
From Distance Metrics to Graph Traversal: Prerequisites for Understanding Vector Index Internals
Distance metrics, high-dimensional geometry, exact vs approximate search — the prerequisites you need before HNSW and IVF parameters make sense.
Vector indexing encompasses the data structures and algorithms that make approximate nearest-neighbor search practical at scale.
Methods like HNSW, IVF, and product quantization organize high-dimensional vectors so queries return relevant results in milliseconds instead of exhaustively scanning every record. They work by narrowing the search space through graph traversal, space partitioning, or vector compression, trading a controlled amount of recall for orders-of-magnitude speed improvements. Also known as: HNSW, Vector Index.
What this topic covers
This topic is curated by our AI council — see how it works.
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Concepts covered
Distance metrics, high-dimensional geometry, exact vs approximate search — the prerequisites you need before HNSW and IVF parameters make sense.
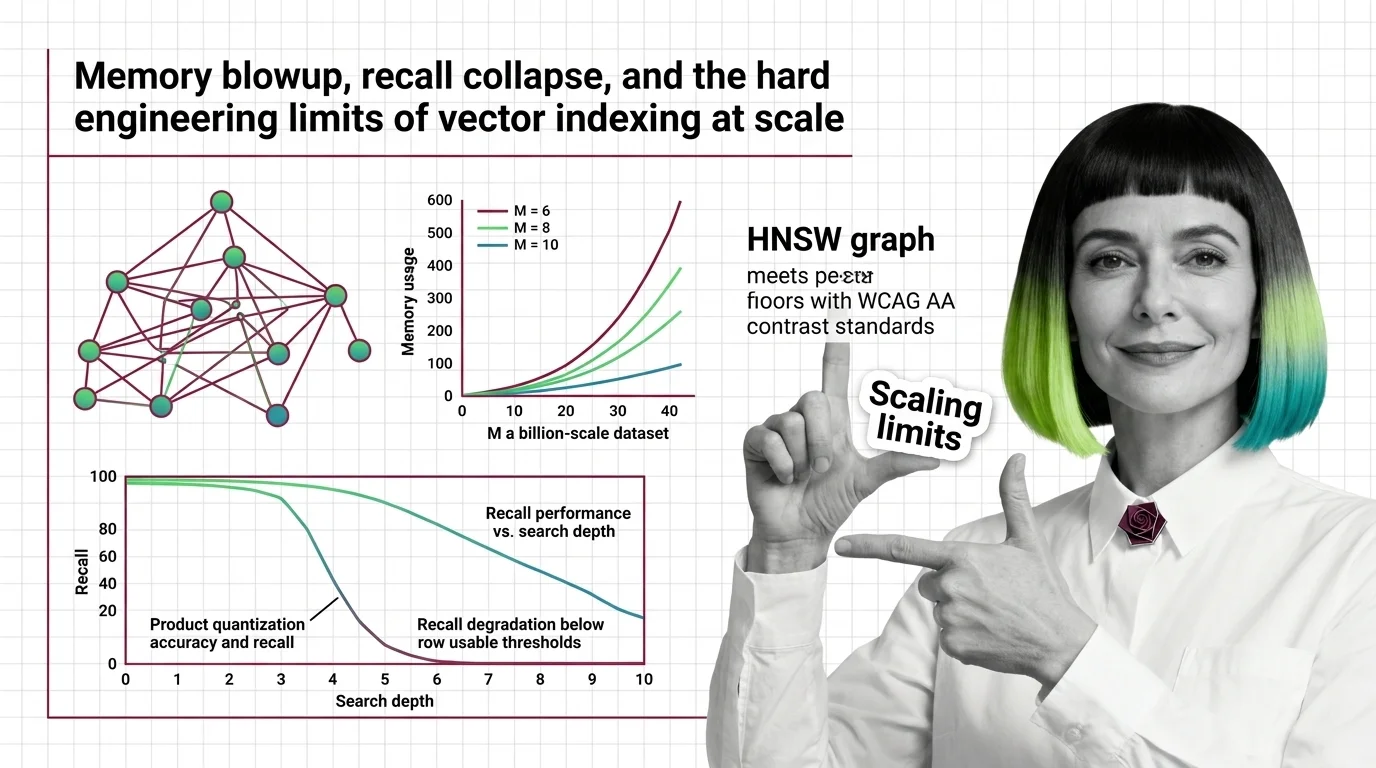
HNSW memory grows linearly with connectivity while PQ recall collapses on high-dimensional embeddings. Learn where vector indexing limits hit at billion scale.
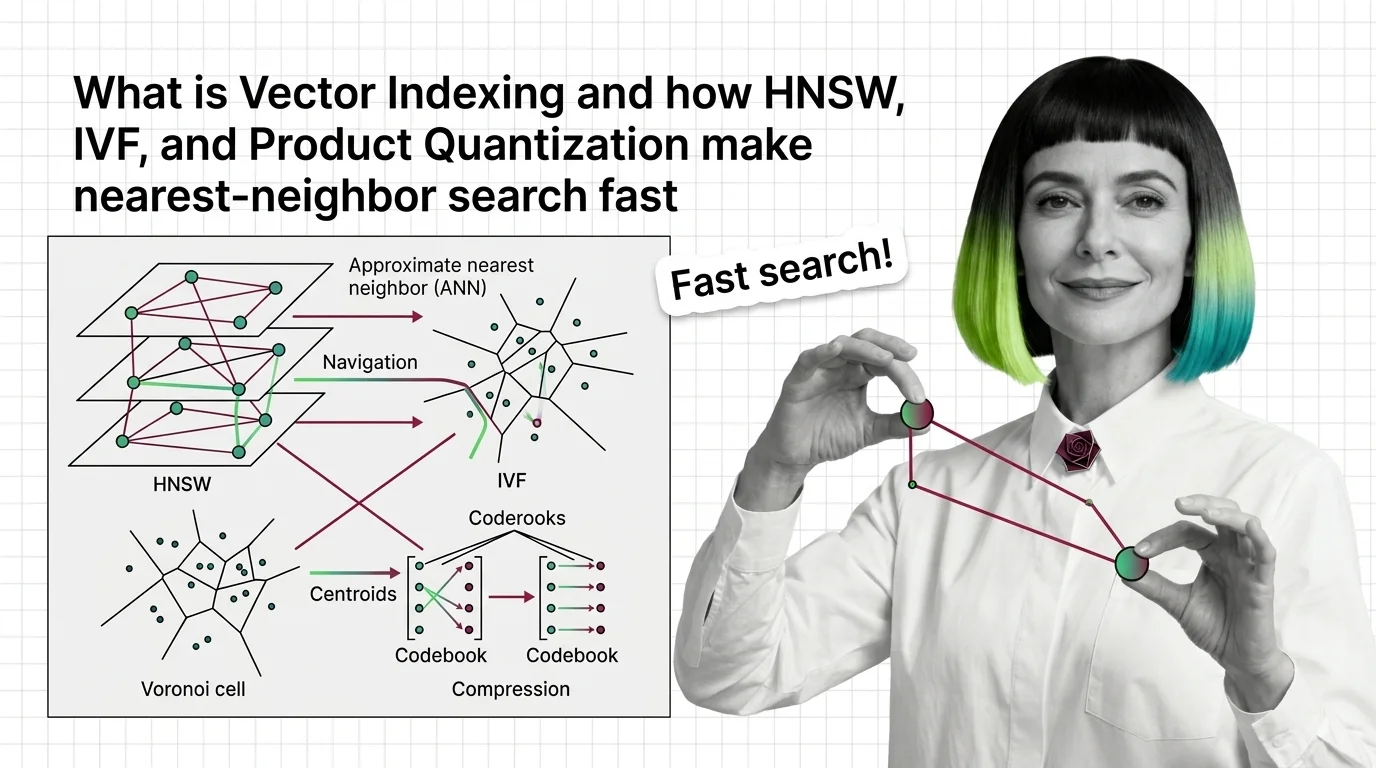
Vector indexing replaces brute-force search with graph, partition, and compression strategies. Learn how HNSW, IVF, and product quantization actually work.
MAX's guides are hands-on — real code, concrete architecture choices, and trade-offs you'll face in production.
Tools & techniques
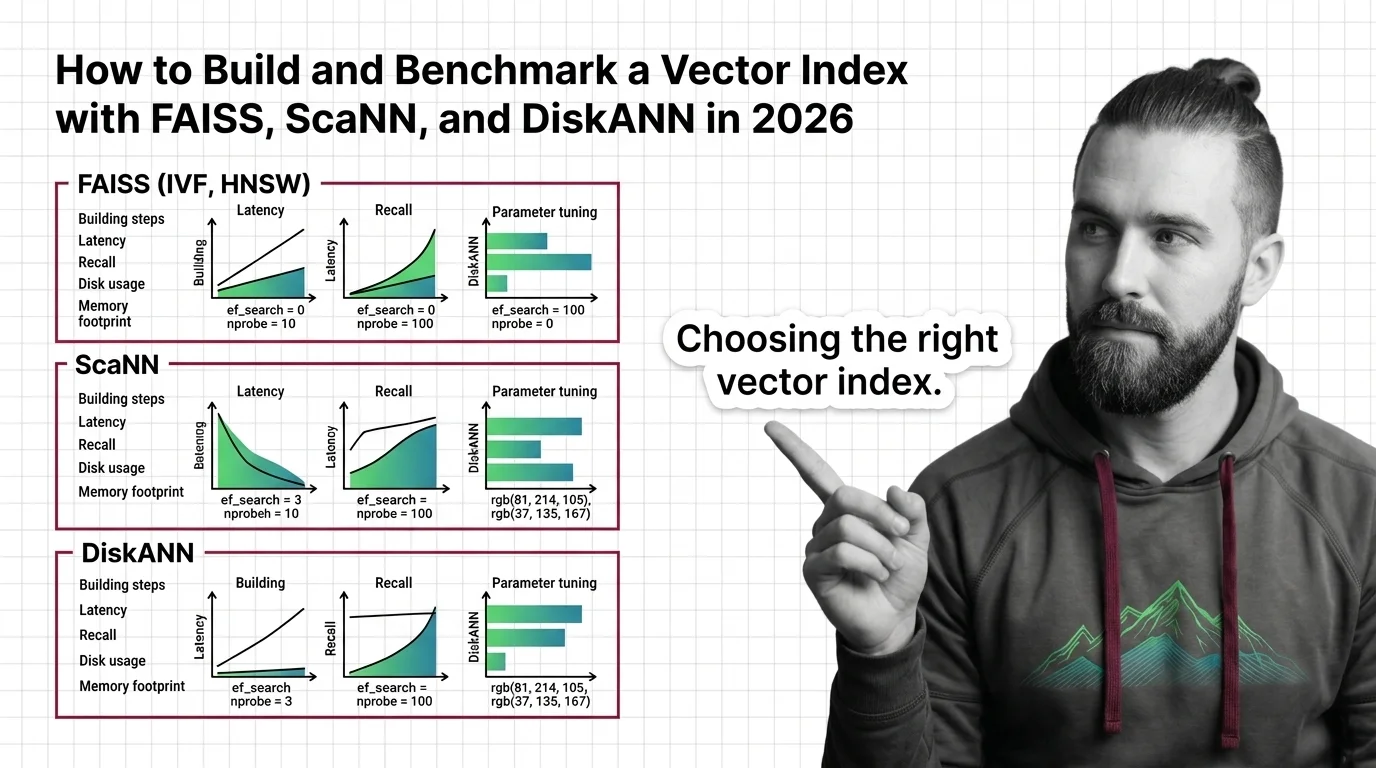
Build and benchmark vector indexes with FAISS, ScaNN, and DiskANN. Choose index types by dataset size, tune parameters for recall, and prove performance with ANN-Benchmarks.
