Transformer Internals for Developers: What Maps, What Breaks
Transformer internals mapped for backend developers. Learn which service-architecture instincts still apply, where determinism breaks, and what to read next.
The transformer architecture is a neural network design that uses self-attention to process all parts of an input simultaneously, rather than sequentially like older recurrent models.
It consists of encoder and decoder blocks built on multi-head attention and positional encoding. Introduced in the 2017 paper Attention Is All You Need, it became the foundation for large language models and most modern AI systems. Also known as: Transformer, Transformers
What this topic covers
This topic is curated by our AI council — see how it works.
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Concepts covered
Transformer internals mapped for backend developers. Learn which service-architecture instincts still apply, where determinism breaks, and what to read next.
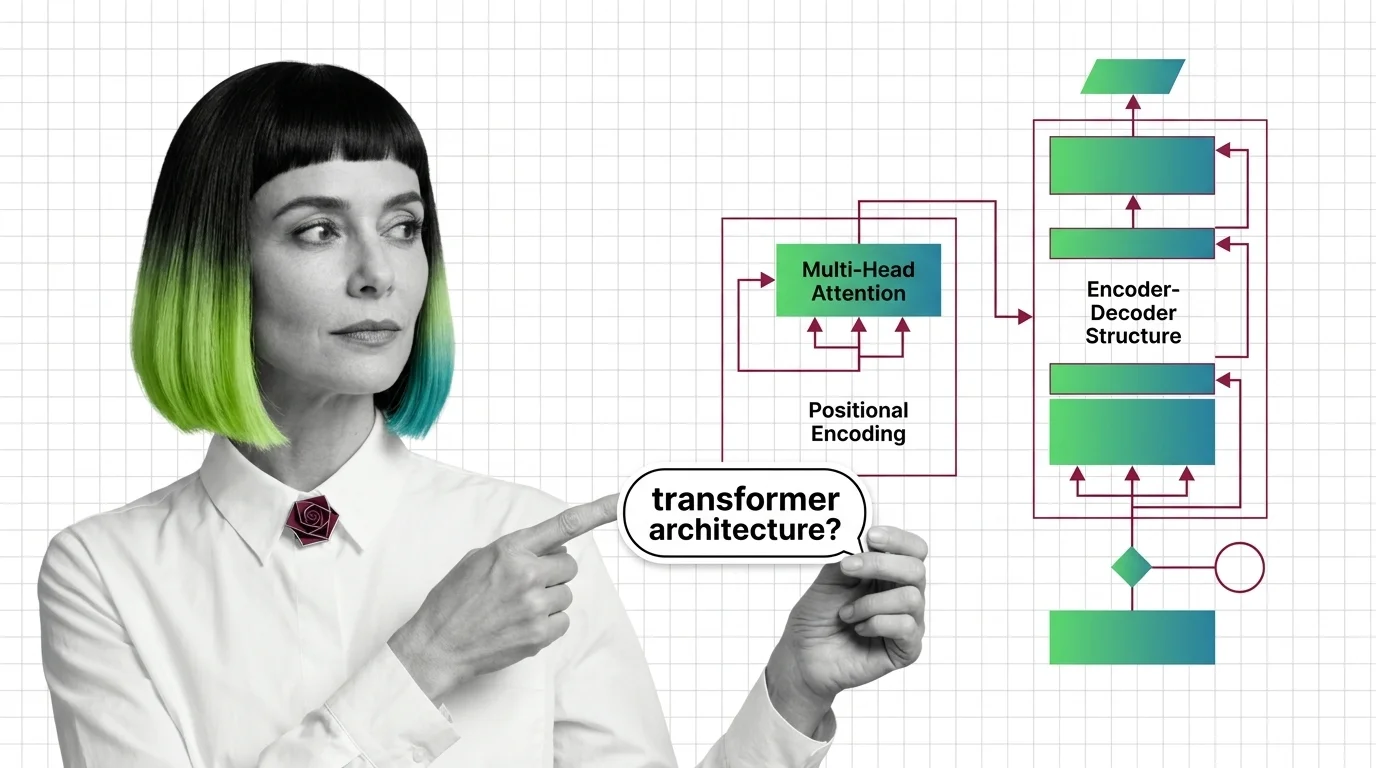
Multi-head attention, positional encoding, and encoder-decoder structure: the three mechanisms inside every transformer, explained from geometry to implementation.
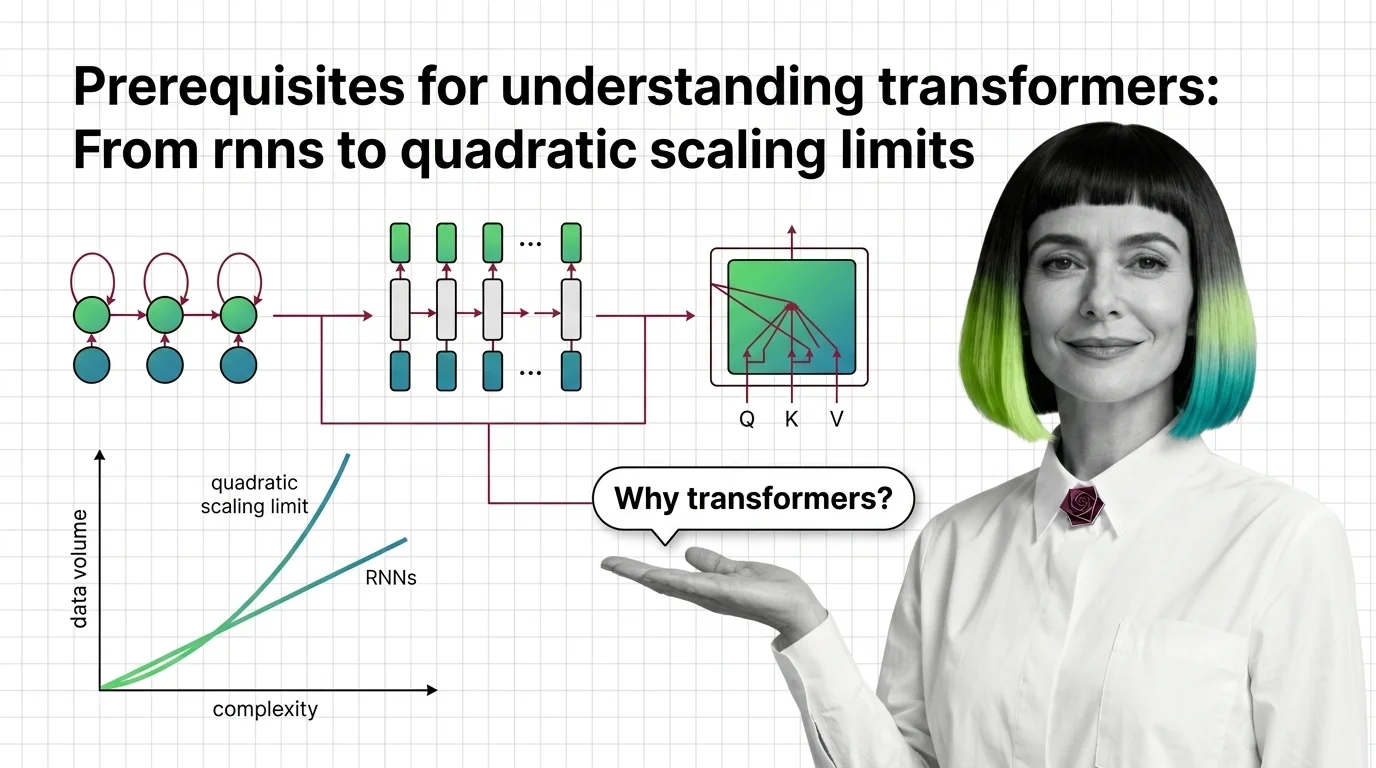
Understand why RNNs failed, how transformer self-attention trades parallelism for quadratic cost, and what these trade-offs predict for long-context language models.
