What Are Agent Guardrails? How Permission Systems Constrain AI

Table of Contents
ELI5
Agent guardrails are programmable controls that enforce safety, policy, and permission boundaries on what an autonomous AI agent is allowed to read, say, and do — at every step.
An agent with a shell tool deletes the wrong directory. Another with database access leaks PII into a chat transcript. A third quietly hits a production API a thousand times in twenty seconds because a retry loop went unsupervised. None of these is a model failure in the strict sense — the model produced syntactically valid tool calls that the runtime happily executed. The failure was that nothing stood between the model’s output and the world.
That space — between a probability distribution over tokens and an actual filesystem write — is where guardrails live.
When the model has no hands of its own
A
Guardrails layer is not a feature you bolt onto an agent. It is the only thing standing between a next-token predictor and an irreversible action. The model itself has no concept of what is dangerous, what is policy-violating, or even what it is “allowed” to do. It samples tokens. The runtime decides whether those tokens become a rm -rf or a logged refusal.
This is why the OWASP GenAI Project frames the underlying risk as LLM06:2025 Excessive Agency, with three named root causes: excessive functionality, excessive permissions, and excessive autonomy (OWASP GenAI Project). The risk is not that the model is malicious. The risk is that the agent has been handed too many tools, with too much authority, and too little oversight.
What are agent guardrails in AI systems?
An agent guardrail is a programmable control that intercepts an agent’s inputs, outputs, retrievals, or tool calls and either allows them, modifies them, or blocks them — based on policy. The Wiz Academy synthesis describes the pattern as four layers: input guardrails (filtering what reaches the model), prompt-construction guardrails (what gets injected into the context), output guardrails (filtering what leaves), and tool/action guardrails enforcing least-privilege on function calls (Wiz Academy).
The terminology is not standardized. Anthropic calls them “permission modes” and “hooks.” NVIDIA calls them “rails.” LangChain calls them “guardrails.” Galileo calls them an “agent control plane.” The vocabulary differs because the concept is young, but the abstraction is consistent: a deterministic enforcement layer that does not trust the model.
That last phrase matters. The whole point of a guardrail is that it operates outside the LLM’s probability distribution. A model can be prompted to refuse harmful requests, but a prompt is a soft constraint — it shifts the posterior, it does not enforce it. A deny rule is a hard constraint. The runtime never even sends the call.
Not a soft preference. A hard refusal.
How constraints become guarantees
The leap from “the model usually behaves” to “the agent cannot do X” requires moving the decision out of the language model and into deterministic code. This is the central architectural insight of every modern guardrail system.
How do agent guardrails work to prevent harmful actions?
Consider how the Claude Agent SDK orders its checks. When the model proposes a tool call, the runtime evaluates it in this fixed order: first hooks, then deny rules, then permission mode, then allow rules, and finally the canUseTool callback (Claude Agent SDK Docs). Hooks run first because they can modify input or inject context before any policy is evaluated — they are the lowest-level intercept. Deny rules run next, and they hold even when the agent is in bypassPermissions mode. The agent cannot vote itself out of a deny rule.
This ordering is not cosmetic. It encodes a guarantee: certain actions are unreachable from inside the model’s decision space, regardless of how cleverly it constructs its tool call. The probability distribution can put all its mass on delete production_db, and the runtime will still refuse. The model is permitted to want anything; the system permits only what was pre-authorized.
NVIDIA’s NeMo Guardrails uses the same principle with different vocabulary. Its five rail types — Input, Dialog, Retrieval, Execution, and Output — each intercept a different point in the agent’s loop (NVIDIA NeMo Docs). Input rails reject malformed or adversarial prompts before they reach the model. Retrieval rails filter what comes back from a vector store. Execution rails wrap tool calls. Output rails inspect the model’s response before it is returned. Each rail is independently programmable, so a team can deny SQL injection patterns at the input layer without modifying the model or the prompt.
Meta’s Llama Guard takes a third approach: a separate classifier model trained specifically to label content as safe or unsafe along the MLCommons standardized hazards taxonomy. Llama Guard 4, released in April 2025, is a 12B multimodal classifier that evaluates both text and images, with multi-image support (Meta’s Llama Docs). Llama Guard 3 remains maintained alongside it — the 1B variant is the on-device option, and the 8B text-only and 11B vision models are still in active deployment for teams that don’t need multimodal classification.
The common thread across all three systems: the guardrail is a separate computation, with its own authority, that the agent cannot override. Whether it’s a deterministic rule, a Colang dialog policy, or a trained classifier, the enforcement layer sits between the model and the world.
Inside a guardrail stack
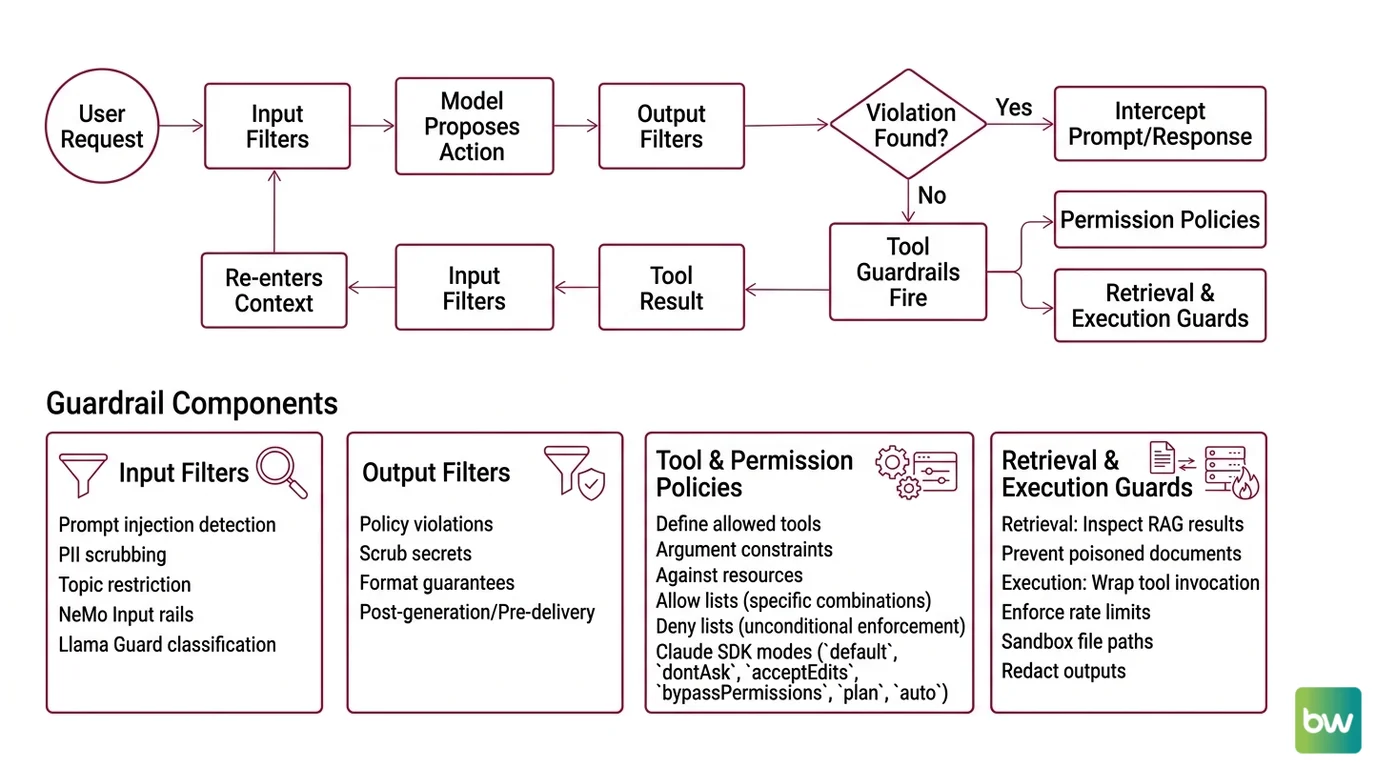
The four-layer model from Wiz Academy is a useful taxonomy, but it understates how the layers interact. In a real agent loop, a single user request triggers a cascade: input guardrails fire, the model proposes an action, output guardrails fire, tool guardrails fire, the tool result returns, and another round of input guardrails fires on the tool output before it re-enters the model’s context. Each turn passes through multiple gates.
What are the components of an agent guardrail system?
Four functional components show up across nearly every production stack:
Input filters. Pattern matching, classifier scoring, or LLM-based screening that intercepts the raw user prompt. This is where prompt injection detection, PII scrubbing, and topic restriction live. NeMo’s Input rails and Llama Guard’s classification calls both occupy this slot.
Output filters. The mirror image — applied to the model’s response before it reaches the user. Catches policy violations the model produced despite system-prompt instructions, scrubs leaked secrets, and enforces format guarantees. Output rails operate after generation but before delivery.
Tool and permission policies. The most consequential layer. Defines which tools the agent can call, with which arguments, against which resources. Claude Agent SDK exposes this through six permission modes — default, dontAsk, acceptEdits, bypassPermissions, plan, and auto (the last is TypeScript only) — combined with allow and deny rule lists. The deny list is enforced unconditionally; the allow list whitelists specific tool-argument combinations.
Retrieval and execution guards. Less visible but equally critical. Retrieval guards inspect what RAG returns before injecting it into the prompt — preventing poisoned documents from steering the model. Execution guards wrap the actual tool invocation — enforcing rate limits, sandboxing file paths, redacting outputs. These are where Agent Evaluation And Testing signals get wired in: every tool call can be logged, scored, and replayed.
A growing class of products treats this stack as its own control plane. Galileo released its open-source Agent Control on March 11, 2026, using a small-model runtime called Luna-2 to deliver low-latency input/output interception at sub-LLM cost (The New Stack). The architectural bet is that a dedicated guardrail layer — separate from the agent runtime — scales independently and can be governed by a different team than the one shipping the agent.
The standards layer is catching up. NIST AI 600-1, the Generative AI Profile published July 26, 2024, identifies twelve risk areas including Information Security and Human-AI Configuration, both of which map directly to guardrail design (NIST). It does not prescribe an implementation, but it names the categories of harm a guardrail stack is expected to cover.
Security & compatibility notes:
- Claude Agent SDK
bypassPermissions: This mode does NOT skip deny rules or hooks — a common misconception. Subagents inheritbypassPermissions,acceptEdits, andautomodes from their parent and cannot override per-subagent.- Llama Guard 3 vs 4: Llama Guard 3 is not deprecated. The 1B on-device variant and 8B text-only model remain maintained alongside Llama Guard 4 (the multimodal current generation).
- NeMo Guardrails repository: The repo moved to
NVIDIA-NeMo/Guardrails(org rename); oldNVIDIA/NeMo-GuardrailsURLs may redirect.
What this predicts about failure modes
Once you see guardrails as a separate decision layer, the failure modes become predictable rather than surprising.
- If you skip the input layer, expect prompt injection through tool outputs — adversarial text in a fetched webpage steers the model on the next turn.
- If you skip the output layer, expect data exfiltration through model responses — secrets, PII, or internal context bleeding into transcripts the user can copy.
- If you skip the tool layer and rely on prompt-based “please don’t do X” instructions, expect rare-but-catastrophic violations — the model is sampling, and the long tail eventually hits the action you asked it to avoid.
- If you skip the retrieval layer, expect context poisoning — a single malicious document in the vector store reshapes the agent’s behavior across many sessions.
Rule of thumb: every layer you skip turns a hard constraint into a soft preference, and soft preferences fail at scale.
When it breaks: guardrails operate on the surface of the agent’s input and output, not on its internal reasoning. A determined adversary who controls one of the agent’s data sources — a webpage, a document, a tool response — can route around output filters by chaining behavior across turns. Guardrails reduce attack surface; they do not eliminate it.
The Data Says
Agent guardrails are not a single technology but a deterministic enforcement layer that intercepts inputs, outputs, retrievals, and tool calls. The OWASP LLM06:2025 risk of Excessive Agency exists precisely because language models cannot reason about their own permissions — that judgment has to live outside the probability distribution, in code that does not negotiate.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors