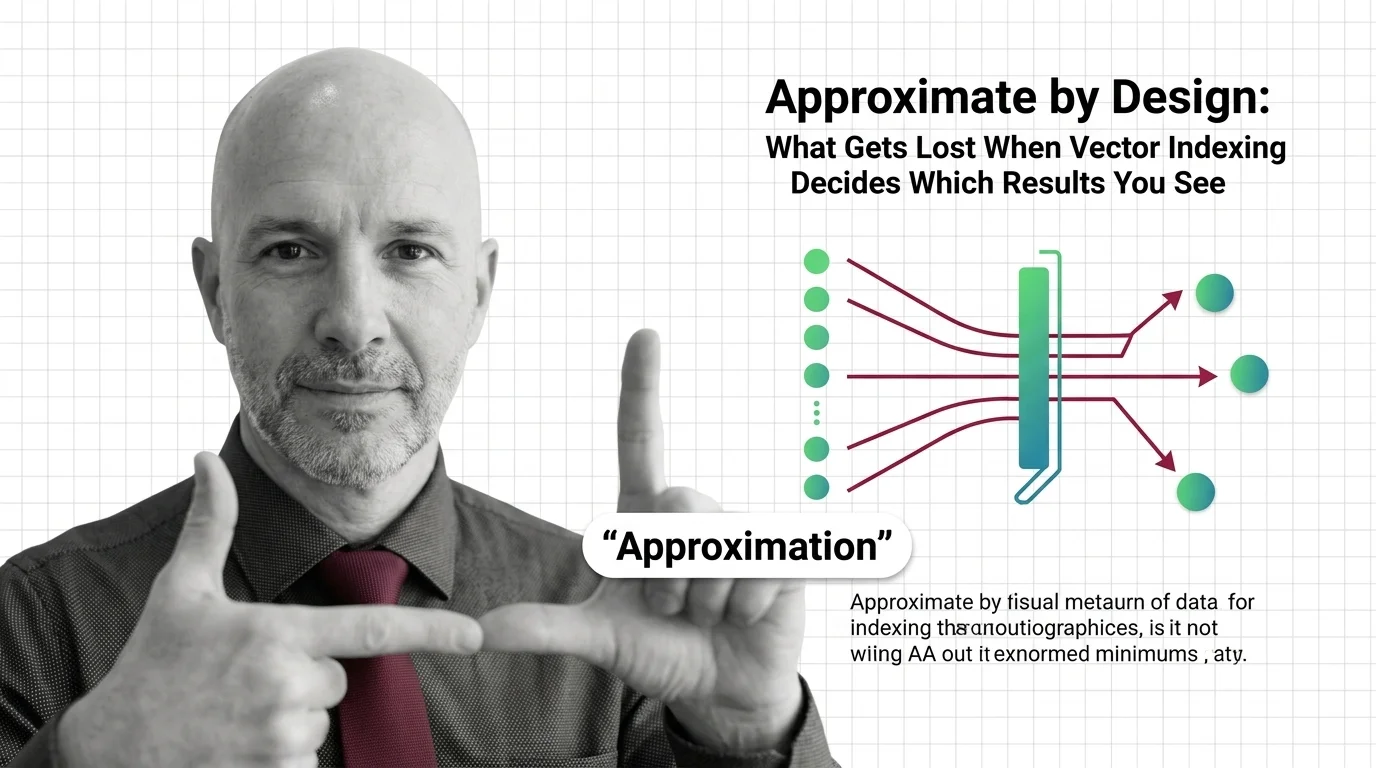
Vector Indexing
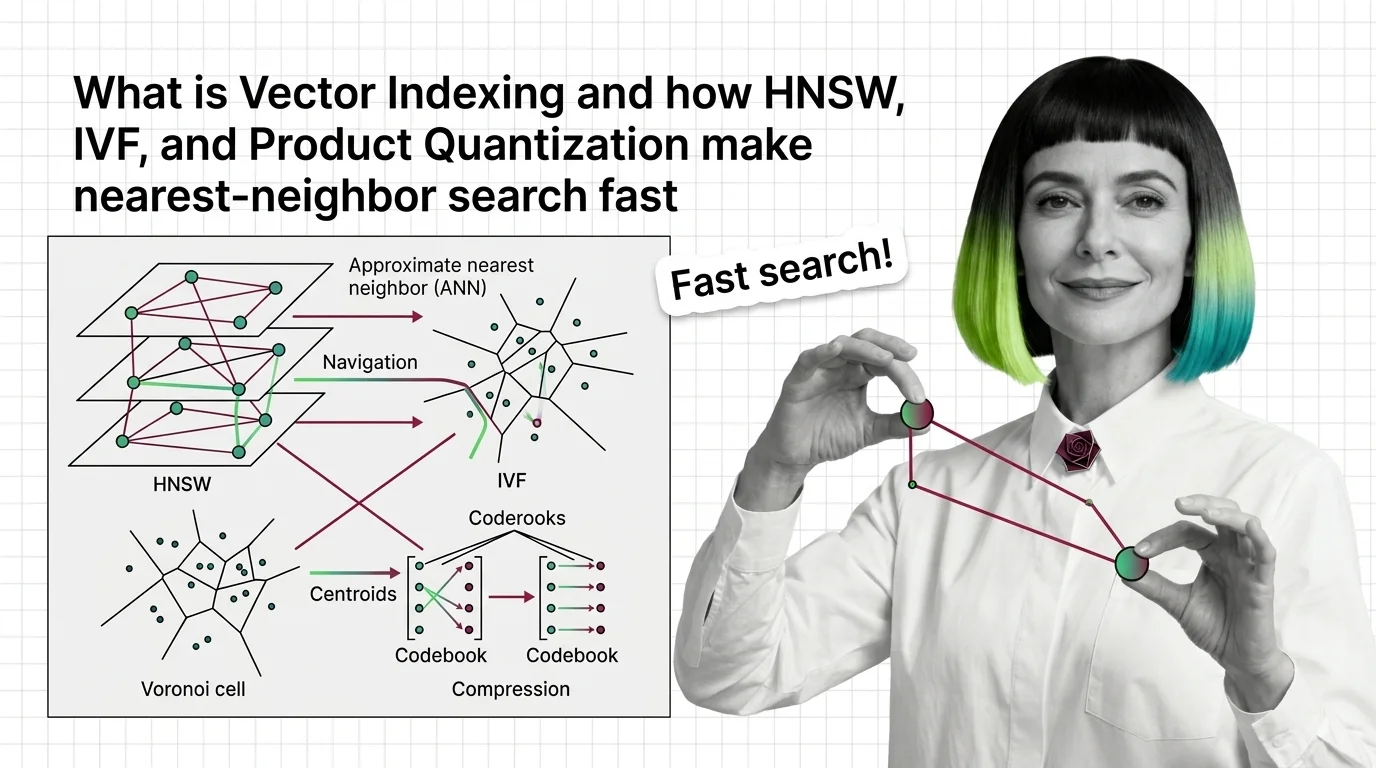
Vector indexing encompasses the data structures and algorithms that make approximate nearest-neighbor search practical at scale. Methods like HNSW, IVF, and product quantization organize high-dimensional vectors so queries return relevant results in milliseconds instead of exhaustively scanning every record. They work by narrowing the search space through graph traversal, space partitioning, or vector compression, trading a controlled amount of recall for orders-of-magnitude speed improvements. Also known as: HNSW, Vector Index.
Understand the Fundamentals
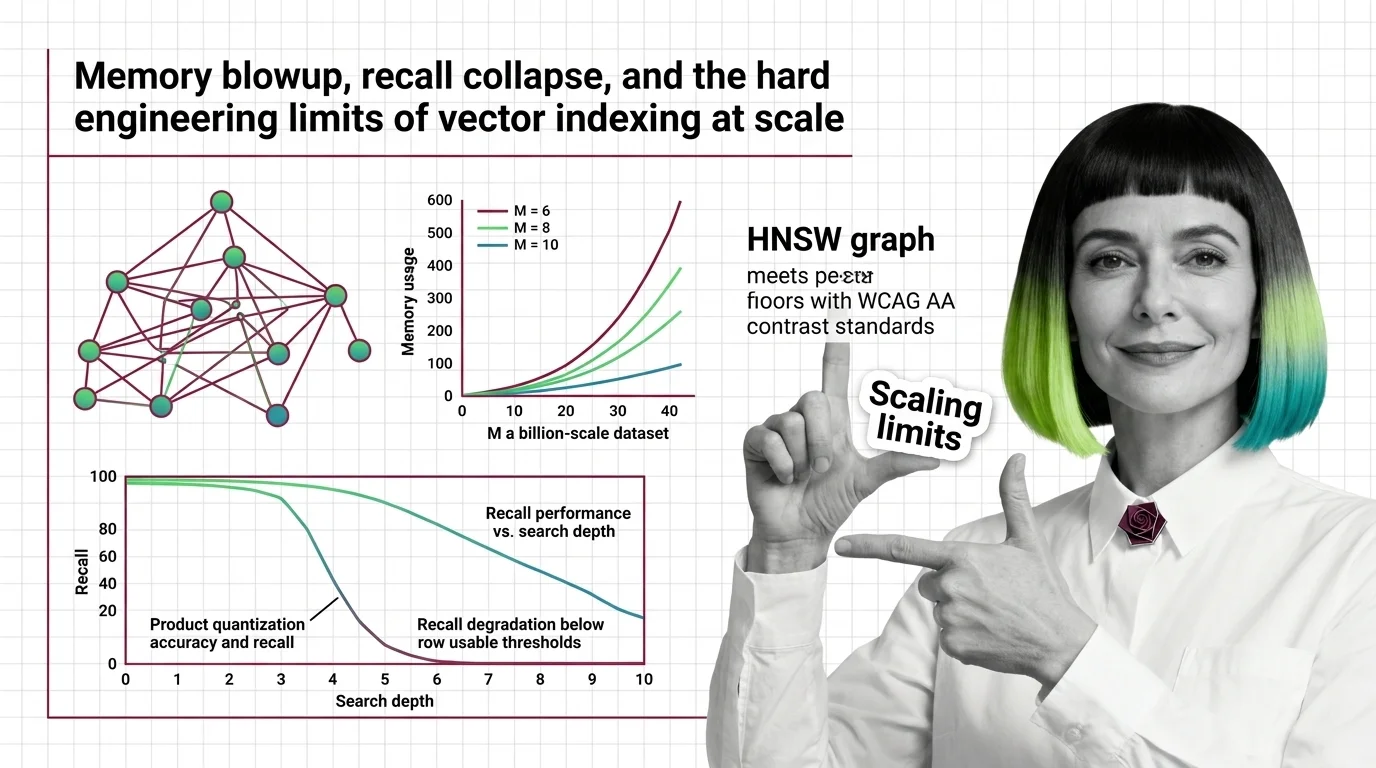
Vector indexing solves a deceptively hard problem: searching billions of high-dimensional vectors in milliseconds. Understanding how graph-based and partition-based methods achieve this reveals fundamental trade-offs between recall, speed, and memory.

