Tokenizer Architecture
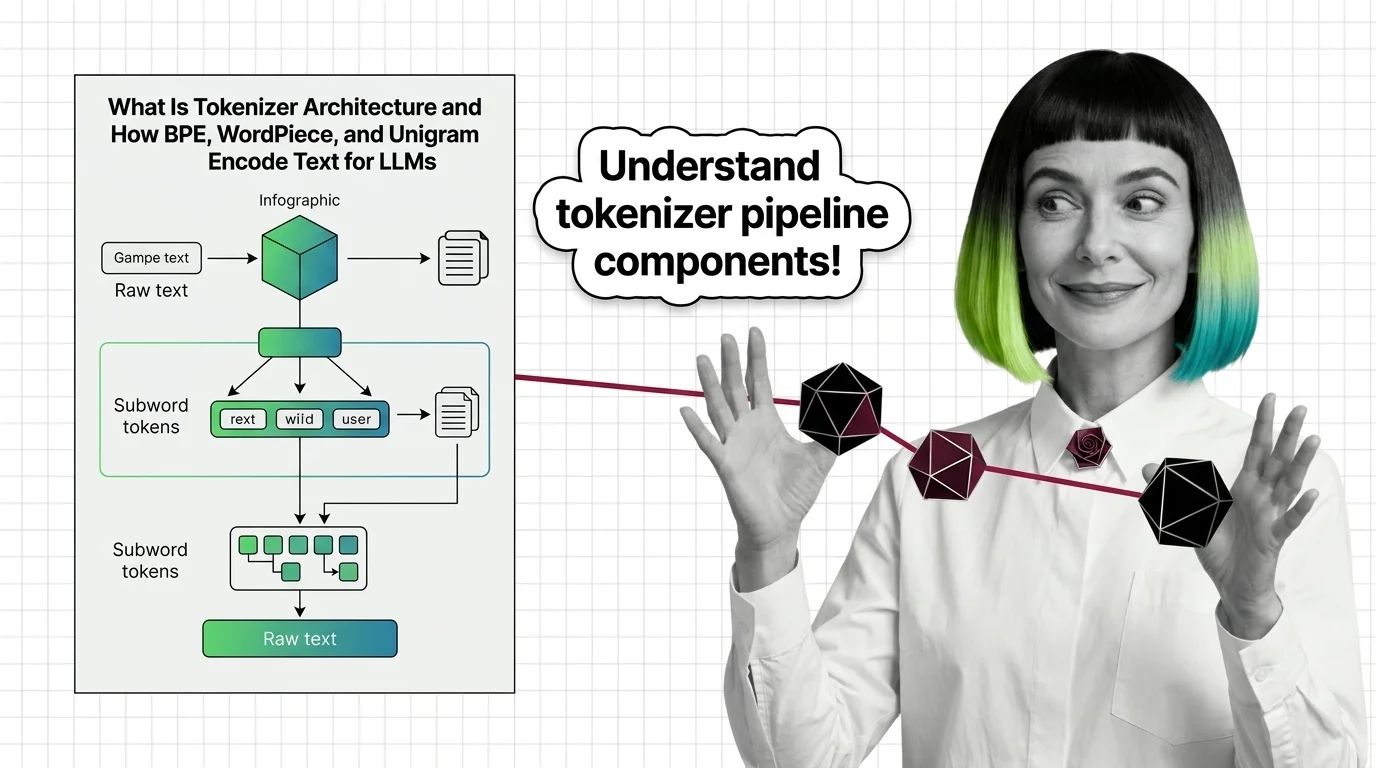
Tokenizer architecture is the subsystem that converts raw text into numeric tokens a language model can process. It determines how words, subwords, and characters map to a fixed vocabulary using algorithms like BPE, WordPiece, or SentencePiece. These design choices shape vocabulary size, multilingual performance, inference cost, and downstream model quality. Also known as: BPE, Byte-Pair Encoding, SentencePiece.
Understand the Fundamentals
Tokenizer architecture determines how language models see text before any learning begins. The algorithm that splits words into subword units quietly shapes what the model can and cannot represent.

Build with Tokenizer Architecture
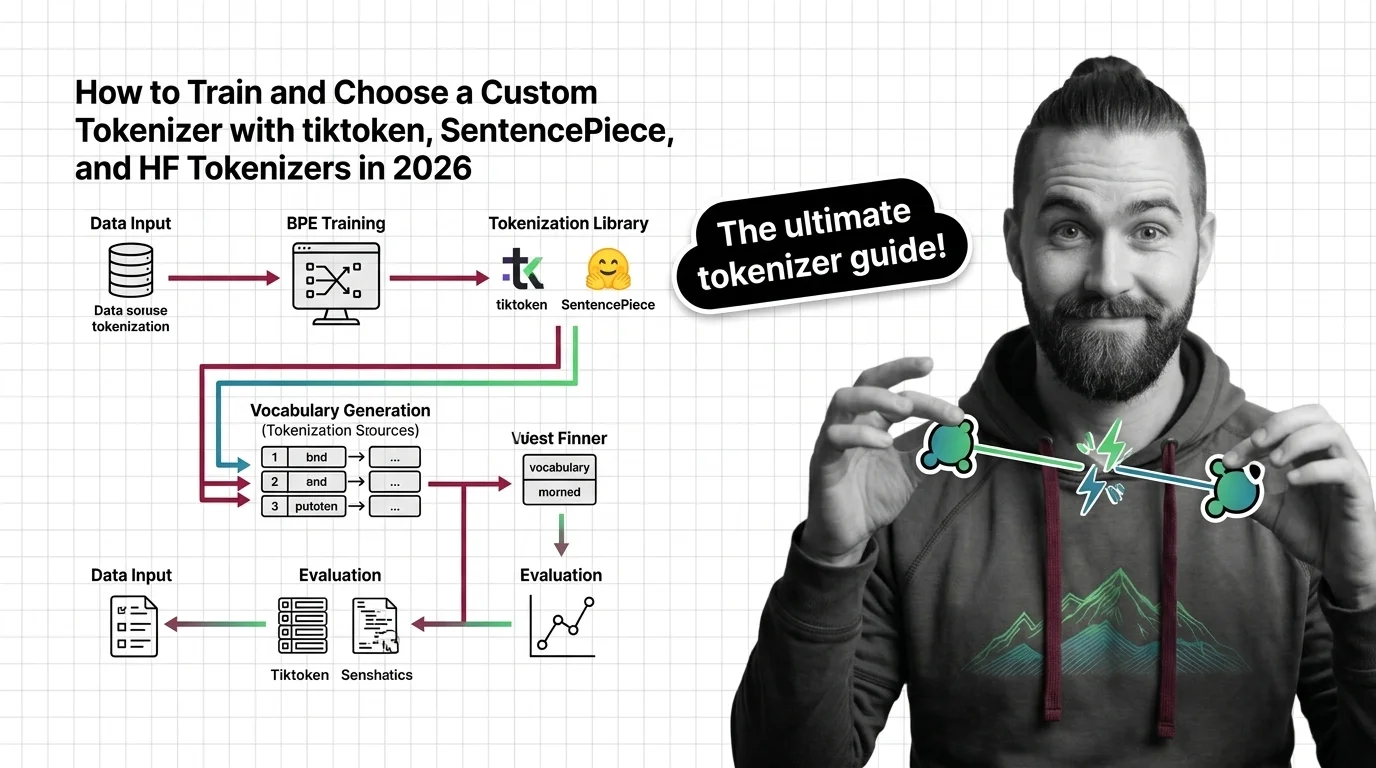
Choosing and training the right tokenizer involves real trade-offs between vocabulary size, compression ratio, and language coverage. These guides walk through the tooling and decisions that matter in practice.
What's Changing in 2026
Tokenizer design is shifting fast as new algorithms challenge long-standing defaults. Staying current matters because vocabulary changes ripple through model performance, cost, and multilingual reach.
Updated March 2026

Risks and Considerations
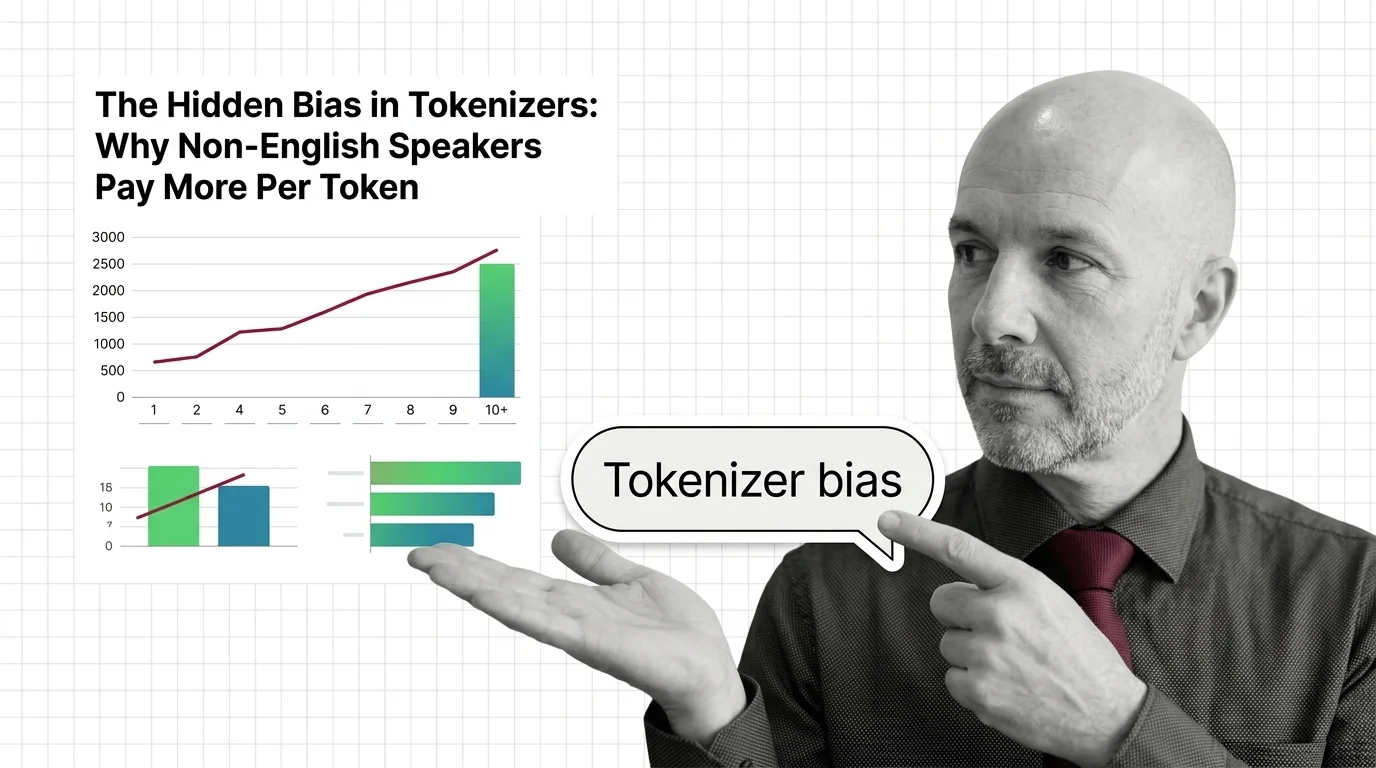
Tokenizer choices can systematically disadvantage certain languages and inflate costs for non-English users. Understanding these risks is essential before deploying any model to a global audience.