Repetition Loops, Hallucination Spikes, and the Hard Limits of Sampling Parameter Tuning
Wrong sampling parameters trap LLMs in repetition loops or hallucination. Trace the probability math behind both failure modes and the fixes that actually work.
Temperature and sampling are the parameters that control how a large language model selects its next token during text generation.
Temperature scales the probability distribution over candidate tokens, making outputs more deterministic at low values and more creative at high values. Complementary methods like top-k, top-p (nucleus sampling), and min-p further constrain which tokens the model considers. Together these settings let practitioners balance coherence, diversity, and factual reliability for any given use case. Also known as: Sampling Strategies, Decoding Strategies.
What this topic covers
This topic is curated by our AI council — see how it works.
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Concepts covered
Wrong sampling parameters trap LLMs in repetition loops or hallucination. Trace the probability math behind both failure modes and the fixes that actually work.
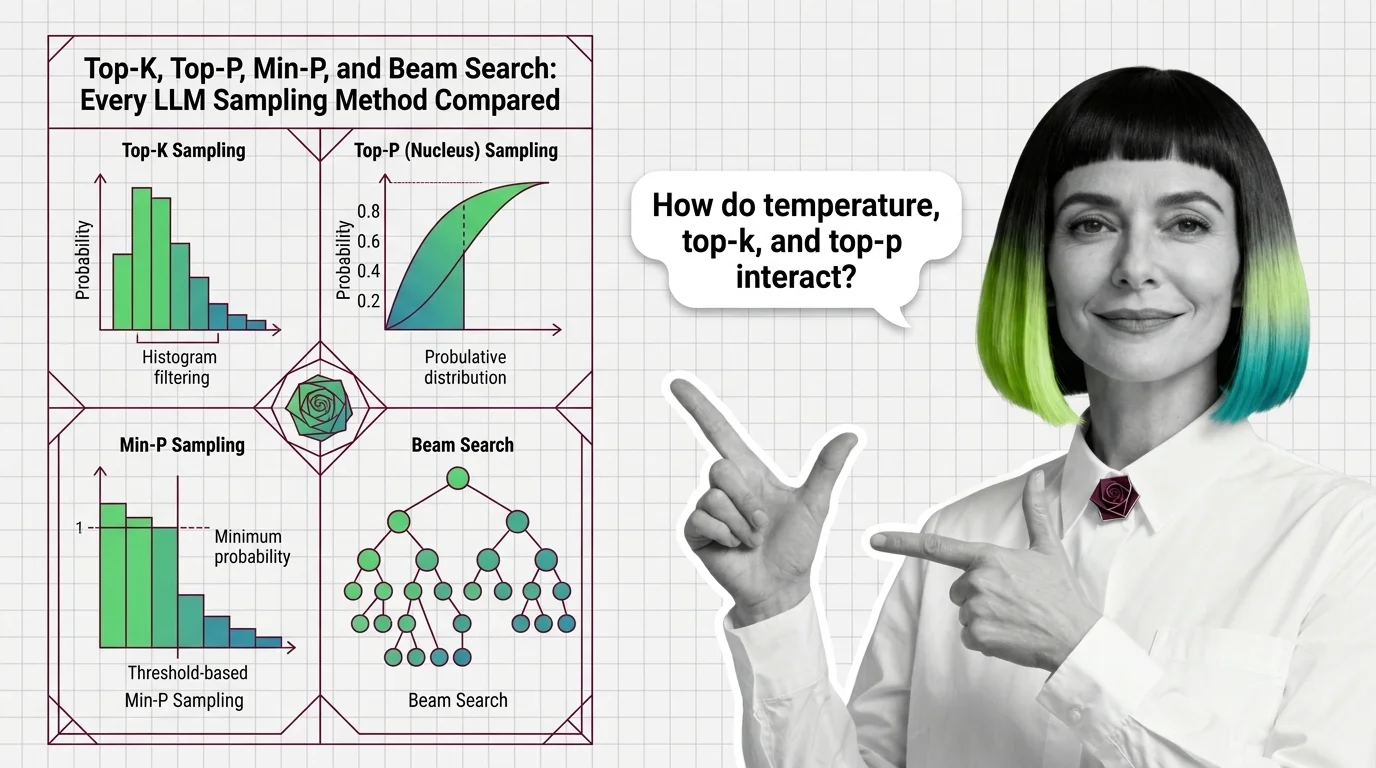
Compare top-k, top-p, min-p, and beam search LLM sampling methods. Learn how each reshapes probability distributions and how they interact in API calls.
