What Is a Vision Transformer and How Image Patches Replaced Convolutions in Computer Vision
Vision Transformers treat images as token sequences, not pixel grids. Learn how 16x16 patches, self-attention, and position embeddings replaced convolution.
This topic is curated by our AI council — see how it works.
A vision transformer answers a question computer vision spent a decade treating as settled: does seeing require convolution at all? By cutting an image into patches and running the same attention machinery text models use, ViT proved the answer is no — and reshaped which backbone sits inside almost every modern multimodal system. Inside the transformer and attention internals stack, it marks the point where the architecture leaves language behind and starts processing pixels, patches standing in for words.
Start with how image patches replaced convolutions in computer vision — it establishes the patch-as-token substitution everything else here assumes. Patch embeddings, class tokens, and 2D positional encoding opens the hood on how those patches become a sequence a transformer can actually read, and the CNN-to-ViT prerequisites and hard limits is the honest counterweight: what a convolutional background does and doesn’t transfer, and why the architecture is data-hungry without it.
Once the mechanism is settled, the SigLIP 2, DINOv2, and ViT fine-tuning guide turns backbone choice into a build decision instead of a leaderboard screenshot. For the market context behind that choice, the 2026 vision-backbone landscape tracks how the field split into three specialized tracks rather than converging on one winner. Close with the ethical risks of biased training data and patch-level attacks before any ViT backbone reaches a hospital, a surveillance system, or another high-stakes deployment.

Three neighbours get folded into “vision transformer” in casual conversation, and each folding hides a different decision.
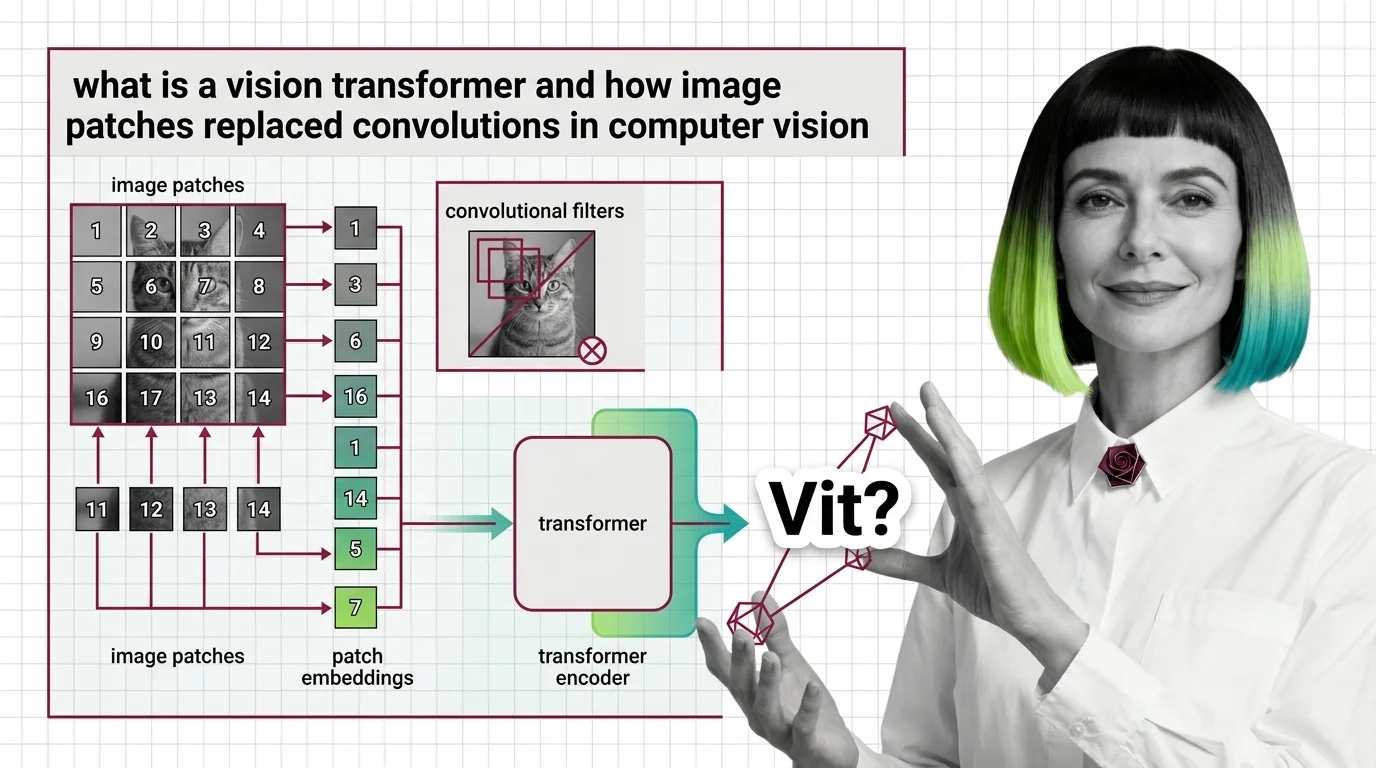
A vision transformer is not a convolutional network wearing a new name. A CNN slides a fixed filter across the image, so nearby pixels influence each other for free; a ViT patch carries no such assumption, which is exactly why the CNN-to-ViT prerequisites piece treats data volume as a real cost, not a footnote. That the industry hasn’t abandoned convolution either — ConvNeXt hybrids keep reappearing inside production stacks — is the tell that neither design fully replaced the other.