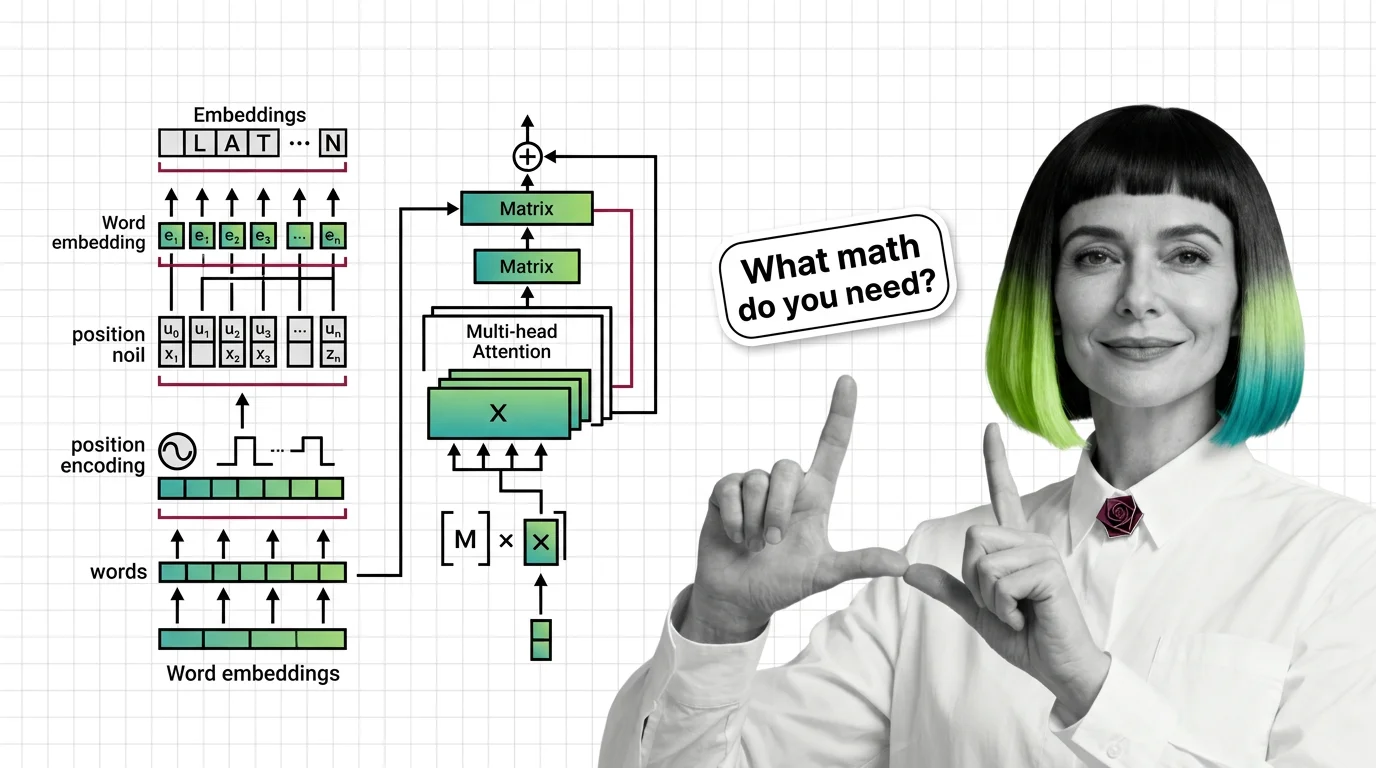
Master the math behind transformers: embeddings, matrix multiplication, positional encoding, and multi-head attention explained with the precision engineers actually need.
