tree, or some hybrid.
- Retrieval and injection. When a new query arrives, fetching the relevant subset and packing it into the prompt within the available token budget.
It is a separate system from Zep-style retrieval over external knowledge bases — the Episodic Memory of an agent is about what the agent itself observed and said, not about a corpus the engineer prepared in advance. Mem0’s API splits this into four memory types: long-term, short-term, semantic, and episodic.
The deeper point: a context window is not a memory system, even though it feels like one in conversation. A context window is the agent’s working memory — wide, fast, and lost the moment the inference finishes. Everything else has to be engineered.
How the Read-Write Loop Closes the Gap
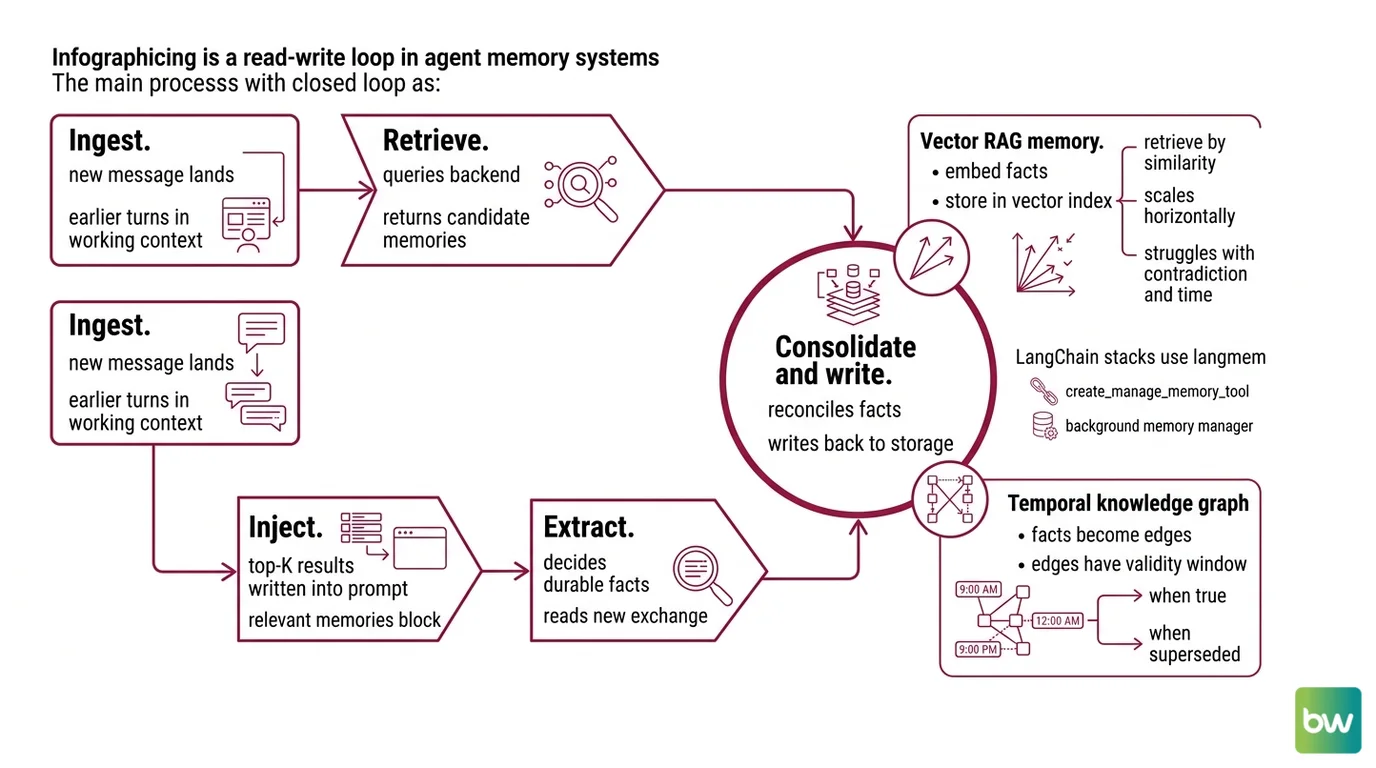
The mechanism is less mysterious than the marketing suggests. Every memory system runs the same closed loop on every turn: ingest, extract, store, retrieve, inject. What varies between architectures is where the loop happens, who makes the decisions, and what the storage actually looks like.
How do agent memory systems work to maintain context across tasks?
Walk through what happens when a user sends “remind me what we decided about the migration plan.”
- Ingest. The new message lands. Earlier turns from this session are in the working context already; older sessions are not.
- Retrieve. The memory system queries its backend with some representation of the current request — embedding similarity, graph traversal, BM25, or all three at once. It returns a ranked list of candidate memories.
- Inject. The top-K results are written into the prompt, usually inside a structured “relevant memories” block, before the model generates its reply.
- Extract. After (or during) the reply, an extraction pass reads the new exchange and decides what is durable. “We picked Postgres for the migration” is a fact. “Cool, thanks” is not.
- Consolidate and write. The extracted facts are reconciled with what is already in storage — superseded entries marked, duplicates merged — then written back.
That loop is the architecture. The variations are in step 5, and they fall into a small number of patterns:
- Vector RAG memory. Embed every fact, store in a vector index, retrieve by similarity. Simple, scales horizontally, struggles with contradiction and time. This is what most LangChain stacks use by default through
Langmem, which exposes hot-path tools like
create_manage_memory_tooland a background memory manager that runs consolidation between turns. - Temporal knowledge graph. Every fact becomes an edge in a graph, and every edge has a validity window — when it became true, when it was superseded. Zep’s Graphiti engine, built on Neo4j, is the canonical example. Each new fact does not overwrite the old one; it invalidates it with a timestamp, so the agent can reason about when something was true (arXiv 2501.13956).
- Self-editing memory blocks. The agent itself owns the curation. Letta gives the model tools to read, write, and rewrite its own memory blocks — each block has a stable
block_idand is persisted independently. The agent decides what to remember, with no separate consolidator. - File-based context tree. Byterover takes the same agent-curated philosophy further, storing memory as a hierarchical tree of markdown files on the local filesystem, with ADD / UPDATE / MERGE / DELETE exposed as tools over MCP (ByteRover Docs).
- Layered hybrid stacks. Some systems combine all of the above. Supermemory stitches connectors, extractors, hybrid retrieval, a memory graph, and per-user profiles into a single layered pipeline.
The implication is that the choice of architecture picks its failure mode. Pure vector RAG fails on temporal contradictions (“but the plan changed last Tuesday”). Pure graph fails on fuzzy semantic recall. Self-editing blocks fail when the agent’s judgment about its own memory is wrong. A serious system picks that failure mode on purpose.
The Anatomy of a Memory System
Underneath the architectural label, every memory system is built from the same handful of components in different proportions. Naming them is what turns a vague “we use Mem0” into a design you can reason about.
What are the components of an AI agent memory system?
The components fall into four roles, and any production memory layer has all four — even when they are not labeled.
1. Memory types (what is being stored). Cognitive science gives the working vocabulary: working memory (the live context window), episodic memory (events the agent participated in), semantic memory (general facts the agent has been told), and procedural memory (how-to knowledge — workflows, tool patterns). Letta maps these onto three persistence tiers: Core Memory in the prompt, Recall Memory as a searchable conversation history, and Archival Memory as long-term tool-queried storage.
2. Storage backends (where it lives). Vector databases for similarity search, graph databases for relationships and time, key-value stores for fast lookups by ID, and increasingly the local filesystem for transparent, version-controllable memory. The variety is not accidental — no single backend is right for every retrieval pattern, and most production stacks end up running two or three in parallel.
