Variational Autoencoder
A Variational Autoencoder (VAE) is a generative neural network that encodes input data into a continuous, structured latent space and decodes samples from that space into realistic outputs. Unlike standard autoencoders, VAEs impose a probabilistic prior on latent variables, enabling smooth interpolation and novel data generation. They serve as the image compression backbone in latent diffusion models, mapping between pixel space and a lower-dimensional representation where denoising occurs. Also known as: VAE, Autoencoder.
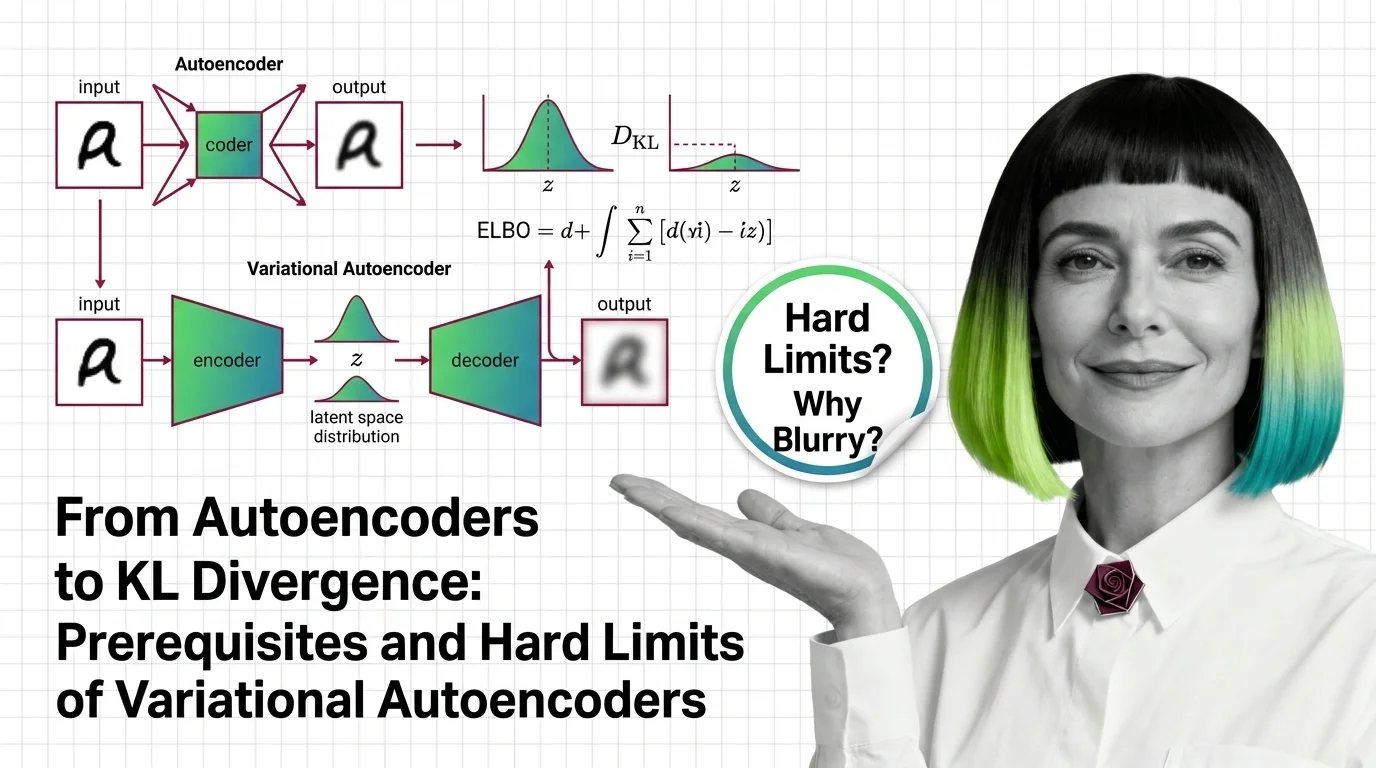
Understand the Fundamentals
Variational Autoencoders bridge the gap between dimensionality reduction and generative modeling. Understanding how a probabilistic latent space differs from a deterministic bottleneck reveals why VAEs can create, not just compress.
