Temperature and Sampling
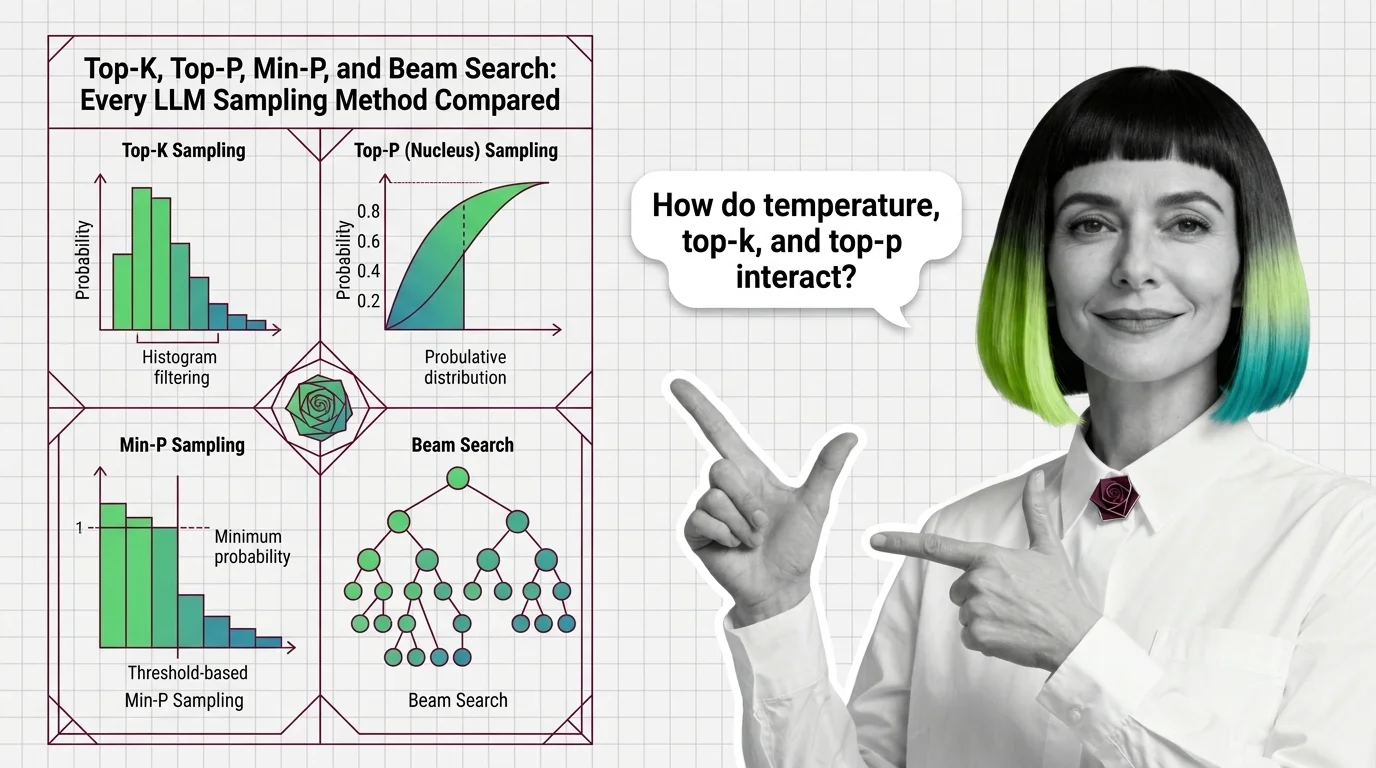
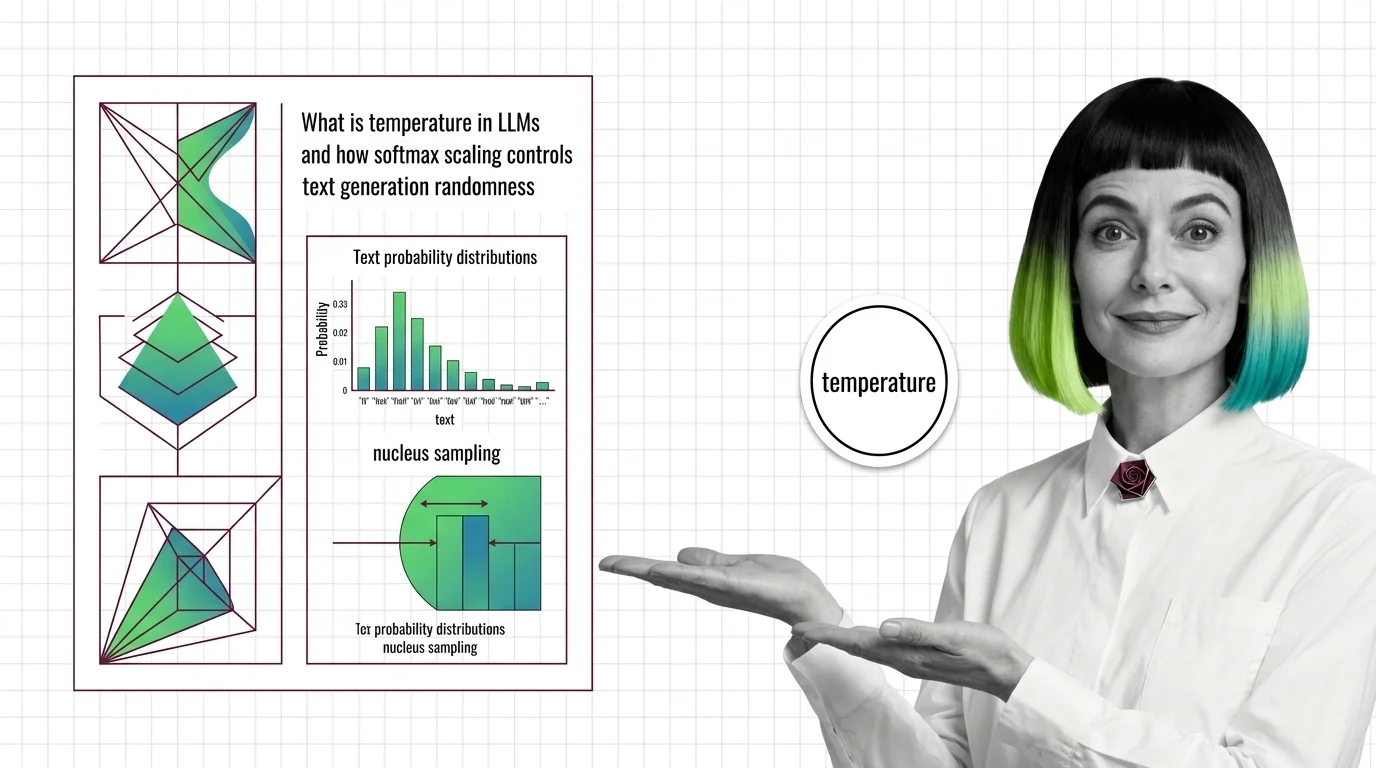
Temperature and sampling are the parameters that control how a large language model selects its next token during text generation. Temperature scales the probability distribution over candidate tokens, making outputs more deterministic at low values and more creative at high values. Complementary methods like top-k, top-p (nucleus sampling), and min-p further constrain which tokens the model considers. Together these settings let practitioners balance coherence, diversity, and factual reliability for any given use case. Also known as: Sampling Strategies, Decoding Strategies.
Understand the Fundamentals
Temperature and sampling sit at the boundary between a model’s learned knowledge and the text it actually produces. Understanding how probability redistribution works reveals why the same prompt can yield wildly different outputs.
Build with Temperature and Sampling
These guides walk through choosing and configuring temperature, top-p, and min-p across real workloads, from deterministic extraction pipelines to open-ended creative generation.