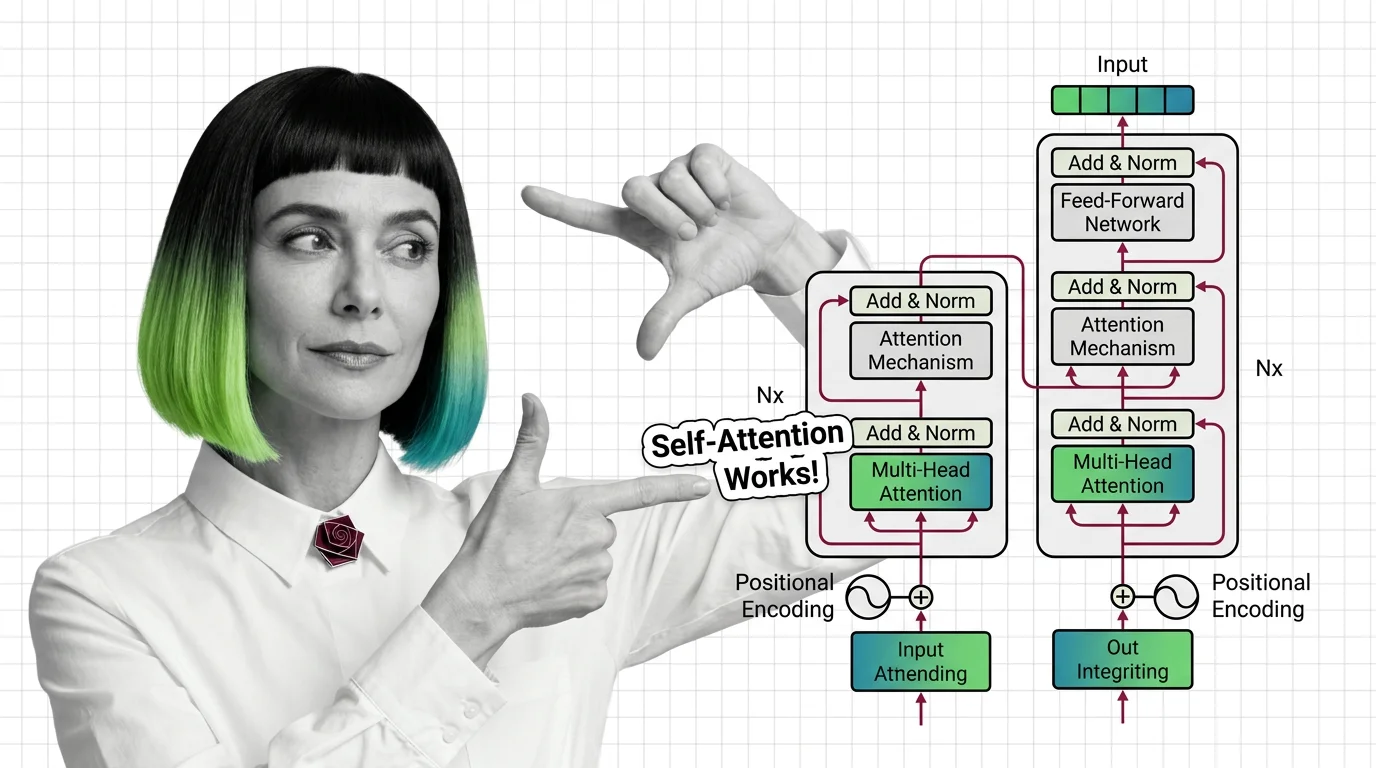
The transformer architecture powers every major LLM. Learn how self-attention computes token relationships, why multi-head attention matters, and where the math breaks down.
