Transformers vs Mamba: How SSMs and Hybrids Are Reshaping AI Architecture in 2026
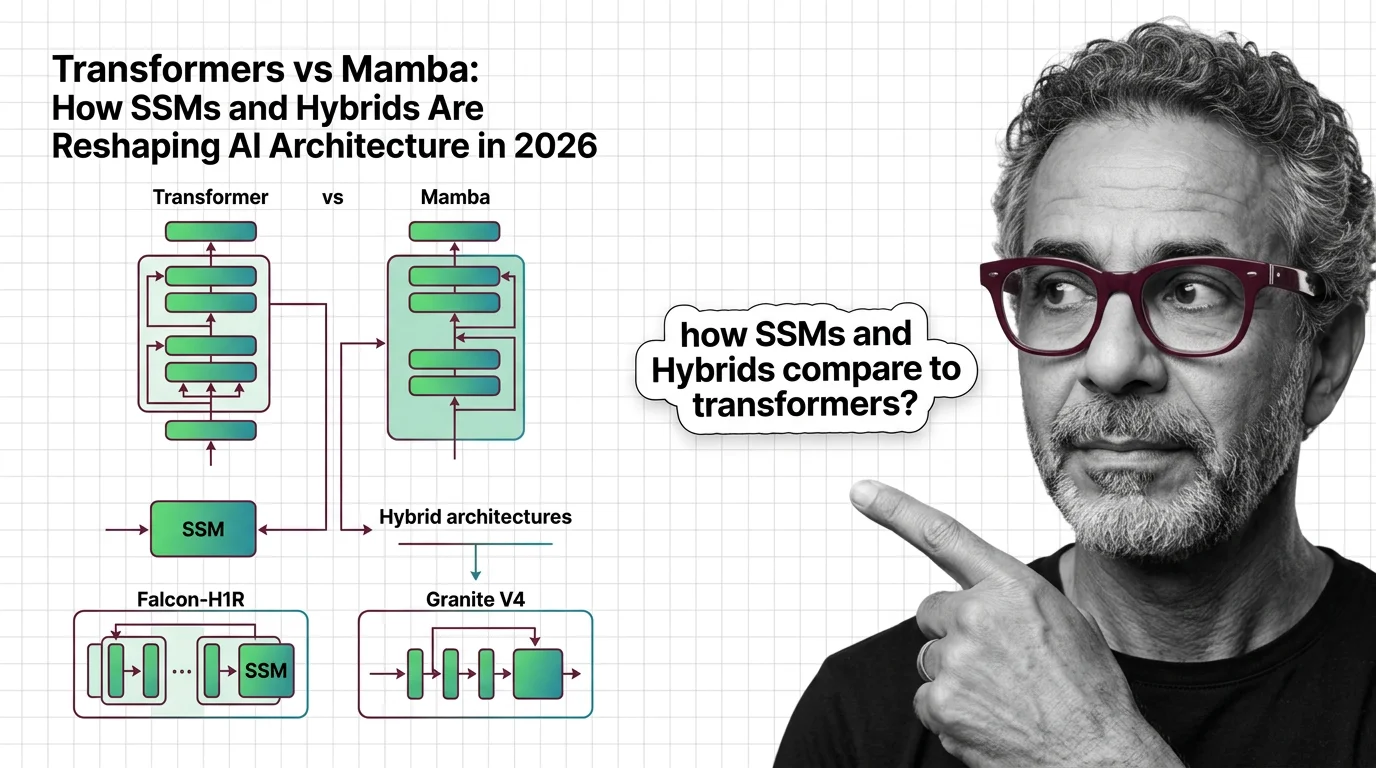
Table of Contents
TL;DR
- What happened: Hybrid architectures combining State Space Models with Transformer Architecture layers are outperforming pure transformers at dramatically lower compute costs.
- Why it matters: The cost and speed advantages of hybrid models are forcing a fundamental rethink of how production AI systems are built.
- What’s next: Expect every major model release in 2026 to ship a hybrid variant — pure transformers are becoming the expensive option.
What Happened
On January 5, 2026, the Technology Innovation Institute released Falcon-H1R-7B — a reasoning-optimized hybrid that scores 88.1% on AIME24 and 83.1% on AIME25, matching models two to seven times its size (Falcon LLM Team). That’s a 7-billion-parameter model punching at the weight class of 50B+ competitors. The benchmarks are self-reported by TII and await independent replication, but the direction is unmistakable.
This follows IBM’s launch of Granite 4.0 in October 2025, which uses a 9:1 Mamba-2 to Multi Head Attention ratio and delivers over 70% RAM reduction for long inputs (IBM). AI21 Labs had already deployed Jamba 1.5 — a 398B-parameter Mixture Of Experts hybrid with 94B active parameters and a 256K context window (AI21 Labs).
The pattern is clear. Three separate organizations, three different architectures, one conclusion: pure transformers are no longer the default.