What's Changing in 2026
Sampling defaults are shifting fast as providers lock parameters, adopt min-p, and move toward adaptive decoding. Knowing what changed and why keeps your configurations from falling behind.
Updated March 2026
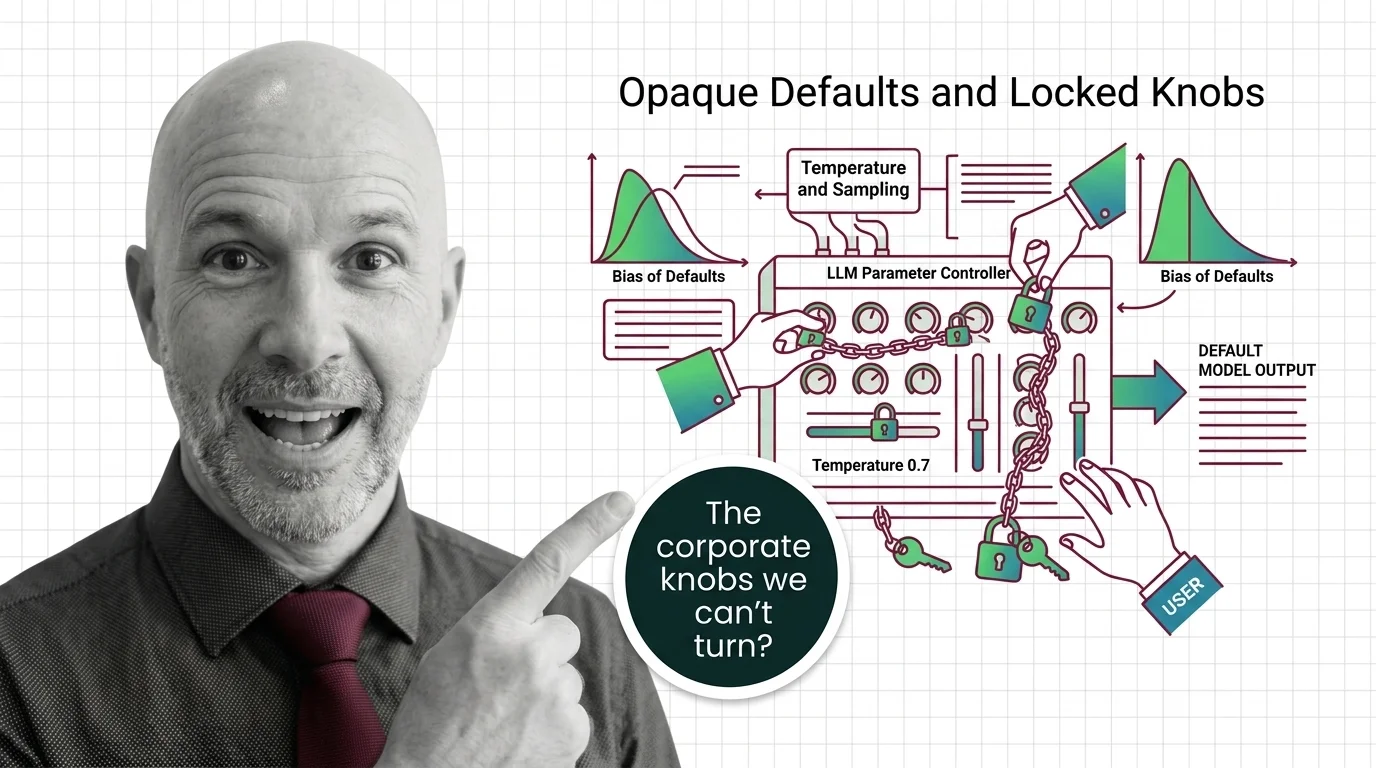
Risks and Considerations
Opaque default settings and locked sampling controls raise questions about user autonomy, output accountability, and the hidden influence of provider-chosen parameters on downstream decisions.