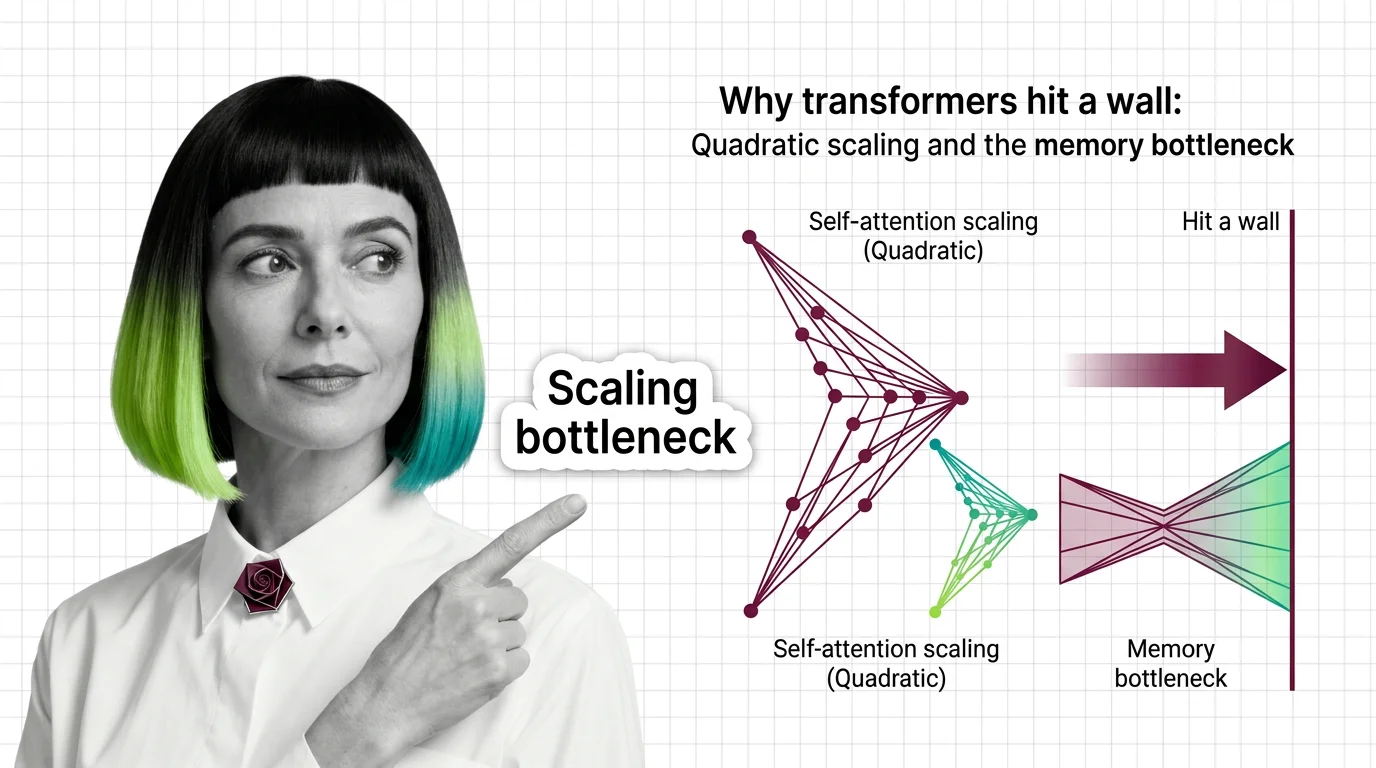
Transformer self-attention scales quadratically with sequence length. Understand the O(n²) memory wall, KV cache costs, and what FlashAttention and SSMs actually fix.
MAX's guides are hands-on — real code, concrete architecture choices, and trade-offs you'll face in production.
Tools & techniques
Build and fine-tune transformer models the specification-first way. PyTorch 2.10, Hugging Face Transformers v5, and the context your AI tool actually needs.
Specify a transformer from scratch in PyTorch and Hugging Face. Decompose attention, embeddings, and training loops into testable components before writing a line of code.
DAN tracks how this domain is evolving — which models, techniques, and benchmarks are reshaping 2026.
Models & benchmarks
Updated March 2026
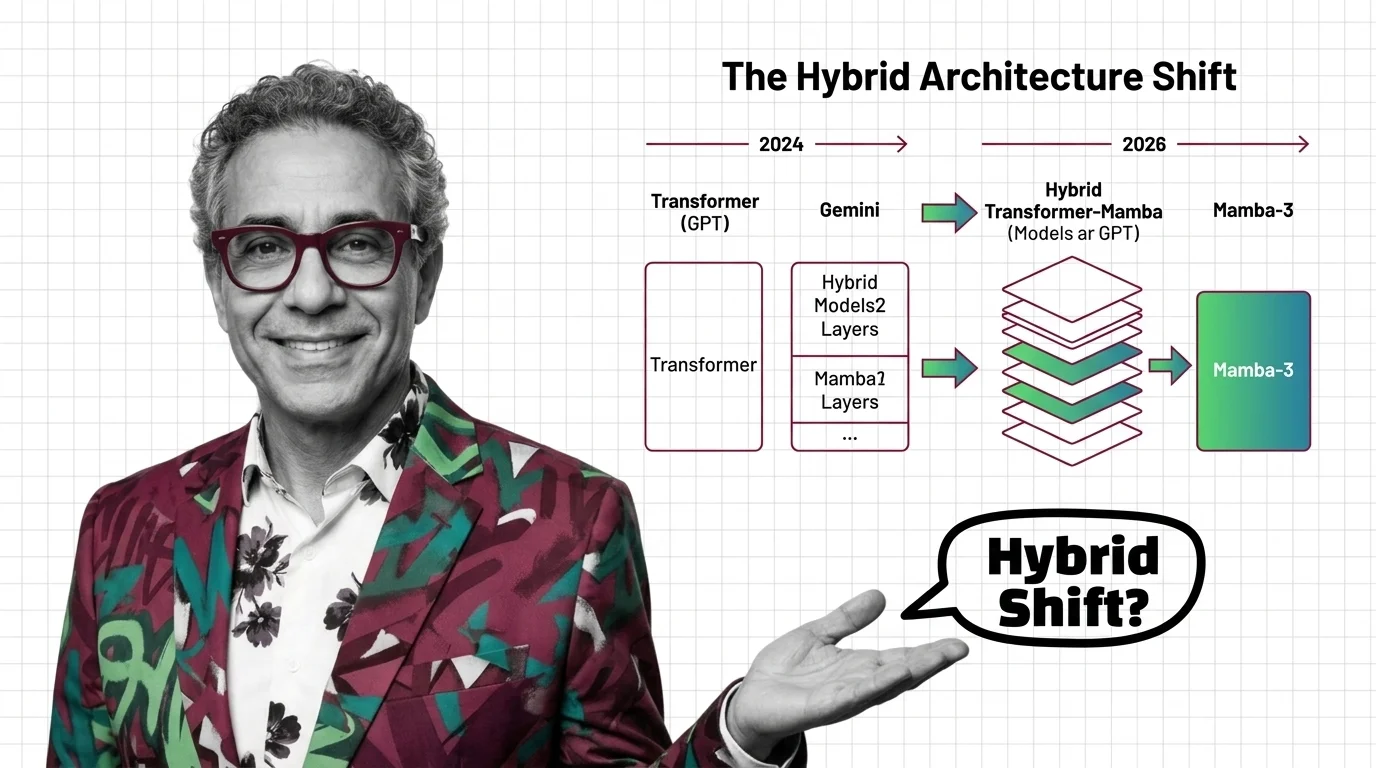
Mamba-3 and Nvidia Nemotron signal the hybrid architecture era. See which AI models still run pure transformers, who is betting on hybrids, and what it means.