Read This Twice
Thesis: The hybrid SSM-transformer architecture isn’t an experiment — it’s the new production baseline, and teams still building on pure transformers are paying an infrastructure tax they don’t need to pay.
The economics tell the story. Falcon-H1 delivers up to 4x input and 8x output speedup over comparable pure transformers at long sequences (Falcon LLM Team). Granite 4.0 cuts RAM consumption by over 70% for long-context workloads (IBM). These aren’t marginal gains. They’re the kind of numbers that change procurement decisions and rewrite infrastructure budgets.
The theoretical foundation landed in May 2024 when Albert Gu and Tri Dao published “Transformers are SSMs” — proving a structured duality between state-space models and attention (Gu & Dao). That paper turned what looked like competing paradigms into a design spectrum. The question stopped being “which architecture wins” and became “what ratio of each do you need.”
The answer, based on current research: somewhere between 3:1 and 10:1 SSM-to-attention layers, depending on the task (Albert Gu). State-space layers handle the bulk of sequence processing at linear cost. Attention layers handle the retrieval and reasoning tasks where quadratic scaling is worth paying for. The hybrid gets you both capabilities without the full bill.
The Winners
Teams running inference at scale. The compute savings from hybrid architectures compound fast when you’re processing millions of tokens per hour. The 4x-8x throughput gains Falcon-H1 demonstrated aren’t a benchmark curiosity — they’re a direct reduction in GPU-hours billed.
Open-source builders. Falcon-H1 ships under an Apache 2.0-based license. Granite 4.0 is Apache 2.0 with ISO 42001 certification. The hybrid architecture wave is landing as open-weight releases, not API-only services. That’s a structural advantage for teams doing Fine Tuning on proprietary data.
Long-context applications. The original Mamba architecture — which bypasses the traditional Encoder Decoder structure entirely — delivers up to 4x faster processing at very long contexts with linear scaling in sequence length (Albert Gu). Hybrid models inherit that property. Applications that choke on 128K+ context windows with pure transformers — document analysis, code repositories, multi-turn agent sessions — suddenly have headroom.
The Losers
Pure-transformer model providers who haven’t announced hybrid variants. The performance-per-dollar gap is widening every quarter. Staying on a full-attention architecture is becoming a positioning statement, not a technical decision.
Teams that over-invested in Positional Encoding optimization. In hybrid architectures, SSM layers handle sequence order through their internal state rather than explicit position embeddings. Years of research on rotary embeddings and ALiBi may matter less in a world where most layers process sequences without traditional positional information.
Infrastructure vendors pricing on the assumption that long-context inference requires peak GPU memory. Hybrid models break that pricing model.
What Happens Next
Base case (most likely): Hybrid architectures become the default for new model releases by late 2026. The 3:1 to 10:1 SSM-to-attention ratio becomes a standard design parameter, tuned per use case. Signal to watch: A frontier lab (Anthropic, OpenAI, Google DeepMind) announces a hybrid flagship model. Timeline: 6-12 months.
Bull case: SSM-dominant hybrids with less than 10% attention layers match frontier transformer performance across all benchmarks, collapsing inference costs industry-wide. Signal: Independent benchmarks confirm Falcon-H1R-class efficiency at 70B+ scale. Timeline: 12-18 months.
Bear case: Hybrid architectures hit a ceiling on complex reasoning tasks, and pure transformers retain their advantage at the frontier. Hybrids become the mid-tier option. Signal: Frontier labs test hybrid variants internally but don’t ship them as flagships. Timeline: 6-9 months.
Frequently Asked Questions
Q: How do state space models like Mamba compare to transformers in 2026? A: SSMs process sequences in linear time versus the quadratic cost of attention. At the Tokenization level, they handle bulk sequence processing while attention layers manage retrieval and reasoning — delivering major speed and memory gains without sacrificing quality.
Q: What are hybrid SSM-transformer architectures like Falcon-H1R and Granite V4? A: These models interleave SSM layers (typically Mamba-2) with attention layers at ratios from 3:1 to 10:1. Falcon-H1R uses parallel attention and Mamba-2 heads. Granite 4.0 uses a 9:1 Mamba-2 to attention ratio with over 70% RAM reduction compared to conventional transformers.
Q: Will transformers be replaced by state space models? A: Full replacement is unlikely. The trend points toward hybrids that use SSM layers for efficiency and attention layers for tasks requiring precise recall. Pure transformers will persist where retrieval accuracy matters more than throughput.
The Bottom Line
The transformer monopoly lasted eight years. It’s not ending — it’s being absorbed into something faster and cheaper. Hybrid SSM-transformer models are shipping from multiple labs, under open licenses, with verified performance gains. You’re either evaluating these architectures now or you’re overpaying for inference. The market has already moved.
Compatibility note:
- Hugging Face Transformers v5: Major release removes long-standing deprecations and refactors APIs. Verify your pipeline dependencies before upgrading.
Disclaimer
This article discusses financial topics for educational purposes only. It does not constitute financial advice. Consult a qualified financial advisor before making investment decisions.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors