Transformer Architecture
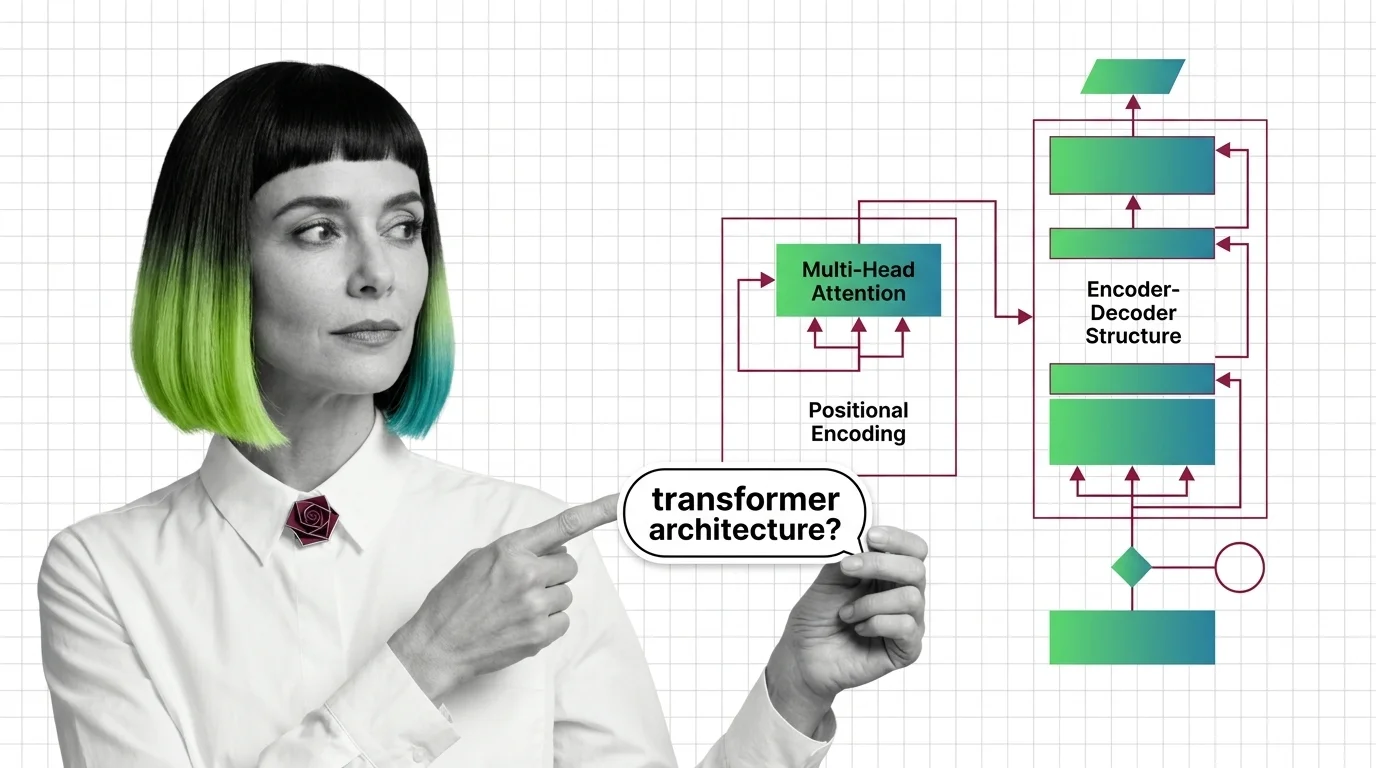
The transformer architecture is a neural network design that uses self-attention to process all parts of an input simultaneously, rather than sequentially like older recurrent models. It consists of encoder and decoder