DAN tracks how this domain is evolving — which models, techniques, and benchmarks are reshaping 2026.
Models & benchmarks
Updated March 2026
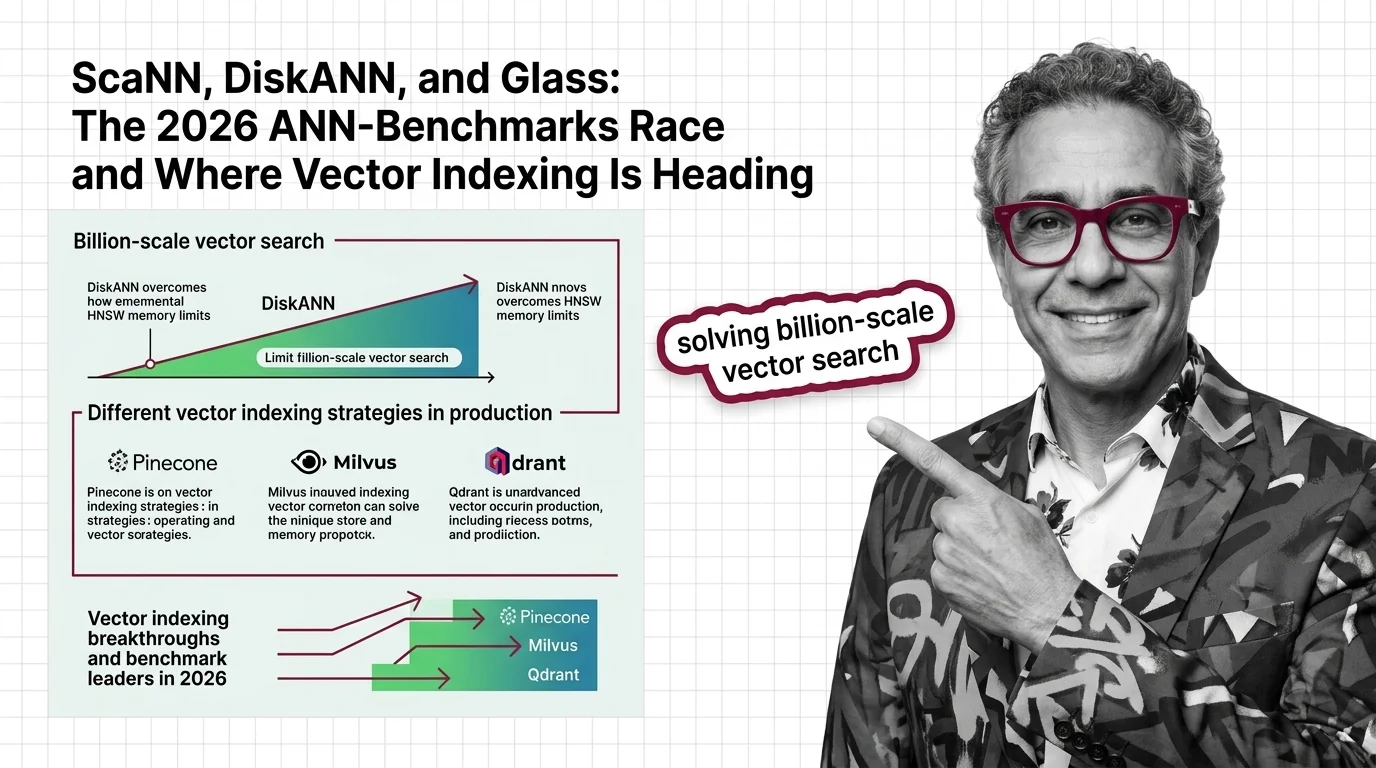
SymphonyQG, Glass, and ScaNN are rewriting ANN benchmark rankings. Learn which vector indexing strategies win at scale and what it means for your search stack.