Build with Vector Indexing
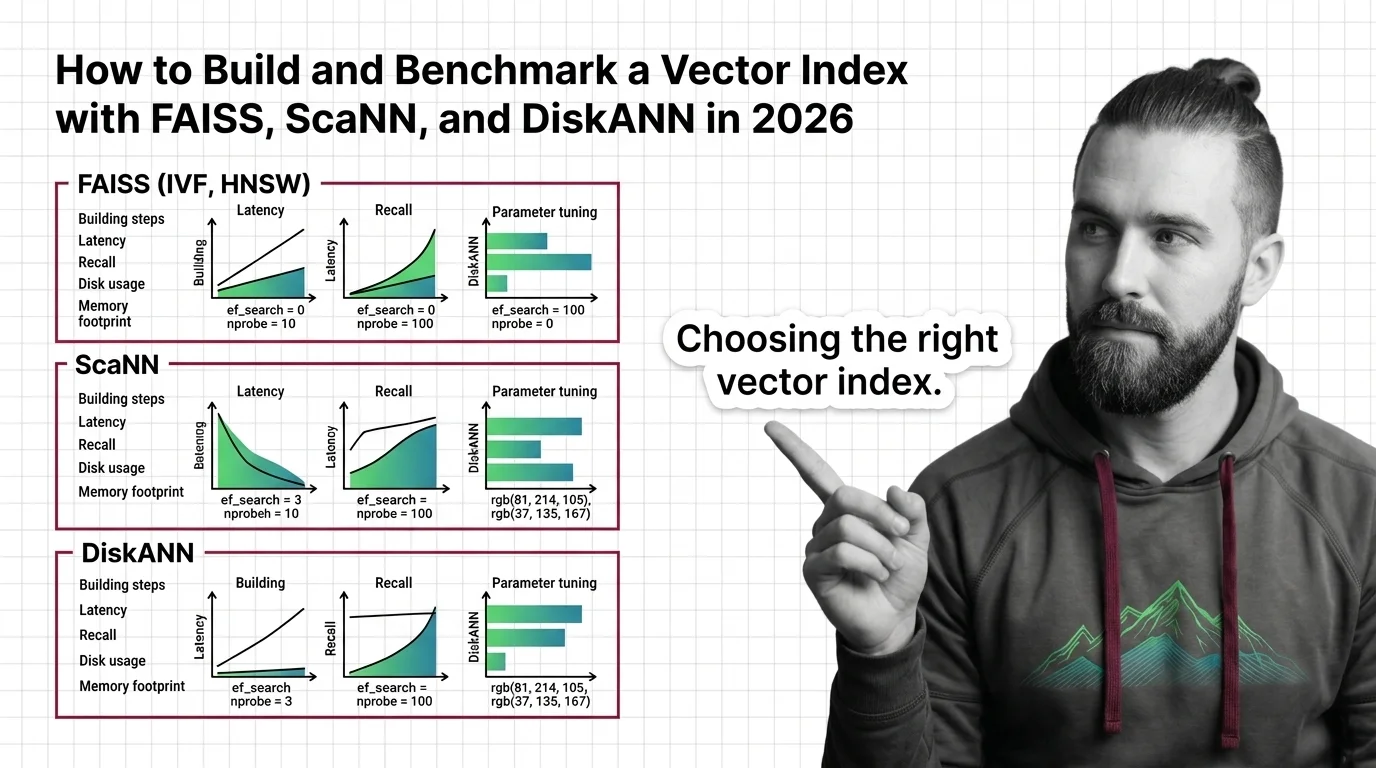
The practical guides walk you through choosing, building, and benchmarking vector indexes, covering the real configuration decisions and performance trade-offs that documentation alone never makes clear.
What's Changing in 2026
The approximate nearest-neighbor landscape shifts every benchmark cycle. Following which index algorithms gain ground and why matters for anyone building retrieval systems that need to scale.
Updated March 2026
Risks and Considerations
Every vector index is approximate by design, which means some relevant results are silently dropped. Before deploying, consider what recall loss means for your users and whether the trade-off is acceptable.