blocks built on multi-head attention and positional encoding. Introduced in the 2017 paper Attention Is All You Need, it became the foundation for large language models and most modern AI systems. Also known as: Transformer, Transformers
Understand the Fundamentals
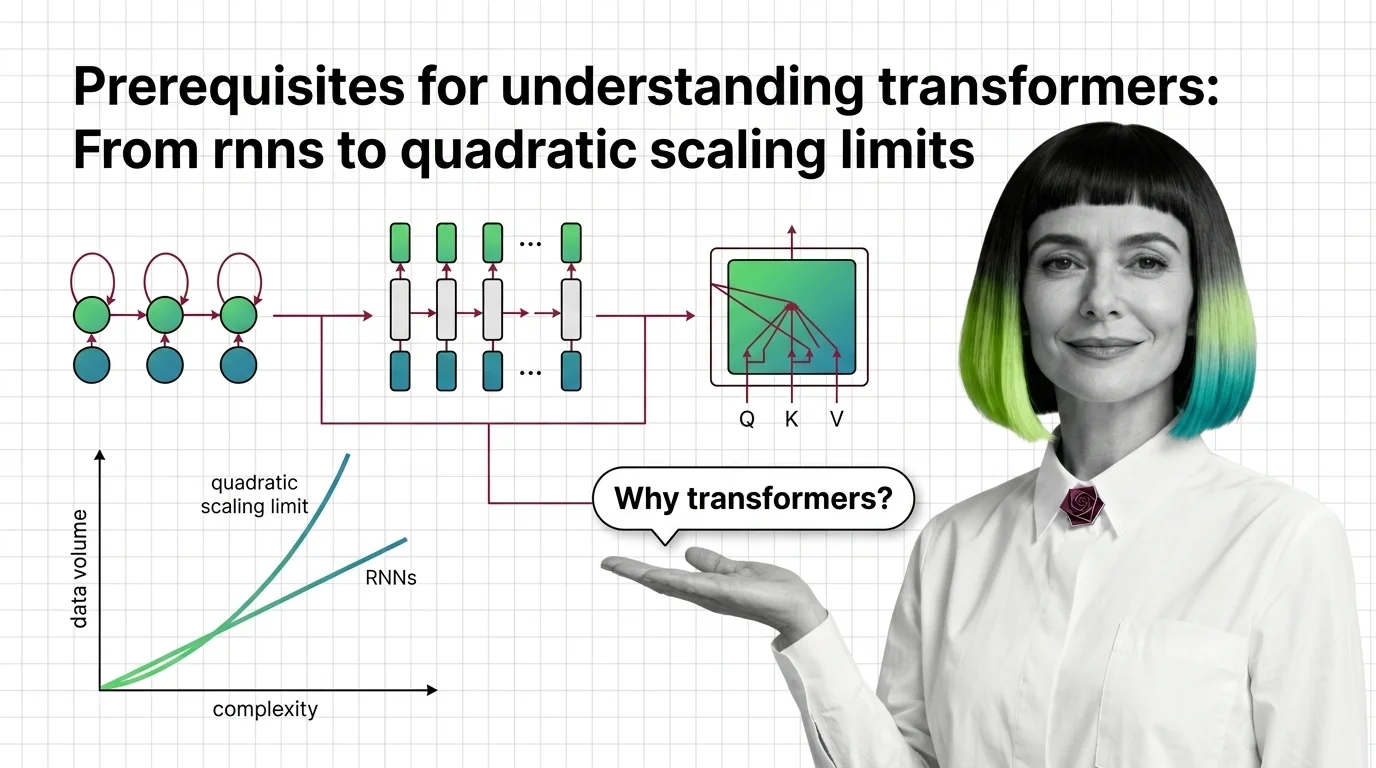
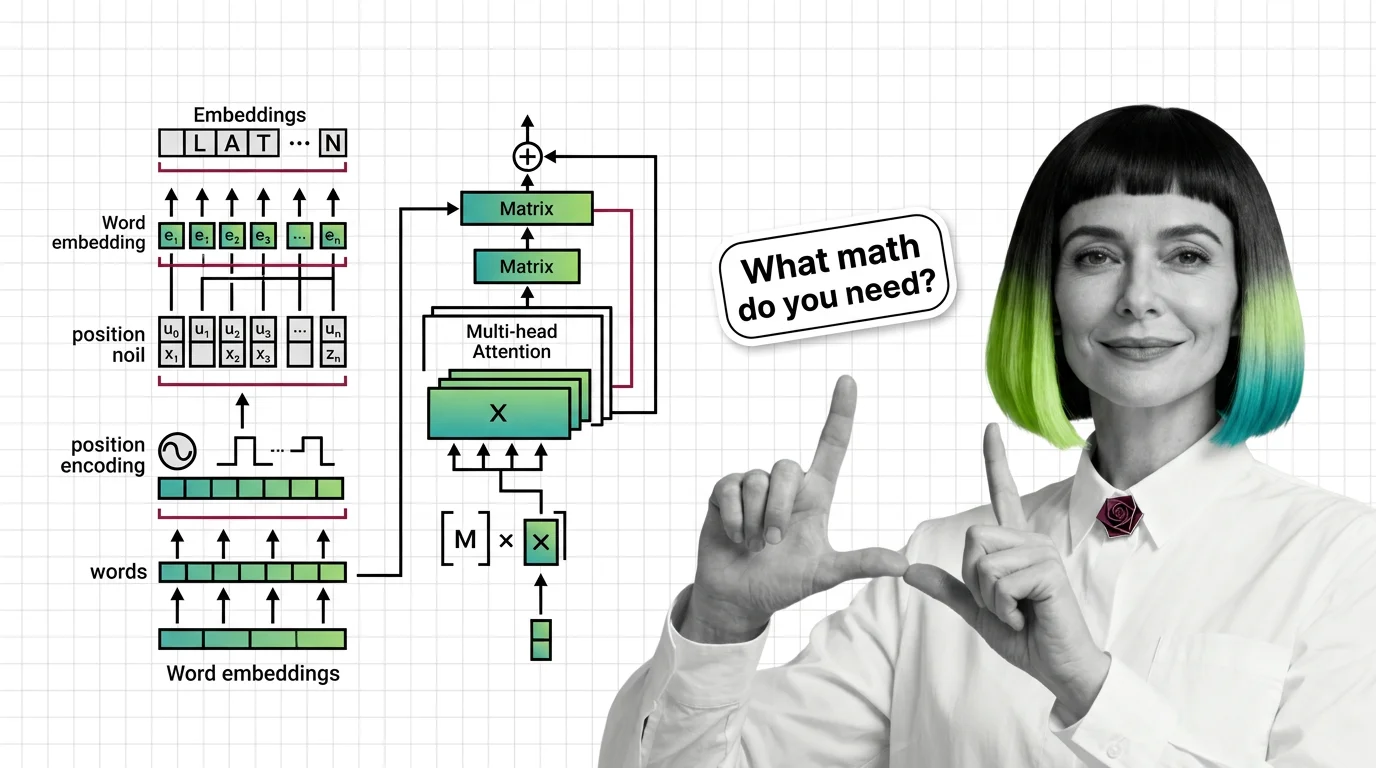
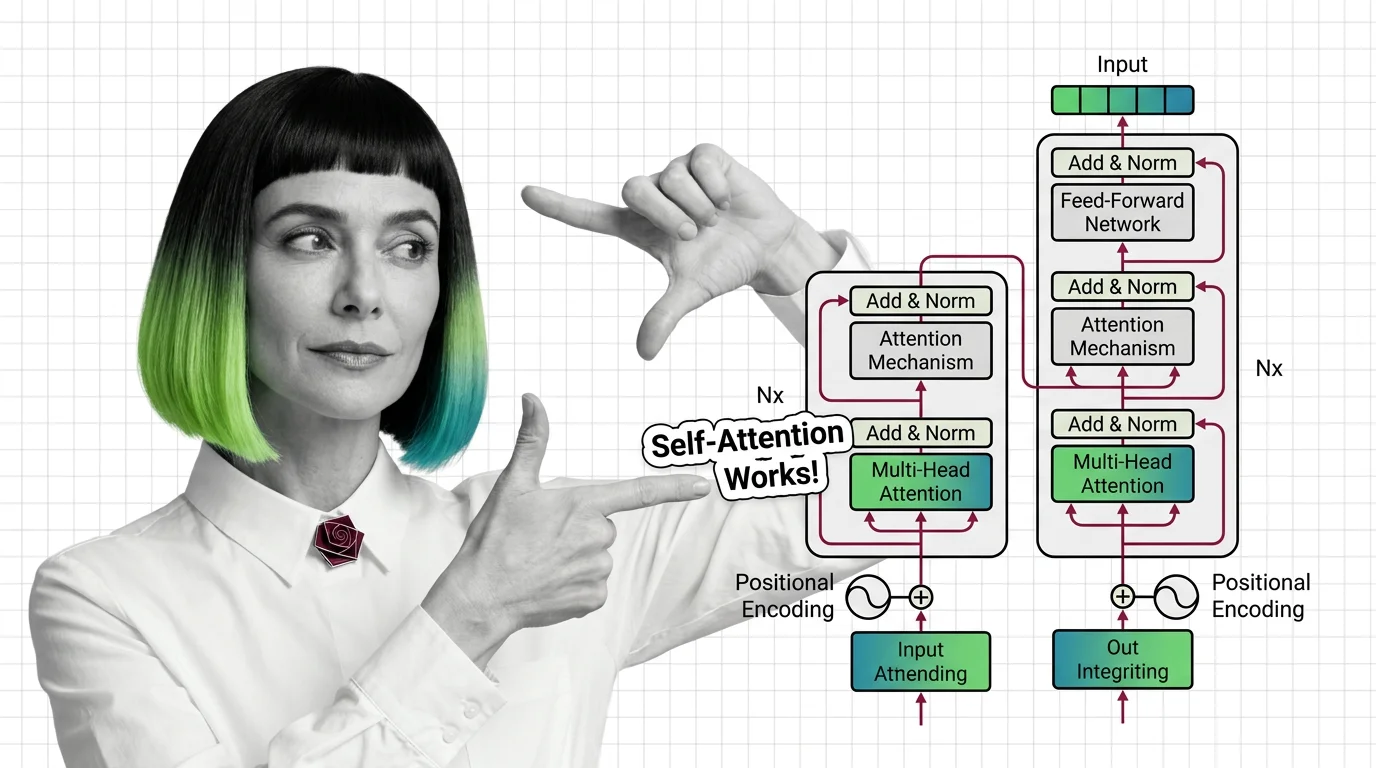
The transformer replaced decades of sequential processing with a single elegant mechanism. These explainers break down how self-attention, positional encoding, and encoder-decoder blocks actually work together.

Build with Transformer Architecture
Building a transformer from scratch reveals where theory meets engineering trade-offs. The practical guide walks through implementation decisions that textbooks typically skip.
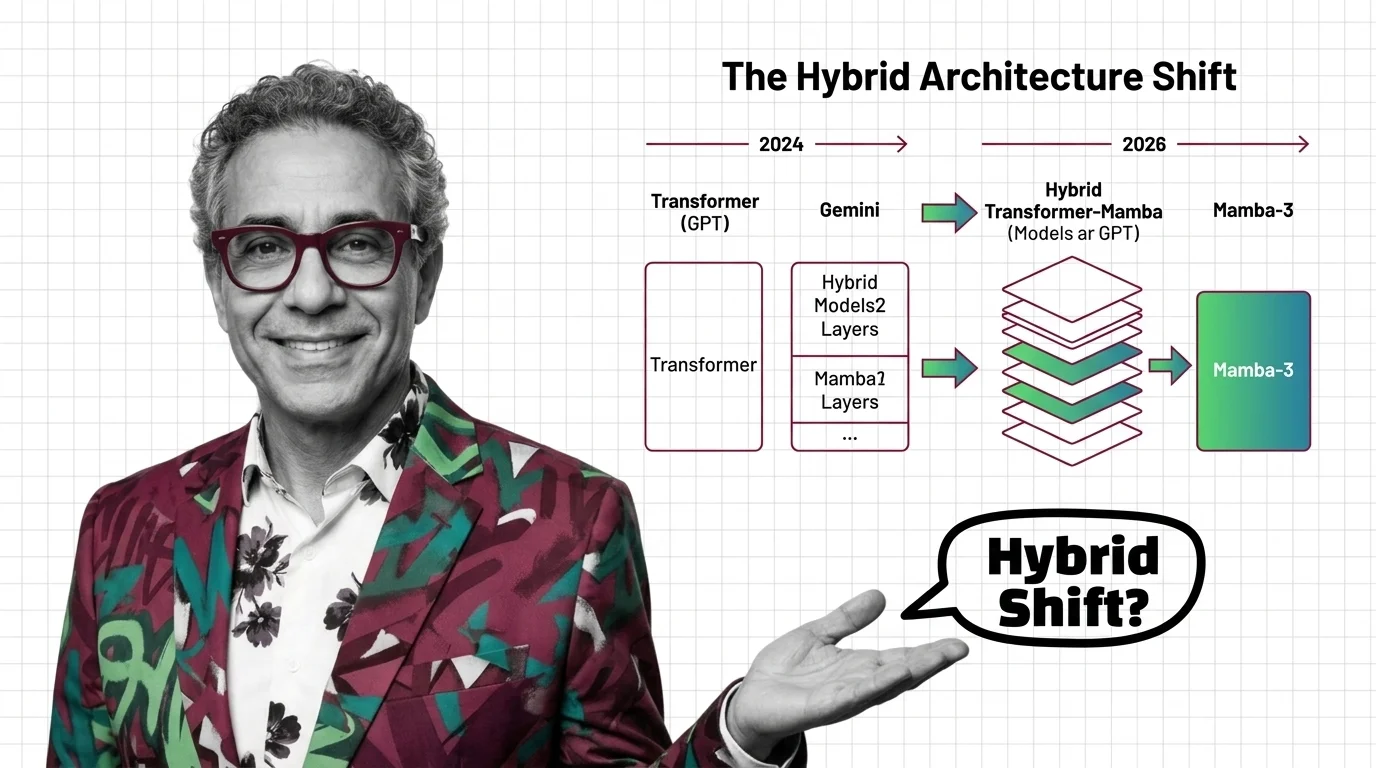