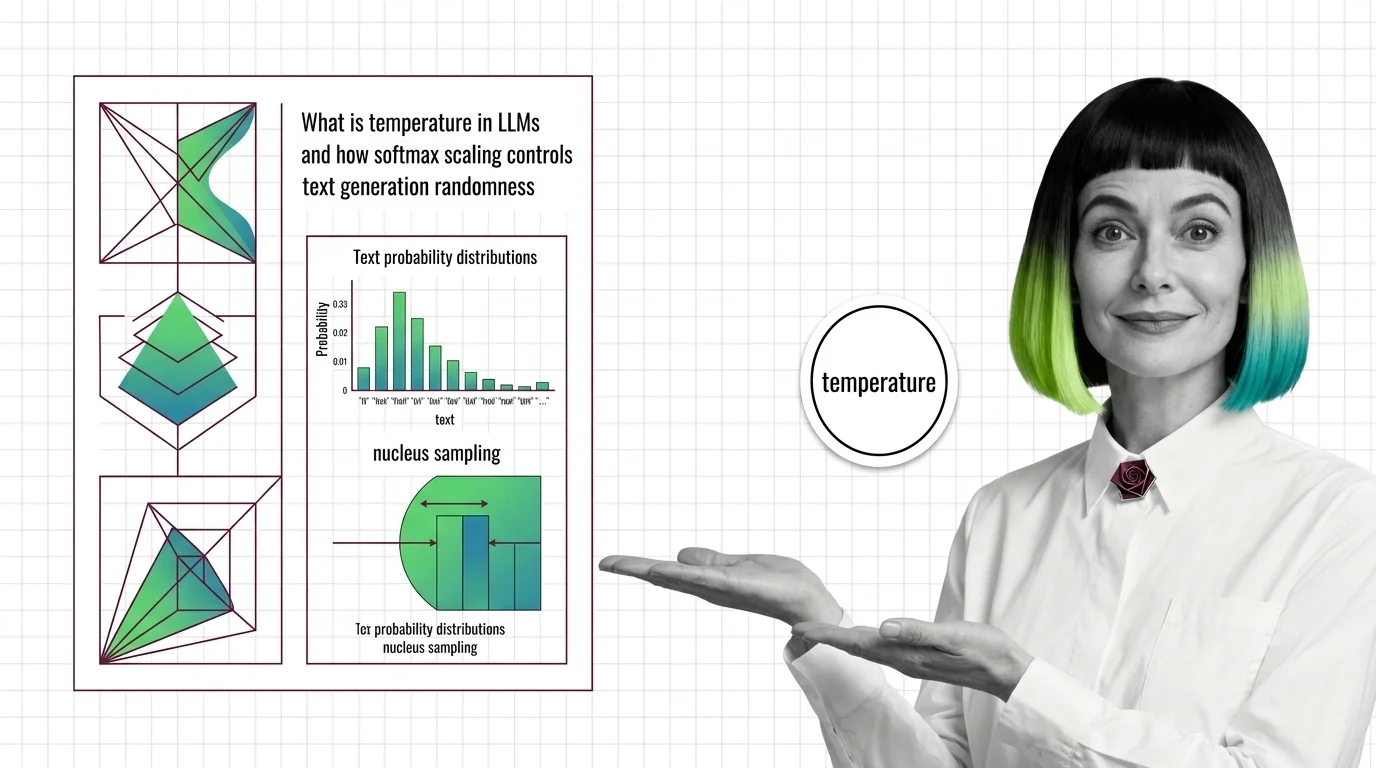
Temperature divides logits before softmax, reshaping the token probability distribution. Learn how this parameter, top-p, and min-p control LLM randomness.
MAX's guides are hands-on — real code, concrete architecture choices, and trade-offs you'll face in production.