3. Curation logic (what gets written). Extraction prompts that decide which facts to keep. Consolidation logic that handles updates, contradictions, and supersession. Forgetting policies — yes, deliberate forgetting — for stale or low-value memories. This is where the difference between a useful memory system and a noisy one actually lives. Most production failures trace back here.
4. Retrieval policy (what gets surfaced). Hybrid search is the rough consensus: semantic embeddings for fuzzy meaning, BM25 for exact terms, and graph traversal for relational queries. Zep reports roughly 300ms P95 retrieval latency on this kind of pipeline, with up to 18.5% accuracy improvement over flat-vector baselines on the LongMemEval benchmark — though both numbers are vendor-published, not from a neutral arena (arXiv 2501.13956).
The components are not optional — every memory system implements all four, even if implicitly. A buffer-memory chatbot has a trivial extraction policy (“keep everything”), a flat backend (the prompt), no consolidation, and a FIFO retrieval policy. It will fail predictably.
The rule that emerges is structural: a memory system is only as strong as its weakest component. A perfect vector store with a sloppy extractor will surface confident garbage. A brilliant extractor on top of a flat backend will eventually drown in itself.
What the Architecture Predicts
Once the loop is visible, certain agent behaviors become predictable rather than mysterious.
- If your memory stack is pure vector similarity, expect failures on time-sensitive contradictions — the agent confidently retrieves last quarter’s pricing because the embedding still matches the question.
- If your memory stack is a temporal graph, expect lower recall on metaphor and paraphrase — graphs do not gracefully match “what was the thing about the migration” against an edge typed
decision: database_choice. - If your agent self-edits its memory, expect drift — small biases in the model’s curation accumulate, and the long-term shape of memory reflects the model’s blind spots.
- If your memory volume is unbounded and your forgetting policy is “never,” expect retrieval quality to degrade as the index grows. A larger memory store is not automatically a smarter one.
Rule of thumb: match the storage shape to the dominant query shape. Conversational recall and preference modeling want vector or hybrid retrieval. Decision histories and entity relationships want a graph with time. How-to knowledge wants something close to files.
When it breaks: the hardest failure mode is silent staleness. A memory system can keep returning a fact long after the world (or the user) has moved on, because nothing in the storage layer marks the fact as expired. Without explicit supersession — temporal edges, validity windows, or a forgetting policy — every memory system eventually serves yesterday’s answer with today’s confidence.
The Pattern Worth Watching
The most interesting recent shift is not a benchmark number; it is a question about who curates the memory. Classical memory pipelines split the work — one model talks to the user, a separate background process extracts and consolidates. The newer pattern, visible in Letta’s self-editing blocks and ByteRover’s tool-based curation, lets the same agent that reasons about the task also rewrite its own memory in-line. That collapses the curator-runtime gap, but it also means the memory now reflects the agent’s preferences, not just the user’s facts. Whether that is a feature or a bug depends entirely on how aligned the agent’s curation policy is with what the user actually wants remembered. Nobody has a clean answer yet.
A second shift worth flagging: the field is quietly moving past LoCoMo. The Locomo Benchmark introduced 300-turn dialogues averaging around 9,000 tokens and up to thirty-five sessions per conversation (arXiv 2402.17753), and it has been the default proving ground for memory systems for over a year. But several vendors now treat LongMemEval — five hundred manually written questions across information extraction, multi-session reasoning, temporal reasoning, knowledge updates, and abstention — as the more discriminating test (arXiv 2410.10813). Articles still citing only LoCoMo are running a generation behind. Treat any single-benchmark leaderboard claim with the same skepticism you would treat a single-model benchmark claim — particularly because every public memory benchmark score available today is vendor-self-reported, not produced by a neutral evaluator.
The Data Says
Memory is not a feature you bolt onto a stateless model — it is a system you architect, with a read-write loop, an extraction policy, a storage shape, and a forgetting strategy. The frameworks differ in where each component lives, not whether it exists. Pick the architecture that matches your dominant query shape, and assume that whichever component you under-design is the one that will eventually fail in production.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors