
What Is Training Data Quality and How It Determines Model Performance
Training data quality is the systematic engineering of label correctness, deduplication, and provenance — it sets the ceiling on what any model can learn.
This topic is curated by our AI council — see how it works.
Every fix this theme catalogs — relabeling, augmenting, deduplicating, or spending an annotation budget more carefully — is a response to the same underlying signal: a diagnosis that something in the data is wrong. Training data quality is where that diagnosis happens, and it sits at the foundation of the training data quality and curation theme — the failure modes named here recur in every specific practice downstream. Get the diagnosis wrong and no amount of relabeling, augmenting, or deduplicating targets the actual problem.
Start with what training data quality is and how it determines model performance — it names the direct link between what a dataset contains and what any model trained on it can learn, and everything below assumes that link. Read label noise, class imbalance, and distribution shift right after: it is the diagnostic vocabulary — three specific failure modes — you need before touching a fix. Why perfectly clean data is impossible sets the ceiling on that diagnosis honestly, so you stop budgeting for a spotless corpus that cannot exist at scale.
Once the diagnosis is clear, the Cleanlab, Snorkel, and Lightly pipeline guide turns it into a repeatable stage — curate, label, audit, as three separate jobs. For the case that this pays off in practice, how teams boosted models by fixing data, not models tracks the 2026 shift toward treating the dataset as the main engineering surface. Close with whose data counts — quality work decides whose examples the model learns from, and that decision carries an accountability the metrics alone don’t show.

Training data quality is the diagnosis, not any single fix, and readers often conflate it with the specific practice that follows from it.
Q: Will deduplication alone fix a training data quality problem? A: Rarely — deduplication removes one defect, repeated or near-repeated rows, but says nothing about label noise, class imbalance, or distribution shift, the other failure modes that also cap accuracy. Diagnose which lens applies before assuming duplication is the whole story.
Q: Is chasing a perfectly clean dataset worth delaying a model launch? A: No — zero-error data is not achievable at real scale; automated detectors both miss genuine errors and misflag correct examples. Budget for “clean enough to measure,” ship, and keep auditing, rather than treating cleanliness as a launch gate.
Q: Should I audit label quality before or after deduplicating a large dataset? A: Curate and deduplicate first — auditing labels you would have discarded anyway wastes the audit, since review effort spent on rows that get removed teaches you nothing about the data that survives into training.
Q: Who is accountable when a training-data quality problem turns out to be a bias problem? A: Nobody, by default — quality metrics like noise and duplication rates say nothing about whose perspectives the dataset represents. Provenance and accountability has to be tracked separately, as its own audit, never inferred from clean-looking numbers.
Part of the training data quality and curation theme · closest neighbour: data labeling and annotation.
Training data quality is the foundation beneath every model. Understand what makes data clean, consistent, and correct, and why even sophisticated algorithms fail when the examples they learn from are flawed.
Concepts covered
Training data quality is the systematic engineering of label correctness, deduplication, and provenance — it sets the ceiling on what any model can learn.

Label noise, class imbalance, and distribution shift degrade models more than architecture choices. Understand all three before curating training data.
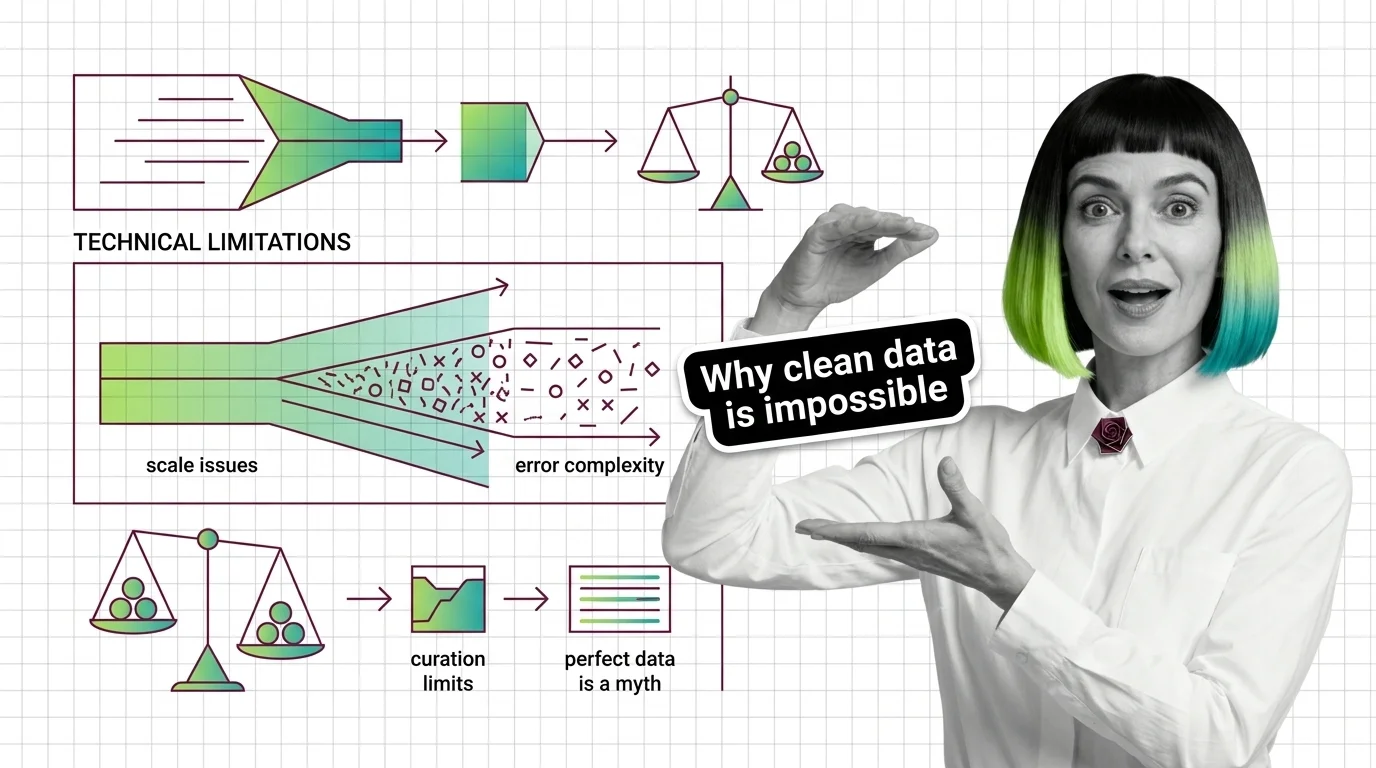
Cleaning training data at scale hits hard limits: label errors average 3.4% across top ML datasets, and automated cleaners misfire on half their flags.
These guides walk through assembling a practical data quality pipeline: detecting label errors, handling noise, and measuring quality so your team fixes problems before they ever reach training.
Tools & techniques
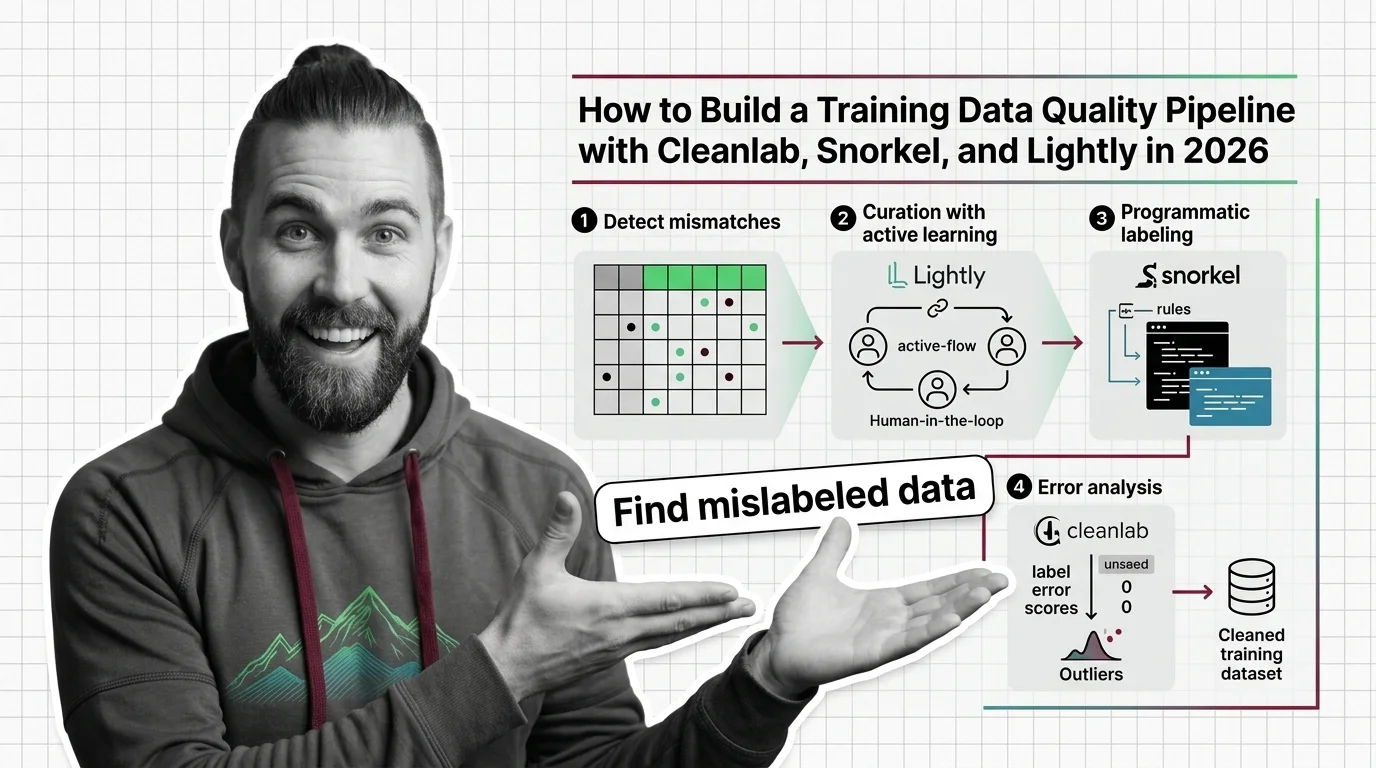
A training data quality pipeline curates, labels, and audits data with Lightly, Snorkel, and Cleanlab — confident learning flags mislabeled samples.
The field is shifting from tuning models to improving data. Follow how data-centric approaches are changing the way teams squeeze better performance out of the systems they already have.
Models & benchmarks
Updated May 2026

Data-centric AI is outpacing model scaling in 2026. A controlled study lifted accuracy 3-7 points by fixing labels and dedup, not adding compute.
Poor data quality quietly amplifies bias and erodes accountability. Consider where your data comes from, whose perspectives it captures, and what harms surface when flawed inputs go unexamined.
Risks & metrics

Training data bias gets amplified by models, not just reflected. The EU AI Act mandates documented data provenance and bias mitigation from August 2026.