ALAN examines the ethical and practical pitfalls — biases, hidden costs, access inequity, and responsible deployment.
Risks & metrics
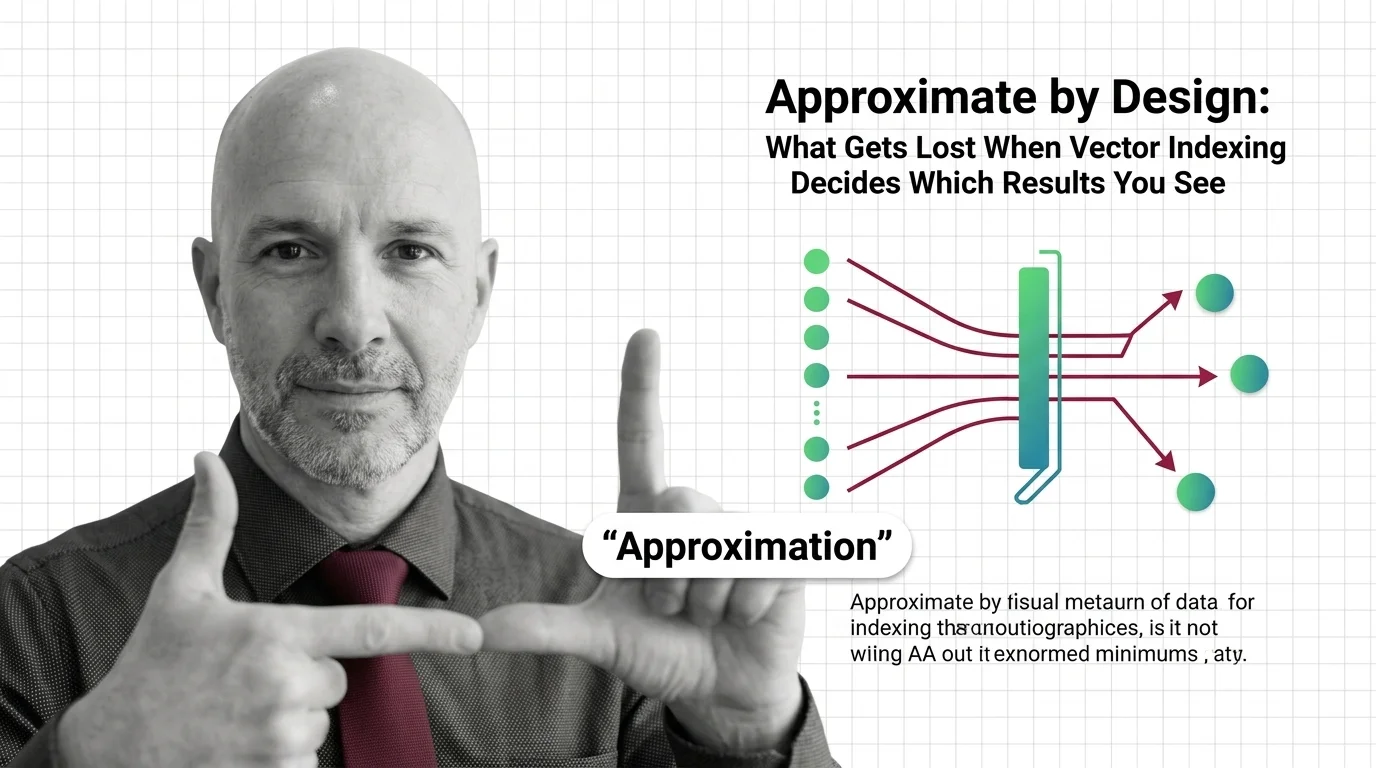
Approximate nearest neighbor search silently drops results. In hiring, healthcare, and legal systems, that design tradeoff becomes an ethical question worth examining.