Toxicity and Safety Evaluation
Toxicity and safety evaluation encompasses the metrics, datasets, and frameworks used to measure whether AI systems produce harmful, biased, or unsafe outputs. These evaluations typically combine automated classifiers, curated adversarial datasets, and human review to test model behavior across categories like hate speech, self-harm instructions, and misinformation. The field has evolved from simple keyword filters to multi-layered guard model pipelines that score content risk in real time. Also known as: Safety Benchmarks, Toxicity Detection
Understand the Fundamentals
Toxicity and safety evaluation requires distinguishing genuine harm from edge cases across languages and cultures. The metrics behind these systems reveal as much about their blind spots as their capabilities.

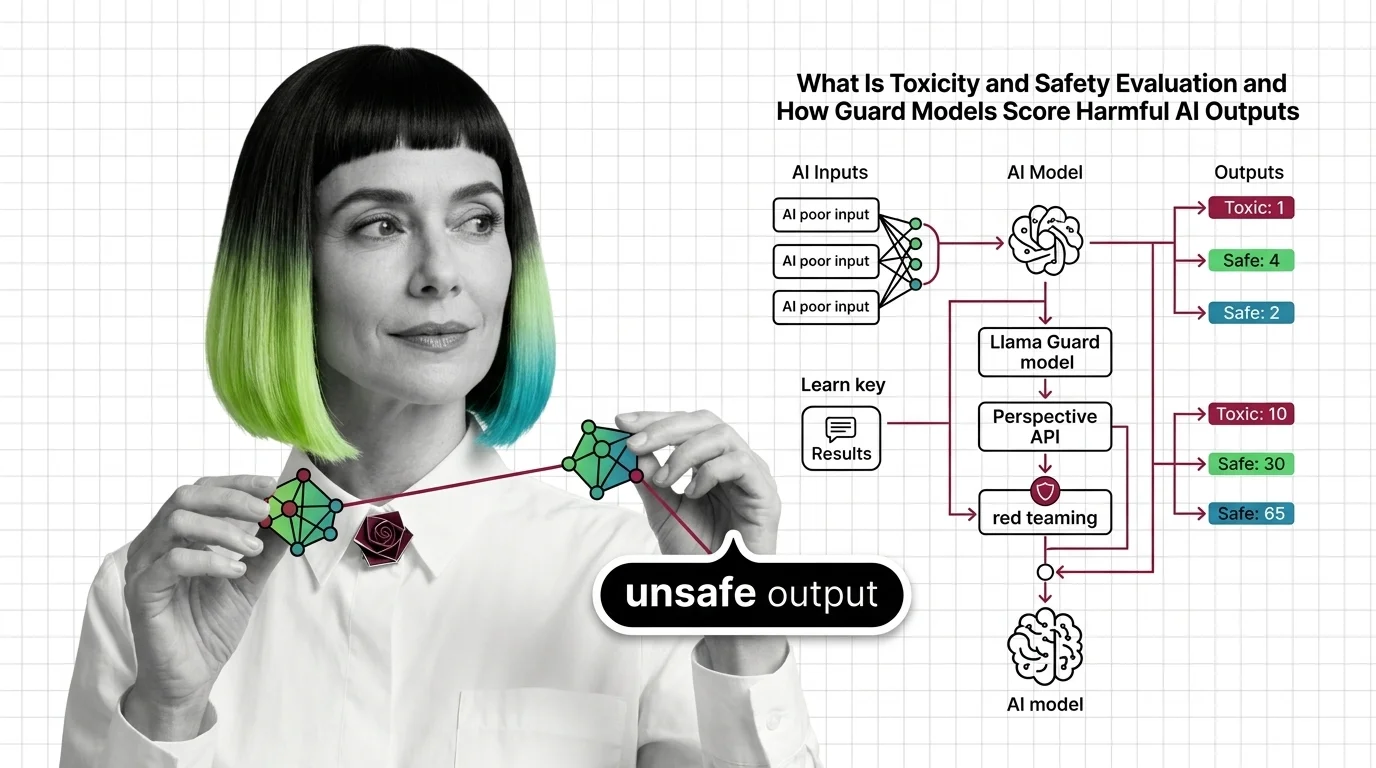
Build with Toxicity and Safety Evaluation
The practical guides cover building evaluation pipelines that combine guard models, adversarial datasets, and automated scoring, plus the trade-offs between recall, precision, and latency you will face.
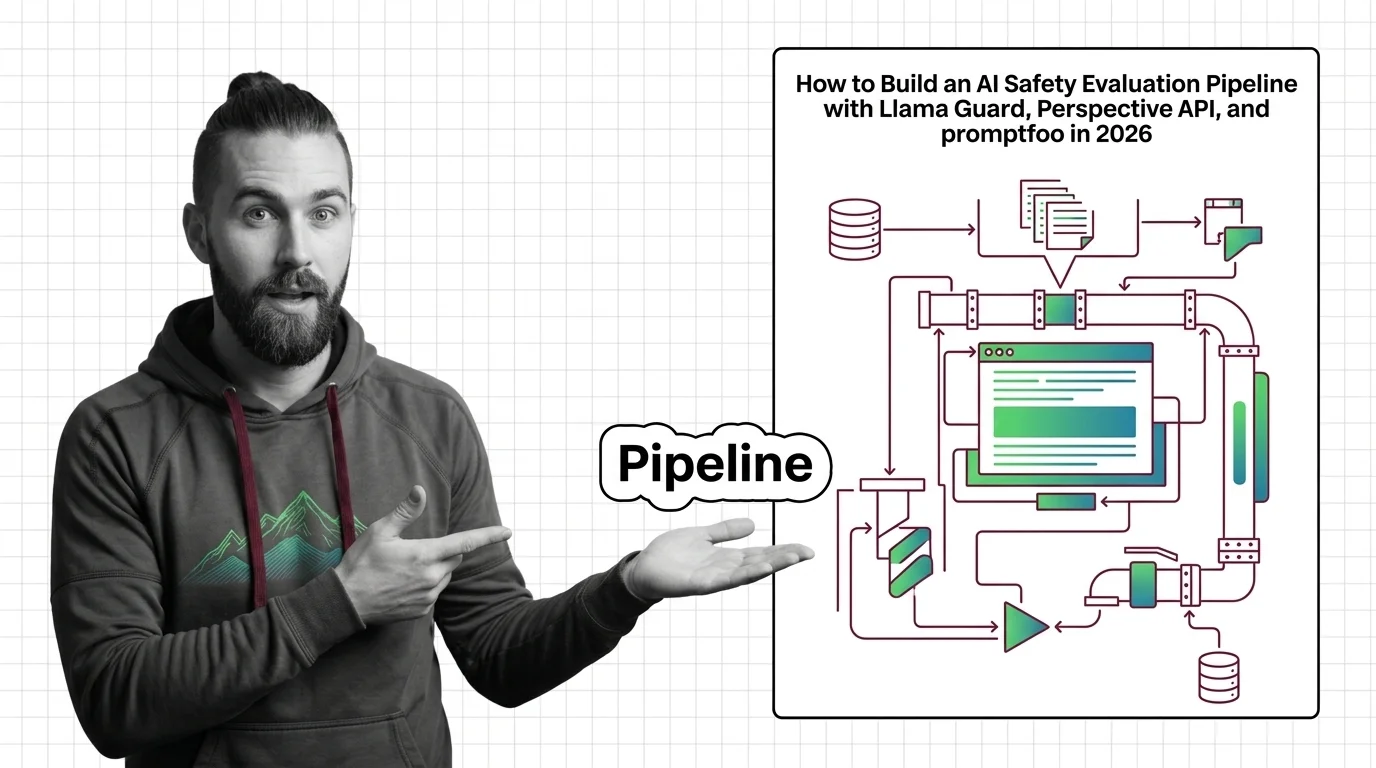
What's Changing in 2026
Safety evaluation standards are shifting rapidly as new adversarial techniques outpace existing classifiers. Tracking which benchmarks and guard models gain adoption shapes how your deployments stay compliant.
Updated March 2026

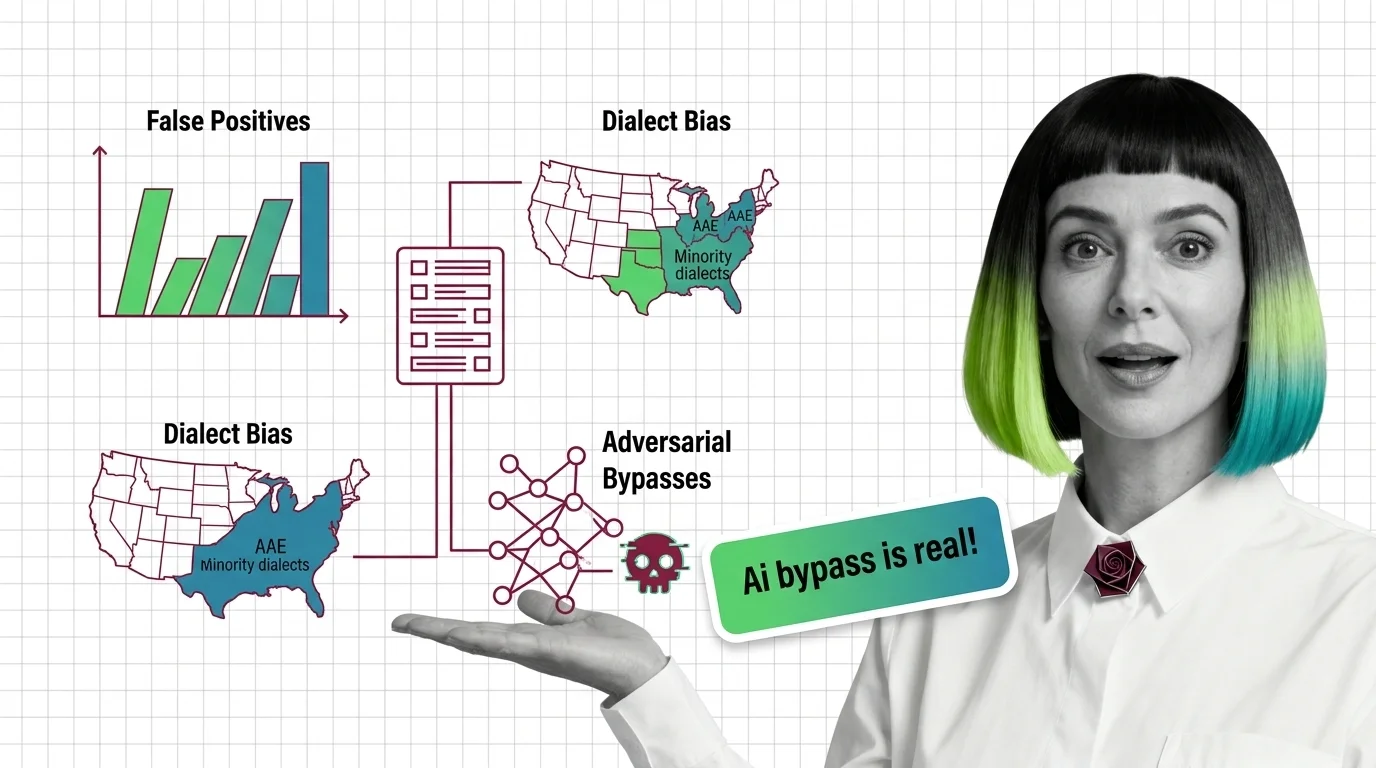
Risks and Considerations
Automated toxicity detection can overcensor marginalized dialects, miss sophisticated adversarial prompts, and encode cultural assumptions as universal rules. Understanding these failure modes is essential before trusting any safety score.
