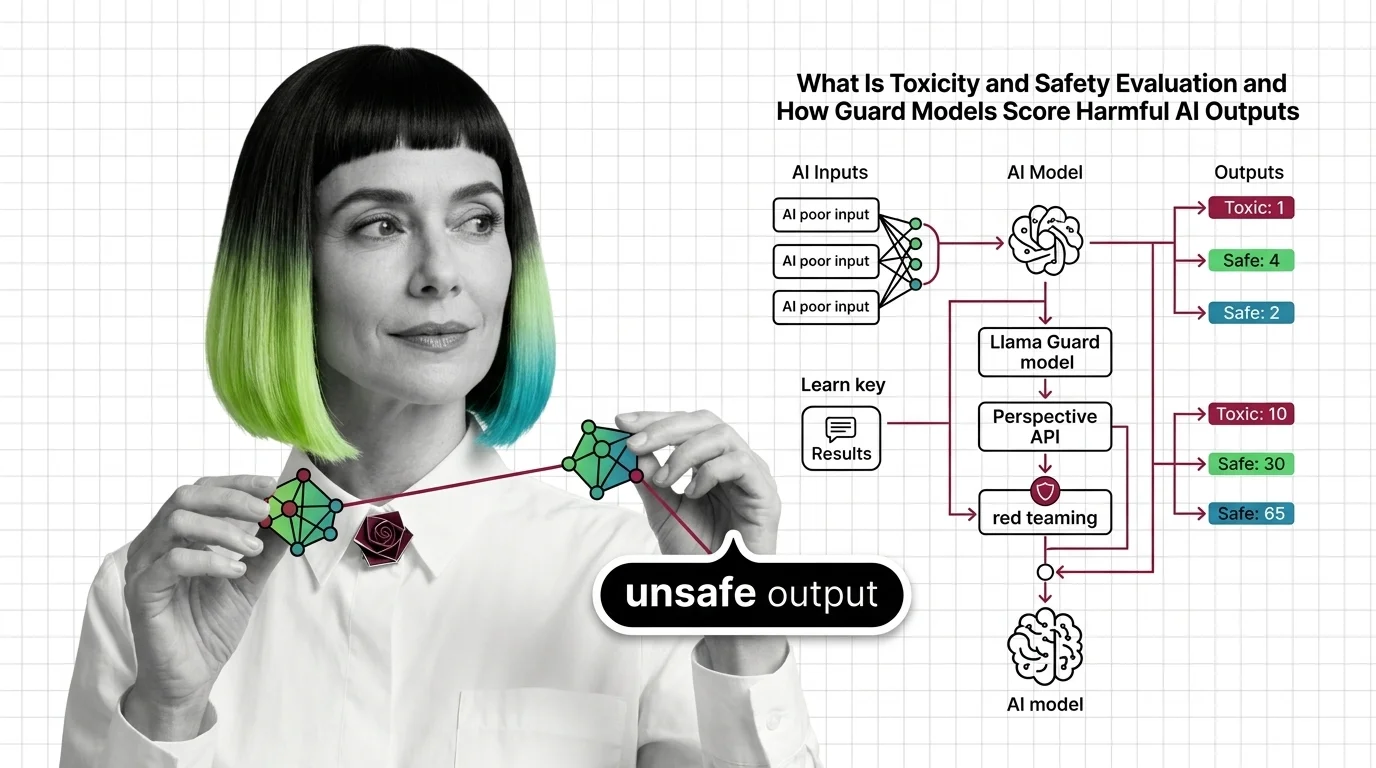
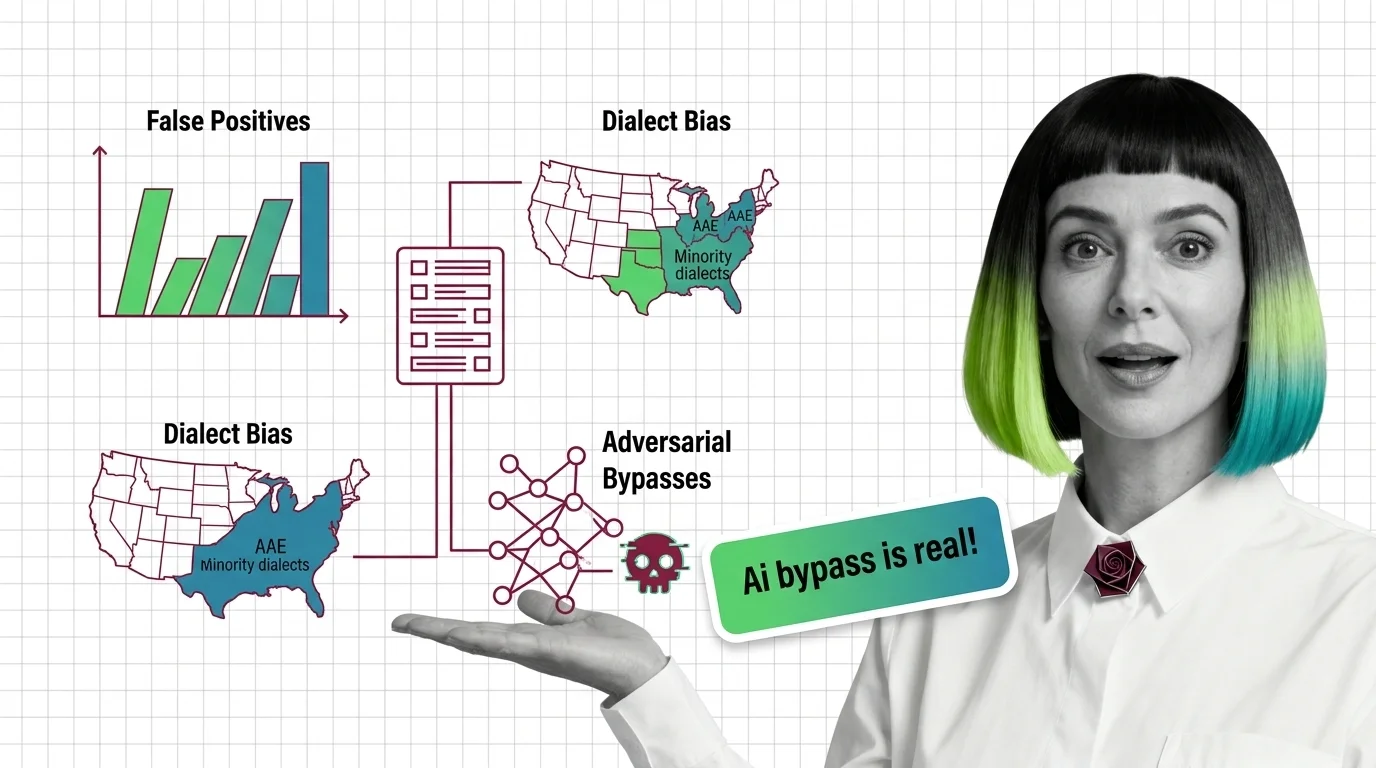
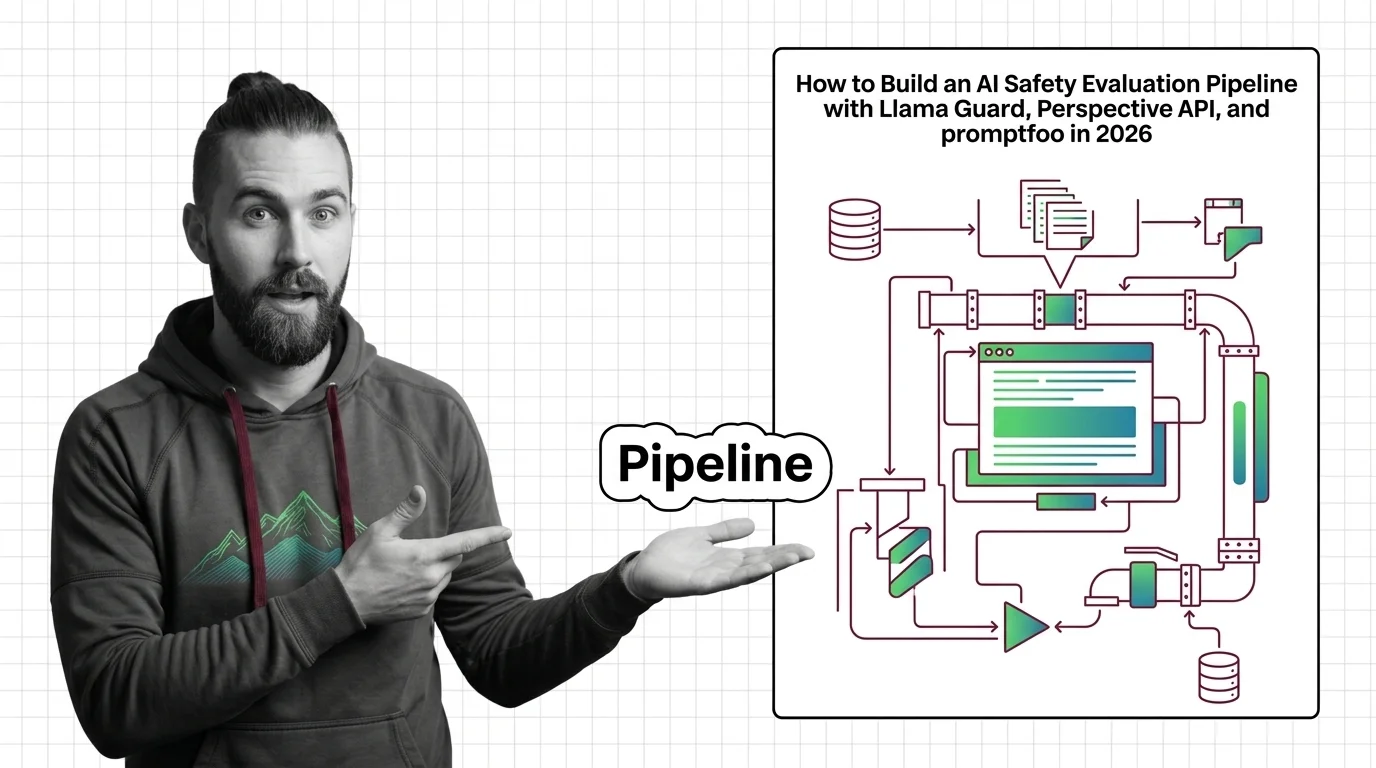
HarmBench, ToxiGen, and MLCommons Taxonomy: The Datasets and Standards Behind AI Safety Testing
HarmBench, ToxiGen, and MLCommons AILuminate define how AI safety is measured. Learn the datasets, classifiers, and taxonomies behind modern toxicity evaluation.