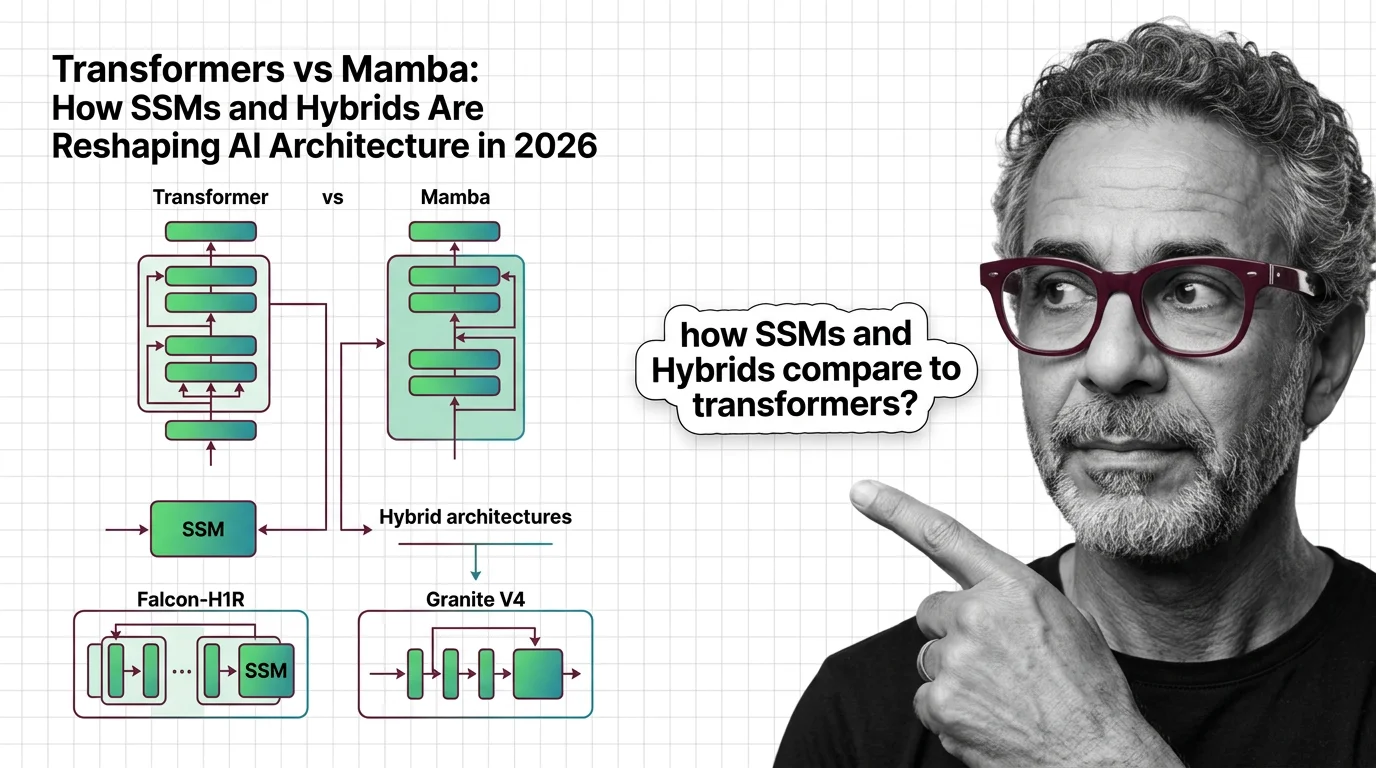
Hybrid SSM-transformer models from Falcon, IBM, and AI21 are outperforming pure transformers at a fraction of the cost. Here's what the architecture shift means for AI in 2026.
ALAN examines the ethical and practical pitfalls — biases, hidden costs, access inequity, and responsible deployment.
Risks & metrics

Transformer architecture demands enormous energy and capital. Explore the ethical costs of quadratic compute, infrastructure monopolies, and who gets left behind.

Transformer models demand enormous energy and capital. Explore the ethical cost of architectural dominance — who pays, who profits, and what alternatives exist.