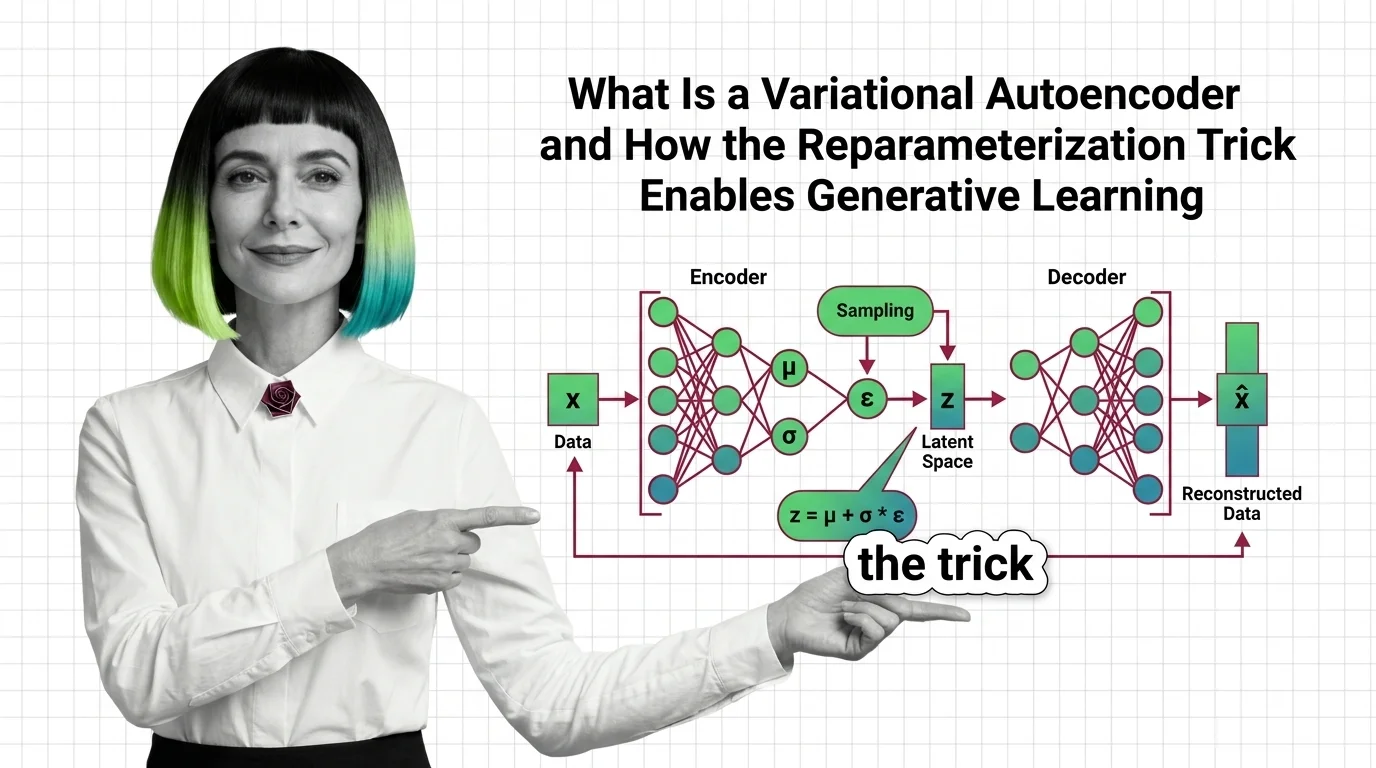
Build with Variational Autoencoder
These guides walk you through implementing VAEs from scratch, tuning the KL divergence trade-off, and applying the architecture to real problems like anomaly detection and data augmentation.

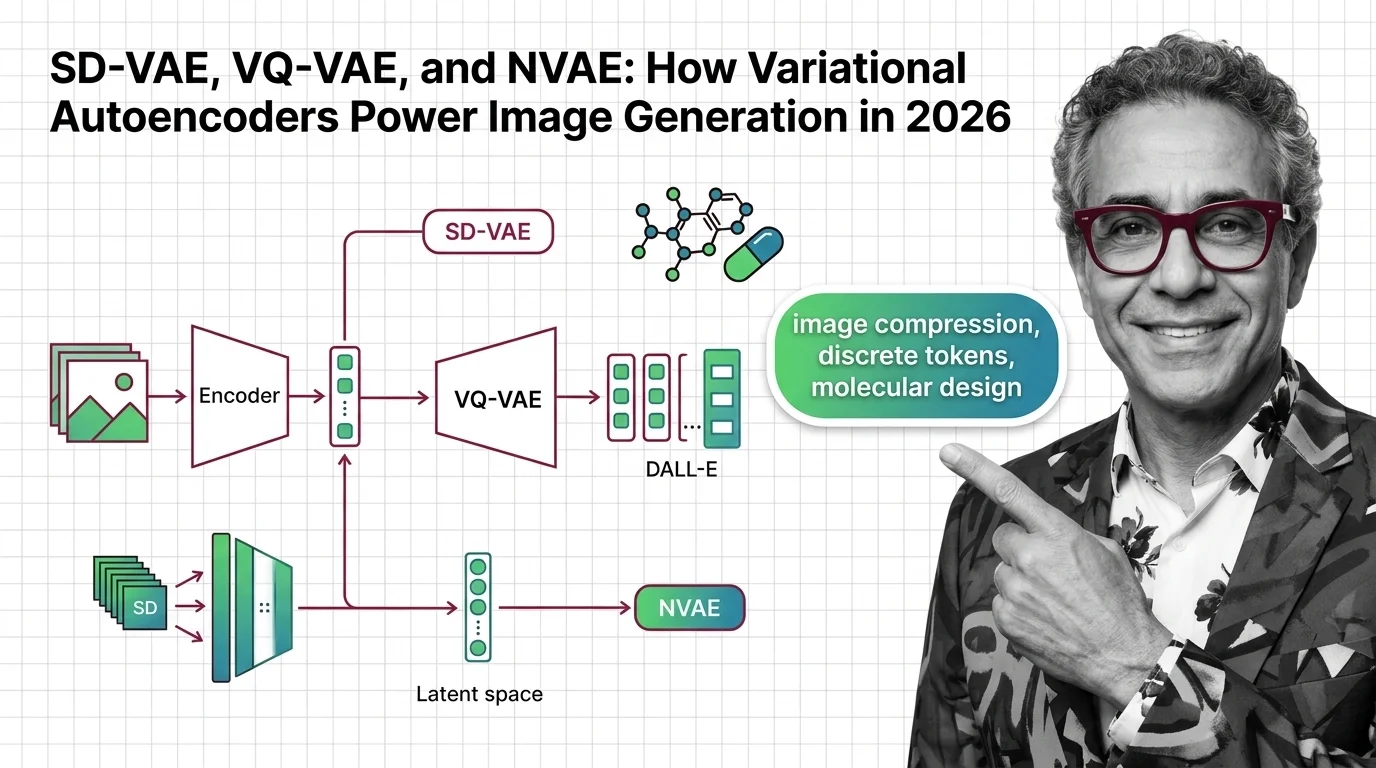
What's Changing in 2026
Variational Autoencoders keep evolving as researchers push latent space design into new domains. Staying current matters because VAE variants now underpin some of the most visible advances in image and video generation.
Updated April 2026
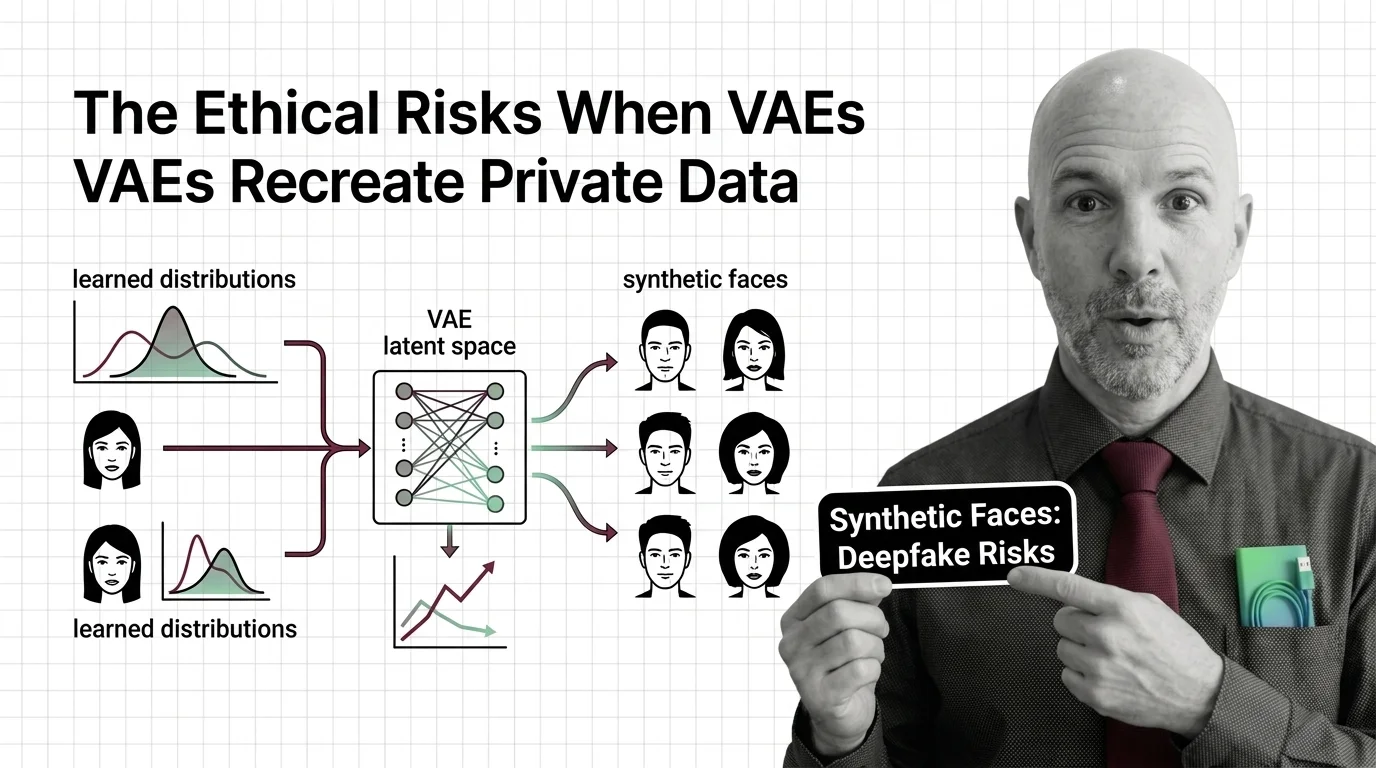
Risks and Considerations
When a Variational Autoencoder learns from sensitive data, its latent space can encode and reproduce private information. Consider the ethical boundaries of generation before training on personal or biometric datasets.