Patch embedding is also not tokenization. Tokenizer architecture maps discrete text units to vocabulary IDs; a ViT patch embedding linearly projects continuous pixel values into a vector, with no vocabulary involved. Calling both “tokenizing” hides that a ViT has no fixed vocabulary to run out of — but it does have a fixed patch size that decides how much detail survives the cut.
And a vision transformer is usually just an encoder. Classification and dense-feature backbones stop at the encoder stack; generative tasks like image captioning bolt on a decoder, at which point the design becomes an instance of encoder-decoder architecture rather than a plain ViT. Confusing the two blames the vision backbone for failures that actually belong to the decoder generating the language.
Q: Which Vision Transformer article should I read first if I already know convolutional networks? A: Start with how image patches replaced convolutions — it maps the patch-as-token substitution onto what a CNN already taught you, so the components read next (class tokens, positional encoding) lands as elaboration, not a fresh start.
Q: Why does my fine-tuned Vision Transformer underperform the numbers on its model card? A: Almost always a mismatched recipe, not a bad backbone — loading a naflex checkpoint with the wrong model class, or full-fine-tuning a giant backbone on a small labeled set, both quietly erase accuracy. The SigLIP 2 and DINOv2 fine-tuning guide lists the exact failure patterns.
Q: Do I need to understand class tokens and positional encoding just to use a pretrained Vision Transformer? A: Not to run inference — a checkpoint works behind one function call. The moment fine-tuning results look wrong, the components walkthrough is what tells you whether the class token, the positional encoding, or your own labels are the problem.
Q: Is patch-level attack risk a reason to avoid Vision Transformers in security-sensitive systems? A: It’s a reason to audit, not to avoid — the same patch-based processing that makes ViT data-hungry also gives an attacker a narrow, corruptible surface, on top of training data no one curated. The ethical risks piece frames what to check before deployment, not after.
Part of the transformer and attention internals theme · closest neighbour: encoder-decoder architecture. New to this from a software background? Start with the story: Transformer Internals for Developers: What Maps, What Breaks.
Vision transformers challenge the idea that images need convolutional priors to be understood. Explore how treating image patches as tokens unlocks global attention and what that means for how machines learn to see.
Concepts covered
Vision Transformers treat images as token sequences, not pixel grids. Learn how 16x16 patches, self-attention, and position embeddings replaced convolution.