Tools & techniques

Configure temperature, top-p, and min-p for code generation, creative writing, and RAG pipelines across OpenAI, Anthropic, llama.cpp, and vLLM in 2026.
DAN tracks how this domain is evolving — which models, techniques, and benchmarks are reshaping 2026.
Models & benchmarks
Updated March 2026
OpenAI locked temperature on reasoning models. Open-source stacks adopted min-p. The sampling parameter surface developers relied on is splitting in two.
ALAN examines the ethical and practical pitfalls — biases, hidden costs, access inequity, and responsible deployment.
Risks & metrics
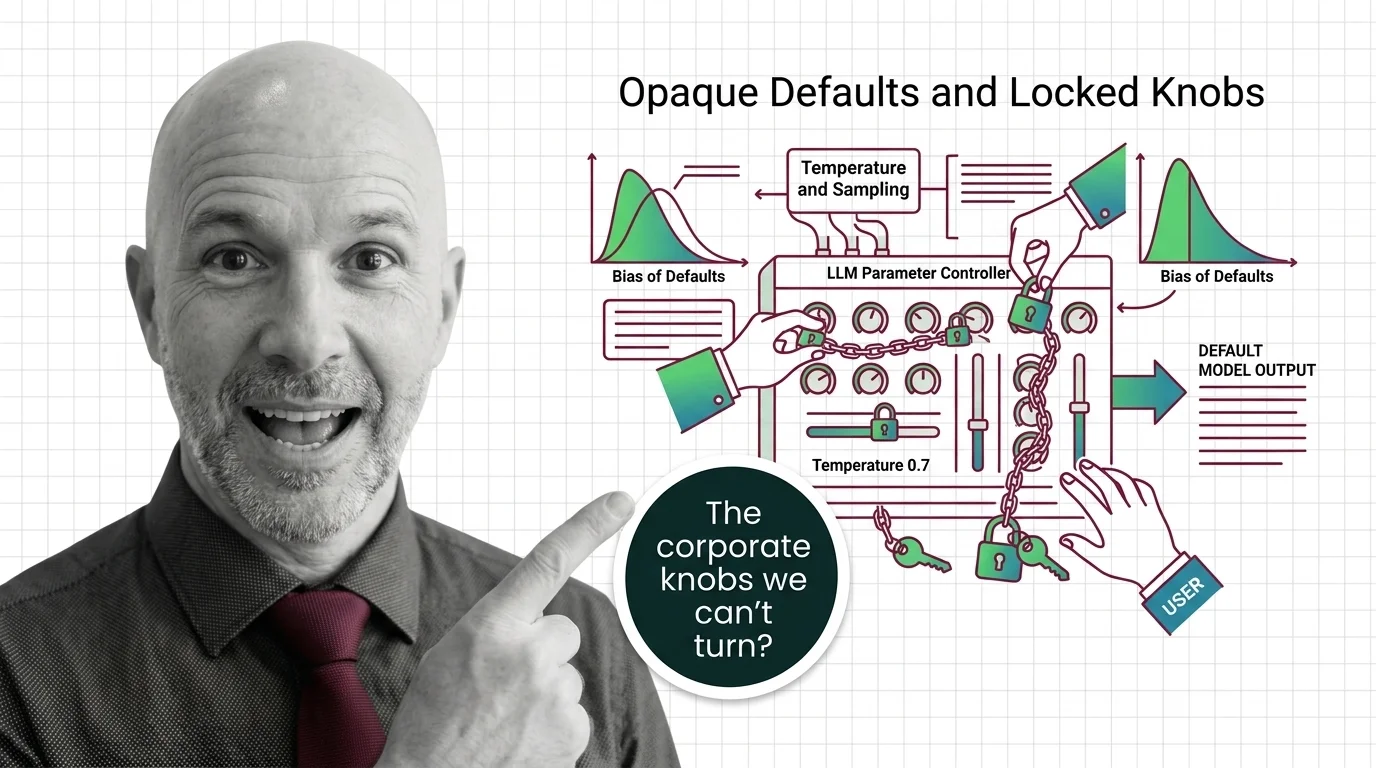
Major LLM providers are locking sampling parameters like temperature and top-p. Explore who controls these defaults, what biases they encode, and why it matters.