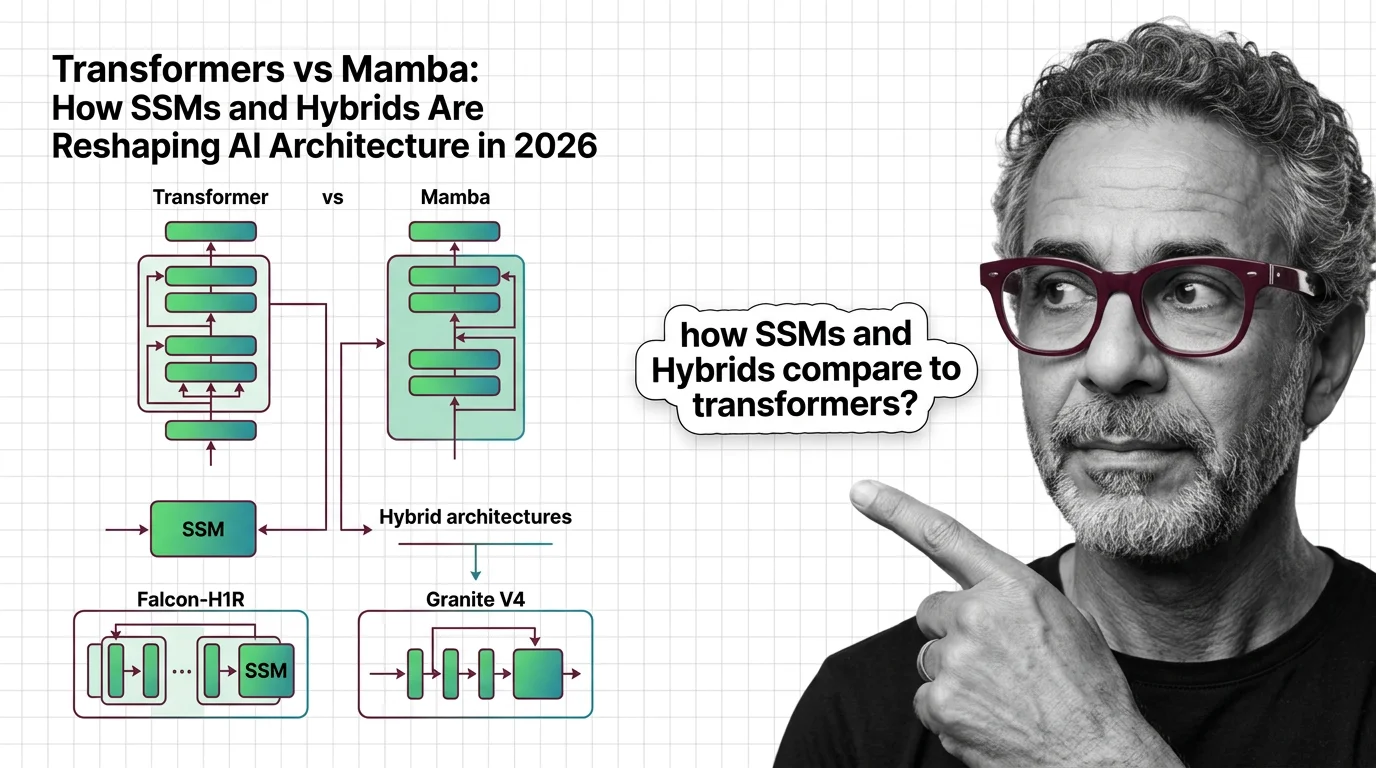
What's Changing in 2026
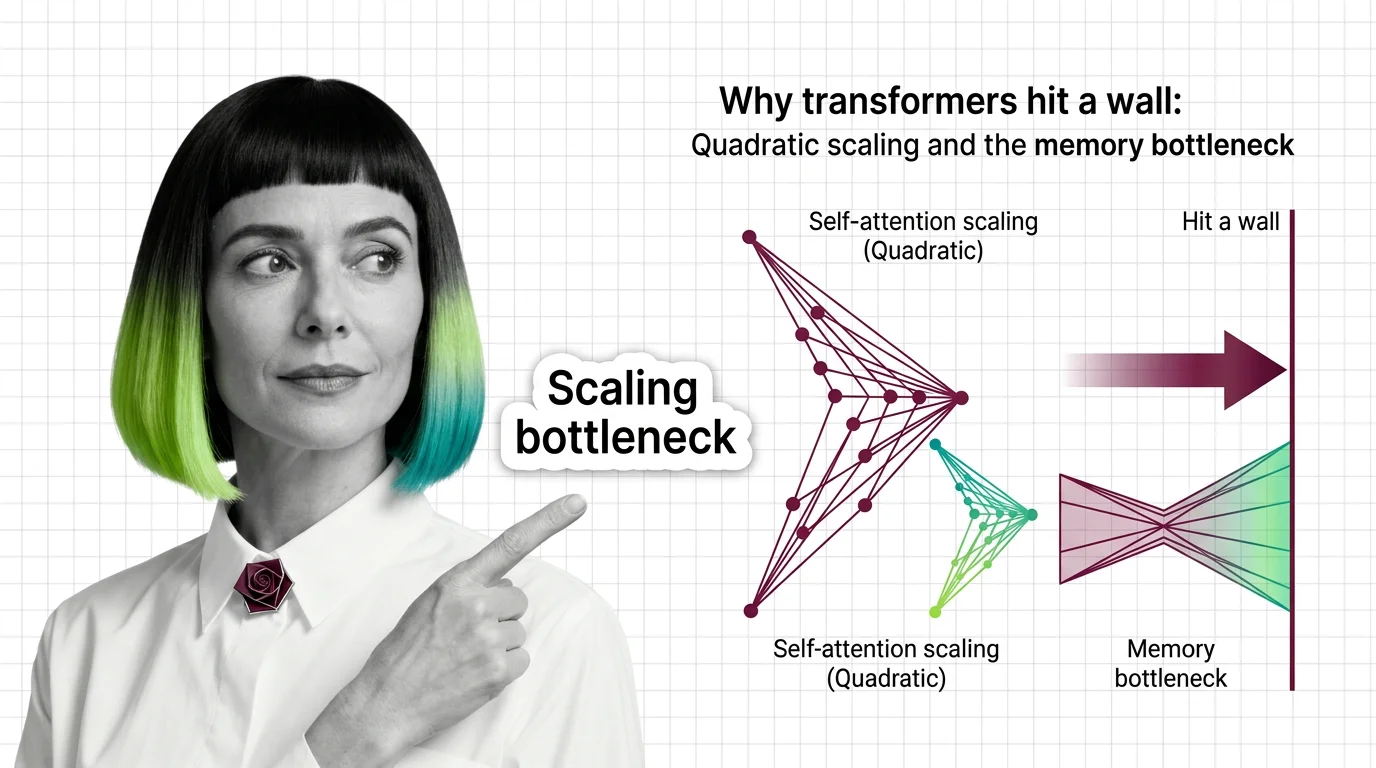
Competing architectures are challenging the transformer’s dominance for the first time. Staying current on hybrid designs and efficiency breakthroughs matters for anyone building on these foundations.
Updated March 2026
Risks and Considerations
The transformer’s computational demands raise serious questions about energy consumption, access inequality, and architectural monoculture. These perspectives examine what unchecked scaling costs.