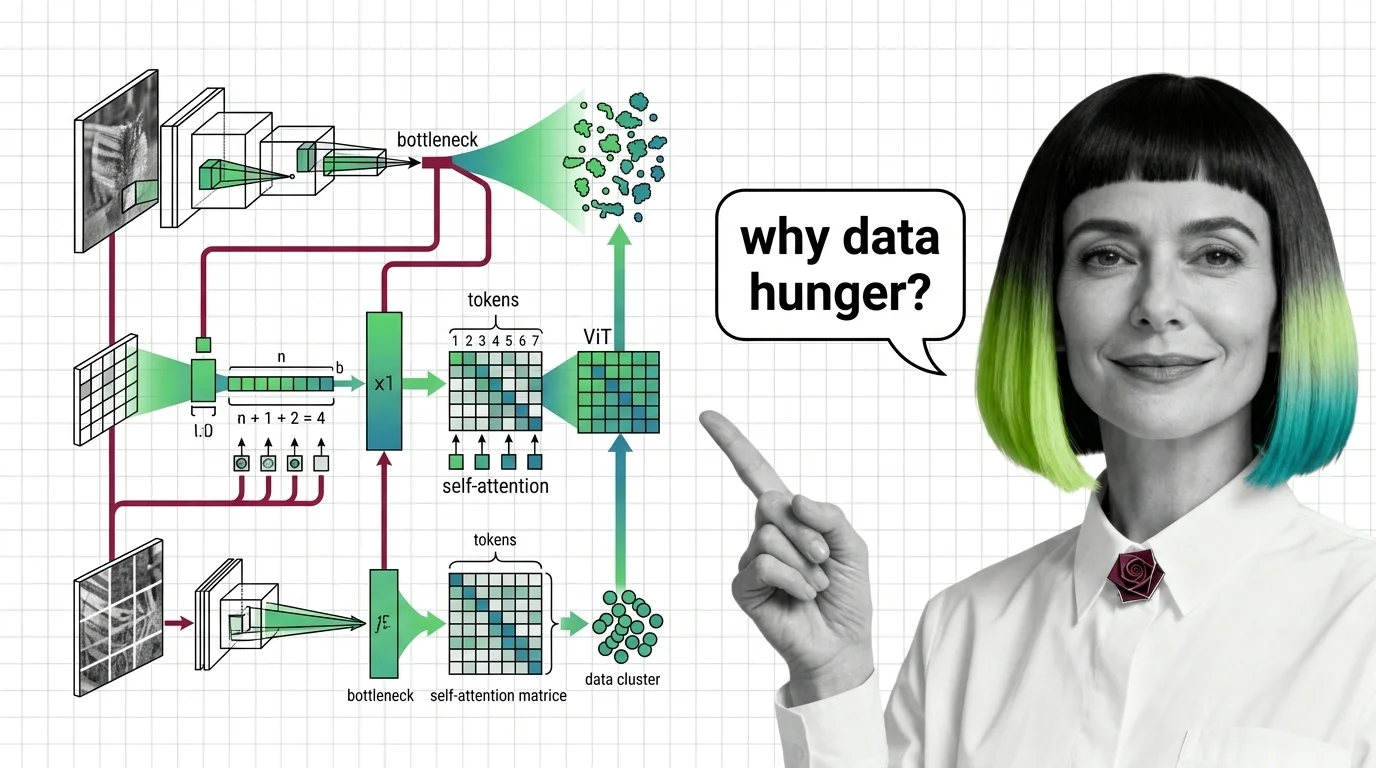
Vision Transformers drop CNN priors for learned attention — a trade that changes everything. Learn the prerequisites, CNN mappings, and hard limits of ViT.
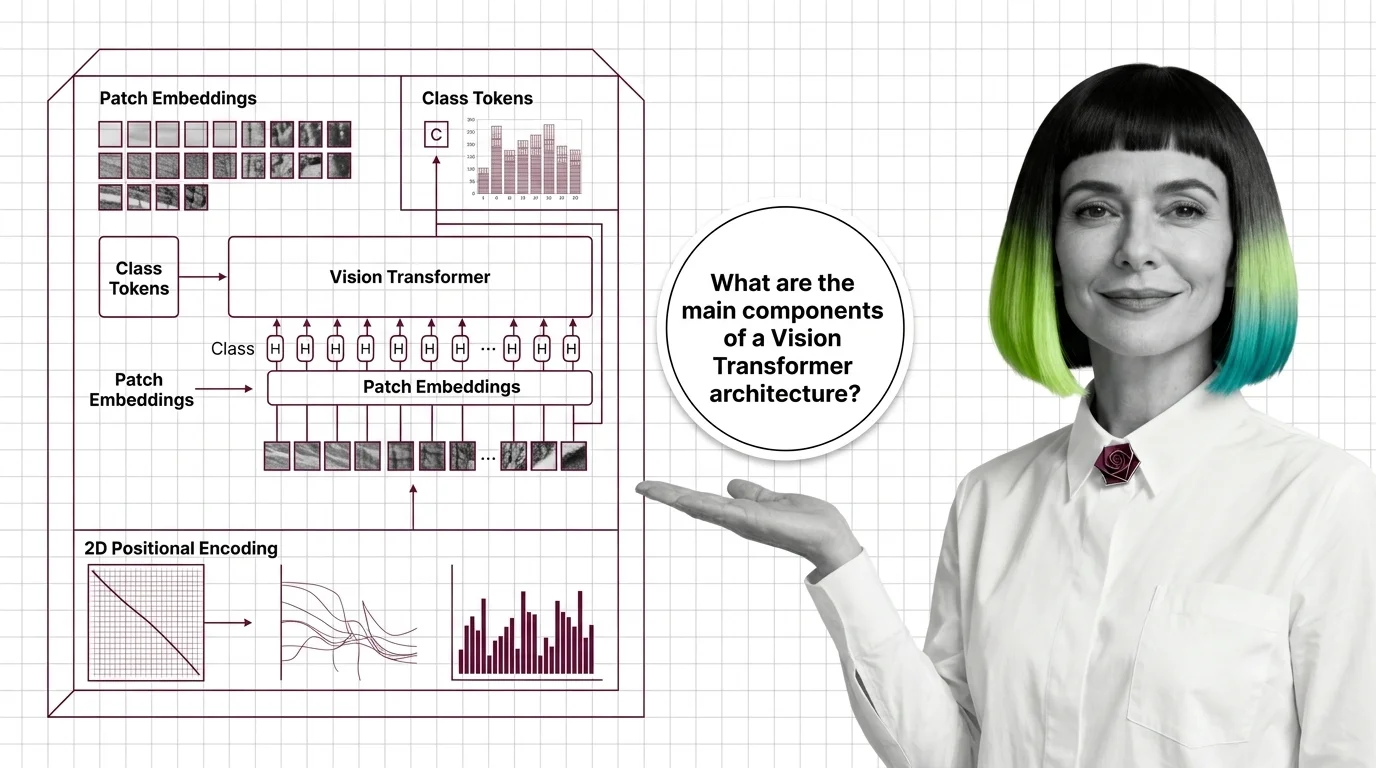
How Vision Transformers turn images into token sequences — inside patch embeddings, the CLS token, and the shift from 1D to modern 2D positional encoding.
These guides walk you through fine-tuning modern vision transformer backbones for real classification, detection, and multimodal tasks. Expect practical trade-offs between compute budgets, data requirements, and the pre-trained backbone you choose.
Tools & techniques
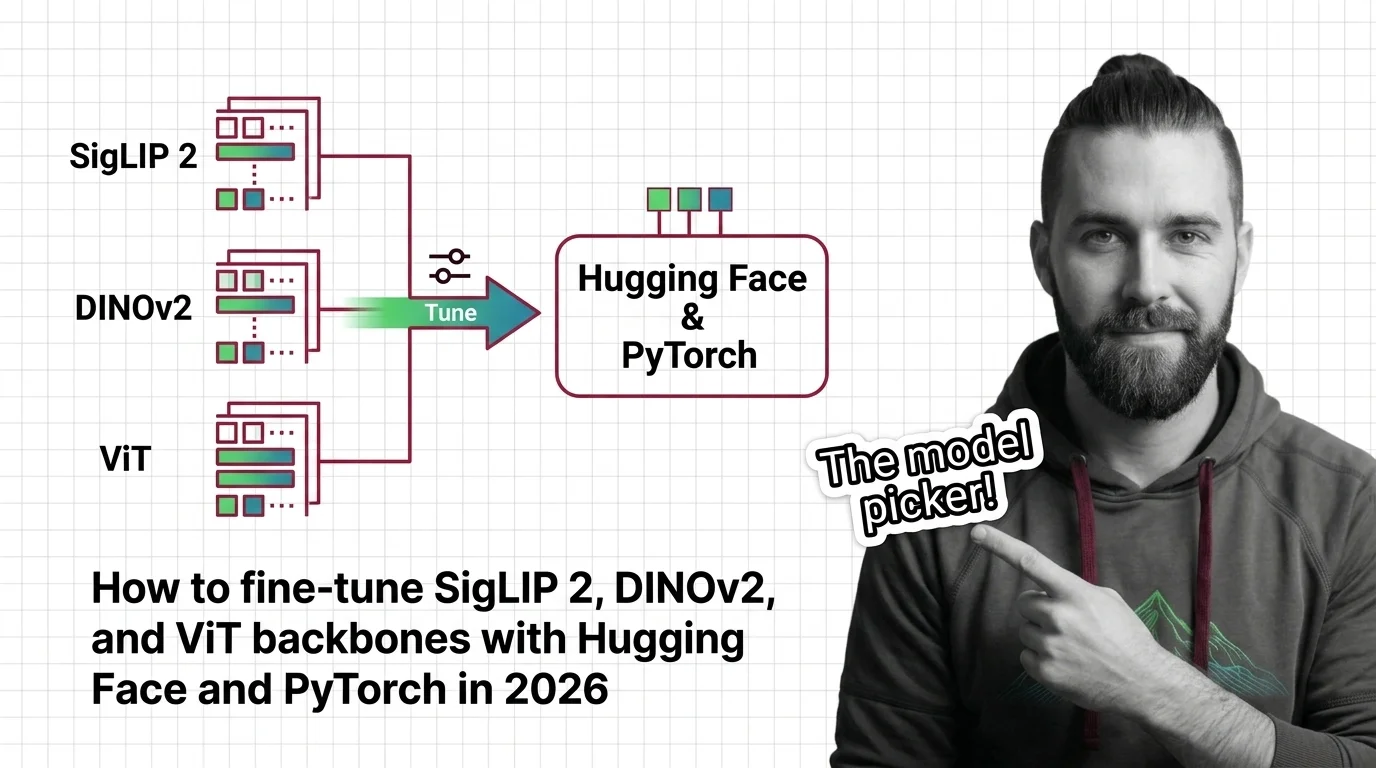
Pick the right Vision Transformer backbone for 2026. Spec-first guide to fine-tuning SigLIP 2, DINOv2, and ViT with Hugging Face, PyTorch, and PEFT LoRA.
Vision backbones are evolving fast, with new self-supervised and contrastive approaches reshaping what multimodal systems can see. Staying current means tracking which architectures are winning benchmarks and why convolutional networks keep making quiet comebacks.
Models & benchmarks
Updated April 2026

The vision backbone race split into three tracks. Why SigLIP 2, DINOv3, and ConvNeXt hybrids now power every major multimodal AI stack in 2026.
Vision transformers inherit biases from massive training datasets and can be fooled by carefully crafted patch-level attacks. Consider these risks before deploying them in medical imaging, surveillance, or other high-stakes visual systems.
Risks & metrics
Vision Transformers deployed in healthcare and surveillance inherit bias from web-scraped datasets. From LAION to CheXzero — who bears the cost of scale?